法国人工智能初创公司 Mistral AI 宣布推出其首款大语言模型 Mistral 7B 是一个,号称是迄今为止同规模产品中最强大的语言模型;在 Apache-2.0 许可下开源,可完全免费使用,不受任何限制。
Mistral AI 是一个成立仅六个月的初创公司,于 6 月份筹集了 1.18 亿美元的巨额种子轮资金,据称是欧洲历史上最大的种子轮融资。Mistral 7B 是一个拥有 73 亿参数的模型。该公司声称在涵盖一系列任务的基准测试中,Mistral 7B 的表现均显著优于 Llama 2 7B 和 13B,并且与 Llama 34B 相当。
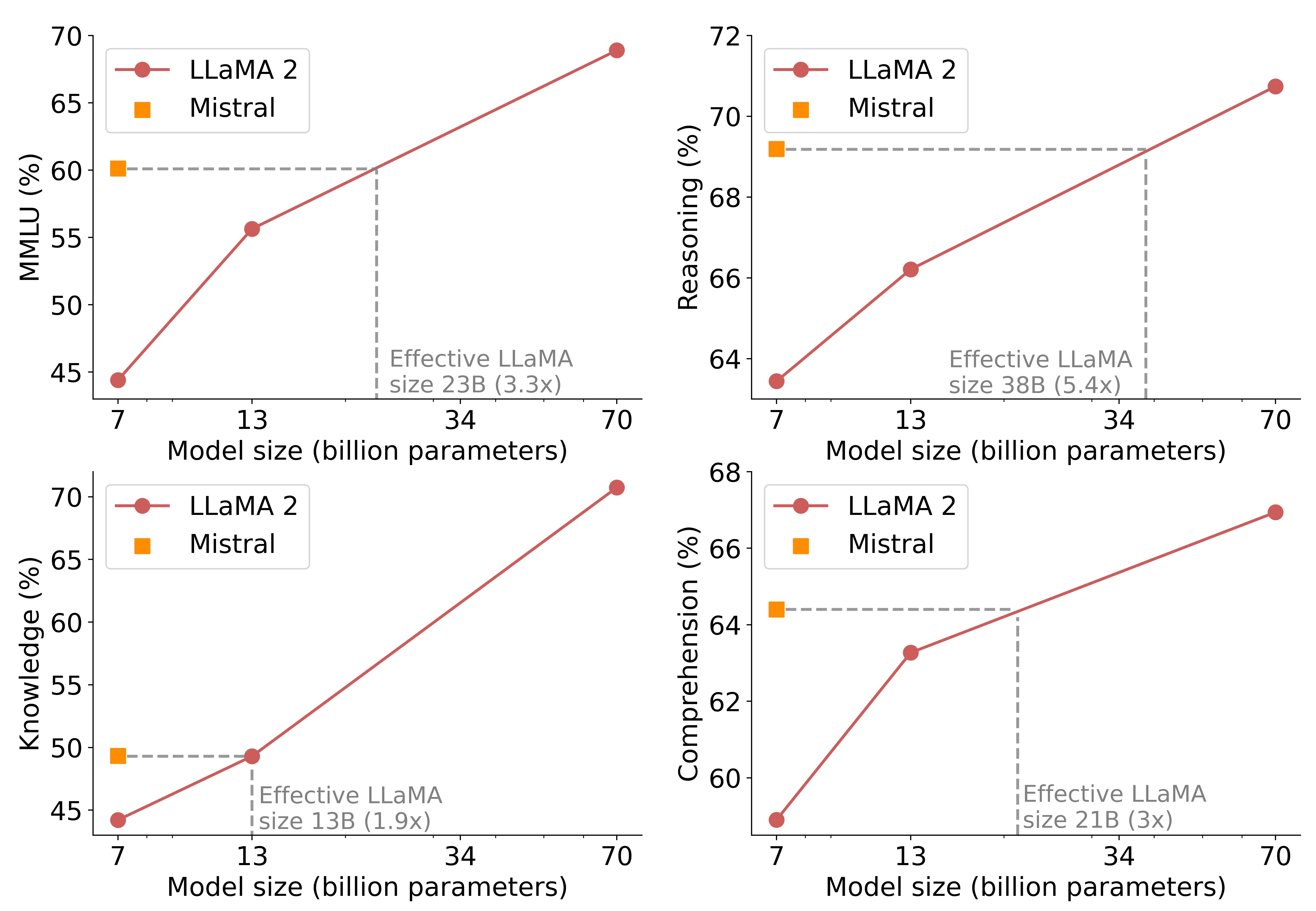
在涵盖数学、美国历史、计算机科学、法律等 57 个科目的大规模多任务语言理解 (MMLU) 测试中,Mistral 7B 模型的准确率为 60.1%,Llama 2 7B 和 13B 的准确率略高于分别为 44.4% 和 55.6%。
在常识推理和阅读理解测试中,Mistral 7B 的准确率也超过了两个 Llama 模型。在世界知识测试中,Llama 2 13B 与 Mistral 7B 不相上下,Mistral 称这可能是由于模型的参数数量有限,限制了它可以压缩的知识量。
唯一 Llama 2 13B 和 Mistral 7B 不相上下的领域则是世界知识测试,Mistral 声称“这可能是由于 Mistral 7B 的参数数量有限,从而限制了其可压缩的知识量。”
在编码任务方面,虽然 Mistral 称 Mistral 7B 的性能大为提高;但基准测试结果表明,它仍然没有超过经过微调的 CodeLlama 7B。在 0-shot Humaneval 和 3-shot MBPP 测试中,CodeLlama 7B 的准确率分别为 31.1% 和 52.5%,Mistral 7B 则分别为 30.5% 和 47.5%。

Mistral AI 表示,Mistral 7B 使用了 Grouped-query attention (GQA) 实现更快的推理,并使用 Sliding Window Attention (SWA) 以较小的成本处理更长的序列。
“Mistral 7B 采用了 SWA,其中每一层都关注先前的 4096 个隐藏状态。主要改进以及最初研究的原因是 O(sliding_window.seq_len) 的线性计算成本。在实际应用中,对 FlashAttention 和 xFormers 所做的更改使得在序列长度为 16k 且窗口为 4k 的情况下,速度提高了 2 倍。”
此外,该公司还计划在这项工作的基础上发布一个更大的模型,能够更好地推理并支持多种语言,预计将于 2024 年亮相。
更多详情可查看官方公告。