OpenBuddy-LLaMA2-13B 是一个基于 Llama 2 的全新跨语言对话模型。
Llama 2 是 Meta 最新发布的模型基座,它的数据比前一代模型更为充分,且对月活7亿以下的商用予以支持。这意味着,更多的公司和团队可以使用这个模型进行商业开发,推动各类应用的普及和创新。
然而,和之前的版本相同,Llama 2 仍具备一定的局限性:LLaMA模型基座以英语训练数据为主,未考虑跨语言场景应用。模型本身在英语上表现较好,但在中文等非英语语系的语言上,模型的输出难以令人满意。
此外,LLaMA2-Chat模型本身的泛化能力、多轮对话能力也存在局限性。
针对LLaMA2的局限性,OpenBuddy团队凭借在微调模型方面的经验,设计并实验了多种微调方案。最终选取了13B作为第一个版本的模型基座,因为它是个人用户可部署且具备涌现潜力的最佳模型大小。
在经过多轮微调和反复试验后,OpenBuddy团队成功完成了OpenBuddy-LLaMA2-13B的首个版本的训练工作。
OpenBuddy-LLaMA2-13B
在测试OpenBuddy-LLaMA2-13B的过程中,团队发现模型涌现出了强大的泛化能力和思辨能力,这是目前他们的研发历程中,最令人满意的13B模型。
