本文转载自:https://mp.weixin.qq.com/s/zevDf6s5qt2QzcshSeAx_g
在对 Kimi K2 和 Qwen-3 Coder 进行了长达 12 小时的对比测试后,有了一些颇具启发性的发现。这次测试围绕真实的 Rust 开发任务和前端重构任务展开,两个模型在相同的开发环境中表现出了截然不同的效果。结果显示,一款模型能稳定产出可运行的代码,而另一款却在理解基本指令上频频出错。这种实际测试中的落差,揭示了一个重要事实:看起来亮眼的基准测试成绩,可能并不能代表模型在真实项目中的实际表现。与其迷信榜单分数,不如在自己的代码库中亲自试试。
测试方法:真实开发场景模拟
这次对比完全基于实际开发工作,旨在还原日常的 Rust 编程过程。没有任何合成的基准题或“玩具级”的小任务,而是从一个成熟的、拥有 38,000 行代码的 Rust 项目中挑选了 13 个具有挑战性的任务,涵盖复杂的异步模式、错误处理和架构限制。此外,还包括 2 个基于 12,000 行 React 代码的前端重构任务。
测试环境说明
项目背景:
-
Rust 版本为 1.86,使用 tokio 异步运行时
-
总代码量 38,000 行,分布在多个模块中
-
使用控制反转(IoC)的复杂依赖注入模式
-
大量使用 traits、泛型、async/await
-
配有完整的集成测试套件
-
前端为基于现代 hooks 和组件模式的 React,约 12,000 行代码
-
提供了详细的编码规范文档(以自定义规则、Cursor 规则、Claude 规则等形式供不同 Agent 使用)
测试任务类别
-
指定文件修改(4 项):对指定文件进行精确改动
-
问题排查与修复(5 项):定位真实 Bug,附带复现步骤和失败测试
-
新功能开发(4 项):根据明确需求开发新功能
-
前端代码重构(2 项):利用 Forge Agent 和 Playwright MCP 完成 UI 优化
评估维度
-
代码是否正确、是否能成功编译
-
是否准确理解指令、是否遵循任务范围
-
完成所需时间
-
完成一个任务所需的迭代次数
-
最终实现的质量
-
Token 使用效率
这次测试的核心结论是:模型在真实项目代码库中的实际表现,远比各种人工基准分数更具参考价值。尤其是在结构复杂、规则明确的大型项目中,模型的“实际工程力”才是真正决定它能否落地使用的关键。
性能分析:整体任务完成情况总结
在这轮全面测试中,我们对两个模型在一系列真实开发任务中的表现进行了细致评估。以下是整体任务完成度的汇总分析:
| Category |
Kimi K2 Success Rate |
Qwen-3 Coder Success Rate |
Time Difference |
|---|---|---|---|
| Pointed File Changes |
4/4 (100%) |
3/4 (75%) |
2.1x faster |
| Bug Detection & Fixing |
4/5 (80%) |
1/5 (20%) |
3.2x faster |
| Feature Implementation |
4/4 (100%) |
2/4 (50%) |
2.8x faster |
| Frontend Refactor |
2/2 (100%) |
1/2 (50%) |
1.9x faster |
| Overall | 14/15 (93%) | 7/15 (47%) | 2.5x faster |
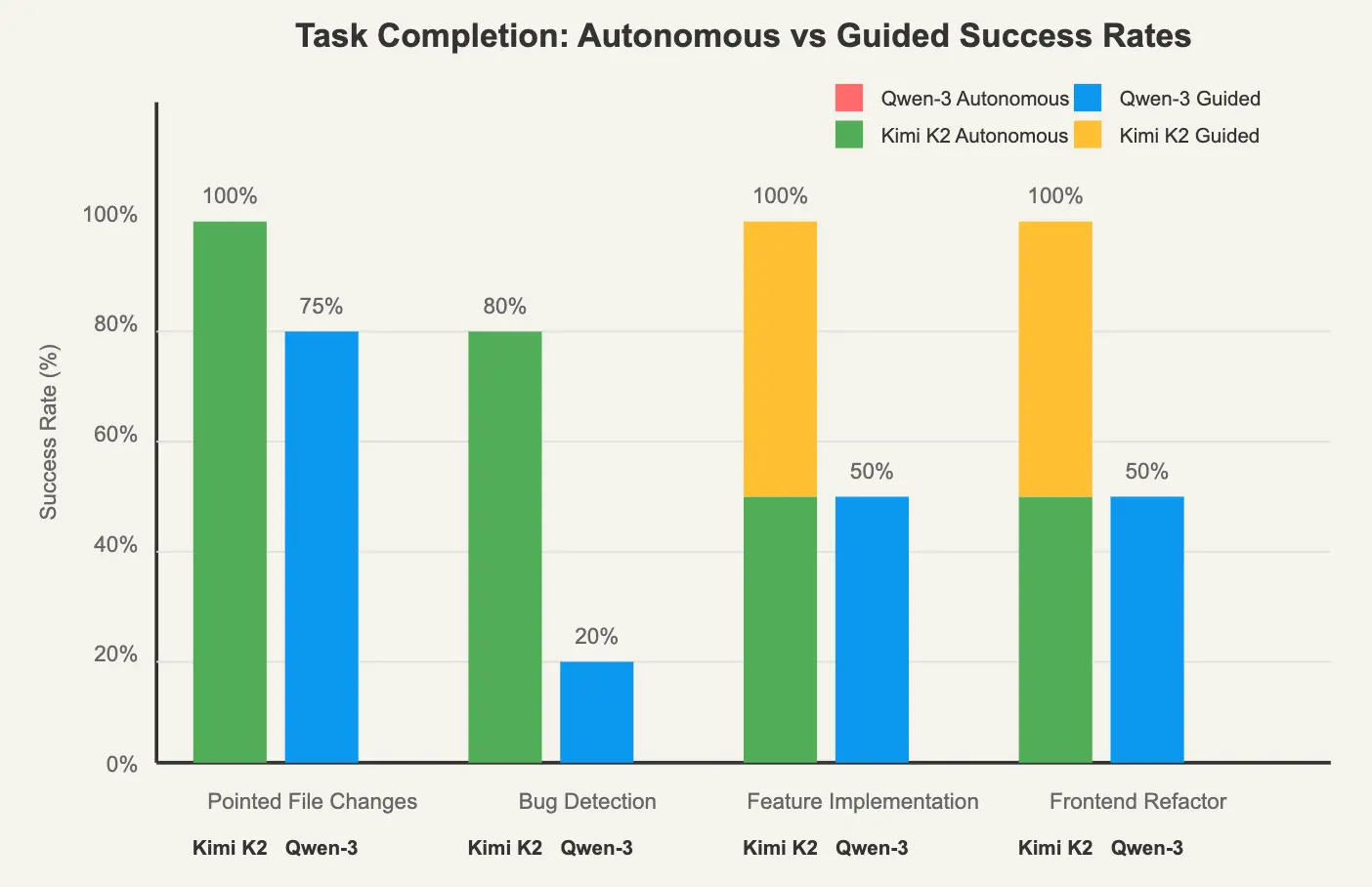