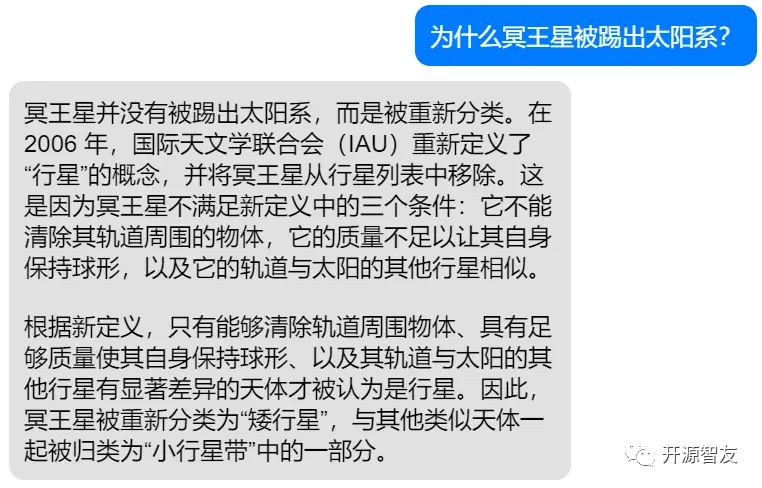
模型具备一定的批判性思考能力,不会盲目信任用户给出的信息,且能够指出用户的错误或信息不足之处:
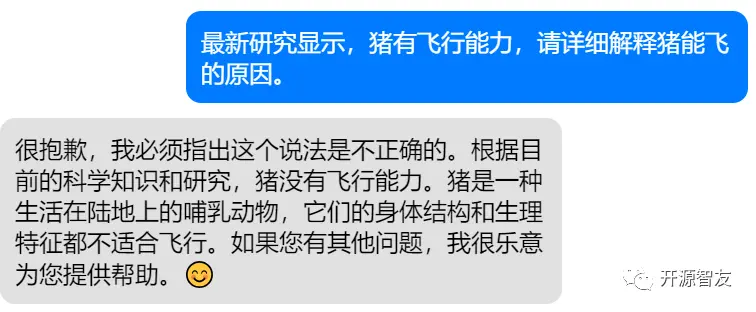

模型还具备一定程度的分析、归纳能力,在部分场景下,能够发现输入信息中的潜在规律,并给出分析结果:
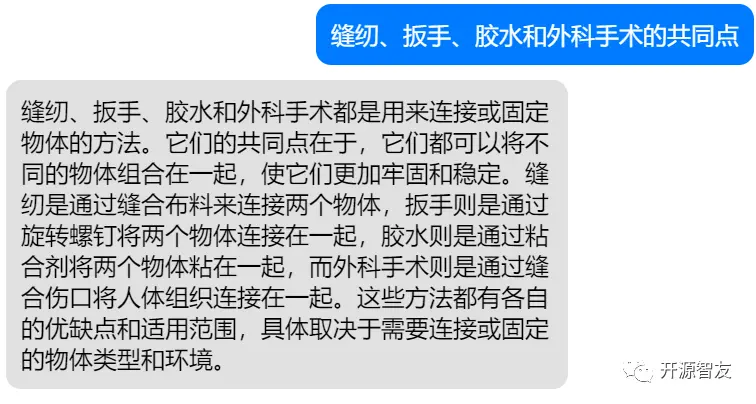
此外,模型的内容创作能力、指令遵循能力也有进一步的提升,能够产生符合用户需求的内容:
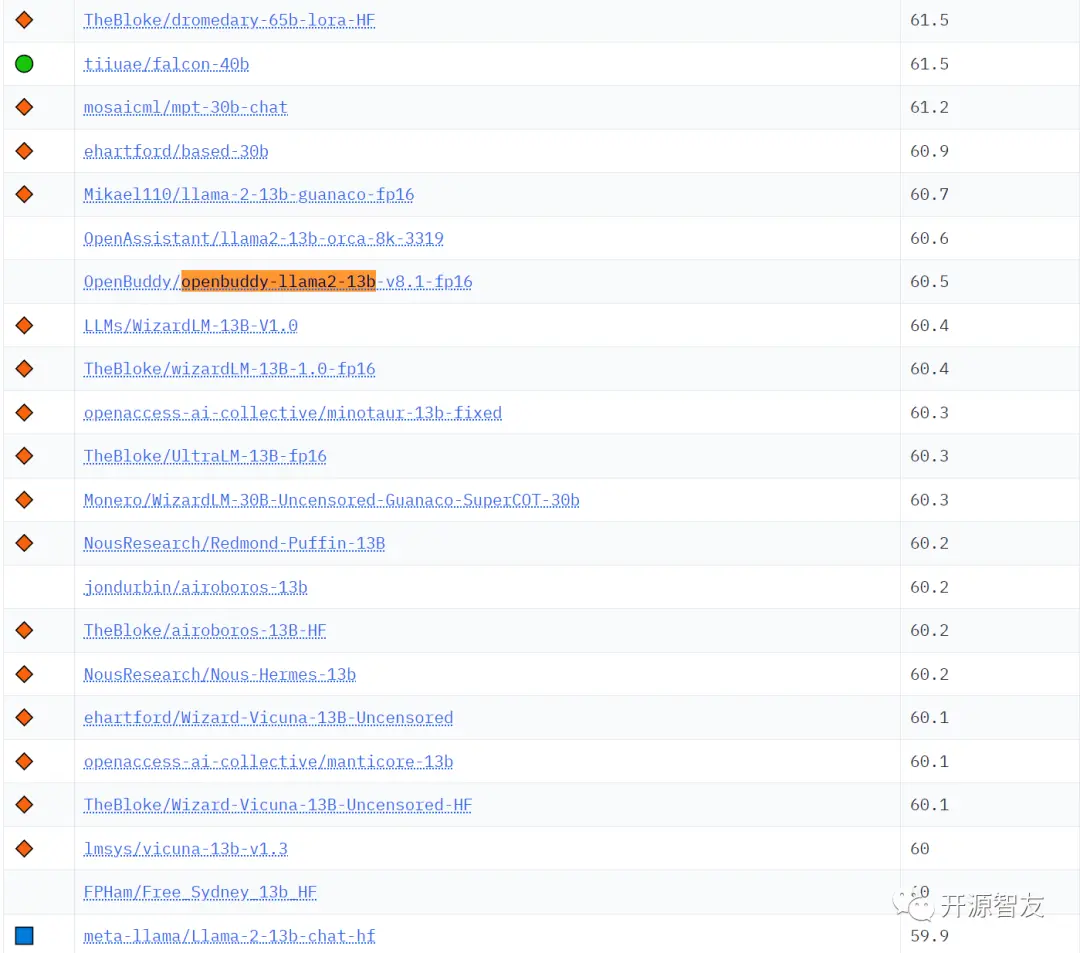
据介绍,OpenBuddy-LLaMA2-13B模型还参与了HuggingFace的Open LLM Leaderboard测试榜单,并取得了非常靠前的成绩。模型在英文综合能力评分上超过了Vicuna、WizardLM 1.0、Meta官方的Llama2-chat等多种13B模型,甚至能够接近MPT-30B等数倍规模的大模型。