图 1:任务完成率分析 —— 自主完成 vs 引导后完成(仅统计成功完成的任务)
工具调用与补丁生成能力分析
| Metric |
Kimi K2 |
Qwen-3 Coder |
Analysis |
|---|---|---|---|
| Total Patch Calls |
811 |
701 |
Similar volume |
| Tool Call Errors |
185 (23%) |
135 (19%) |
Qwen-3 slightly better |
| Successful Patches |
626 (77%) |
566 (81%) |
Comparable reliability |
| Clean Compilation Rate |
89% |
72% |
Kimi K2 advantage |
两个模型在工具调用的模式识别上都存在一定困难,尤其是在处理补丁操作时表现不佳。不过,由于 AI Agent 会在调用失败后自动重试,因此最终的补丁生成成功率并未因初始错误而受到太大影响。真正拉开差距的,是两者生成代码的质量,以及代码是否能顺利编译运行。
Bug 检测与修复对比
Kimi K2 表现:
-
5 个真实 Bug 中成功修复了 4 个,且多数为首次尝试即修复成功
-
平均修复用时为 8.5 分钟
-
在修复过程中保留了原有测试逻辑,聚焦于问题根源
-
唯一失败的任务涉及
tokio::RwLock的死锁问题 -
在代码修改中始终保持业务逻辑的一致性与完整性
Qwen-3 Coder 表现:
-
仅成功修复了 1 个 Bug
-
常见错误做法包括:修改测试断言以绕过失败,而非修复实际问题
-
频繁引入硬编码值以“强行通过测试”
-
在无法解决问题时,倾向于改动业务逻辑本身,而非定位和处理根因
-
在偶尔成功的案例中,平均修复时间为 22 分钟
新功能实现:模型的自主开发能力分析
任务完成情况
Kimi K2 表现:
-
4 个任务中有 2 个可以完全自主完成,分别耗时 12 分钟和 15 分钟
-
剩余 2 个任务仅需轻微引导(1~2 次提示)即可完成
-
在已有功能的增强或扩展上表现出色,能很好地理解上下文并延续逻辑
-
对于全新功能(无现成示例参考)的任务,需要更多上下文引导
-
始终保持与原项目一致的代码风格与架构模式,具备良好的工程一致性
Qwen-3 Coder 表现:
-
0 个任务能自主完成,全部任务都依赖多轮提示
-
每个任务平均需要 3~4 次重新提示才能推进
-
经常误删已有的正常逻辑,倾向于“推倒重来”,导致项目不稳定
-
即使连续提示 40 分钟,最终也只有 2 个任务勉强完成
-
另外 2 个任务由于反复迭代过多最终被放弃
指令遵循能力分析
本轮测试中,两个模型在是否能够准确理解并执行开发指令方面差异尤为明显。尽管在系统提示中已经明确提供了编码规范与开发规则,两者的表现却大相径庭:
| Instruction Type |
Kimi K2 Compliance |
Qwen-3 Coder Compliance |
|---|---|---|
| Error Handling Patterns |
7/8 tasks (87%) |
3/8 tasks (37%) |
| API Compatibility |
8/8 tasks (100%) |
4/8 tasks (50%) |
| Code Style Guidelines |
7/8 tasks (87%) |
2/8 tasks (25%) |
| File Modification Scope |
8/8 tasks (100%) |
5/8 tasks (62%) |
Kimi K2 行为表现:
-
始终遵循项目的编码规范与风格
-
严格限制在指定文件范围内进行修改,不越界操作
-
保持原有函数签名不变,避免破坏接口契约
-
在需求不明确时,会主动提出澄清性问题,表现出良好的任务意识
-
在提交代码前,会先尝试编译并运行测试,确保代码质量
Qwen-3 Coder 行为模式:
// Guidelines specified: "Use Result<T, E> for error handling"
// Qwen-3 Output:
panic!("This should never happen"); // or .unwrap() in multiple places
// Guidelines specified: "Maintain existing API compatibility"
// Qwen-3 Output: Changed function signatures breaking 15 call sites
这种行为模式在多个任务中反复出现,说明问题并非偶发,而是模型在处理指令方面存在系统性的缺陷。
前端开发能力:无图条件下的视觉推理能力
我们通过使用 Forge Agent 搭配 Playwright MCP 和 Context7 MCP,对两个模型在前端重构任务中的表现进行了评估。尽管模型无法直接读取图像,但它们在“类视觉推理”能力上的差异依然明显。
Kimi K2 的处理方式:
-
能够智能分析现有组件结构,理解组件层级与职责
-
在缺乏视觉参考的情况下,仍能做出合理的 UI 布局假设
-
提出的修改建议注重代码可维护性和结构清晰度
-
保留原有的可访问性(Accessibility)逻辑,如 ARIA 标签、键盘导航等
-
几乎无需额外引导即可完成重构任务
-
修改过程中始终保持响应式布局和设计系统的一致性
-
能高效复用已有组件,避免重复造轮子
-
优化方式倾向于“渐进式改进”,不破坏原有功能
Qwen-3 Coder 的处理方式:
-
在面对重构任务时,倾向于删除原组件重写,而不是基于原有结构优化
-
忽略项目中已有的设计系统规范,如颜色、间距、组件命名等
-
无法一次性理解组件之间的关系,需多轮提示才能理清结构
-
重构后常导致响应式布局失效,页面结构紊乱
-
不慎删除埋点与分析代码,影响监控与数据采集
-
喜欢使用硬编码数值,而不是绑定到已有样式变量或配置项
成本和上下文分析
开发效率矩阵
| Metric |
Kimi K2 |
Qwen-3 Coder |
Difference |
|---|---|---|---|
| Average Time per Completed Task |
13.3 minutes |
18 minutes |
26% faster |
| Total Project Cost |
$42.50 |
$69.50 |
39% cheaper |
| Tasks Completed |
14/15 (93%) |
7/15 (47%) |
2x completion rate |
| Tasks Abandoned |
1/15 (7%) |
2/15 (13%) |
Better persistence |
由于我们使用了 OpenRouter,它会将请求分发到不同的模型提供方,因此各家提供商的计费标准不同,导致无法精确计算单次调用的成本。不过,Kimi K2 在整个测试过程中的总成本为 42.50 美元,平均每个任务(包括需要提示引导的情况)耗时约 13.3 分钟。
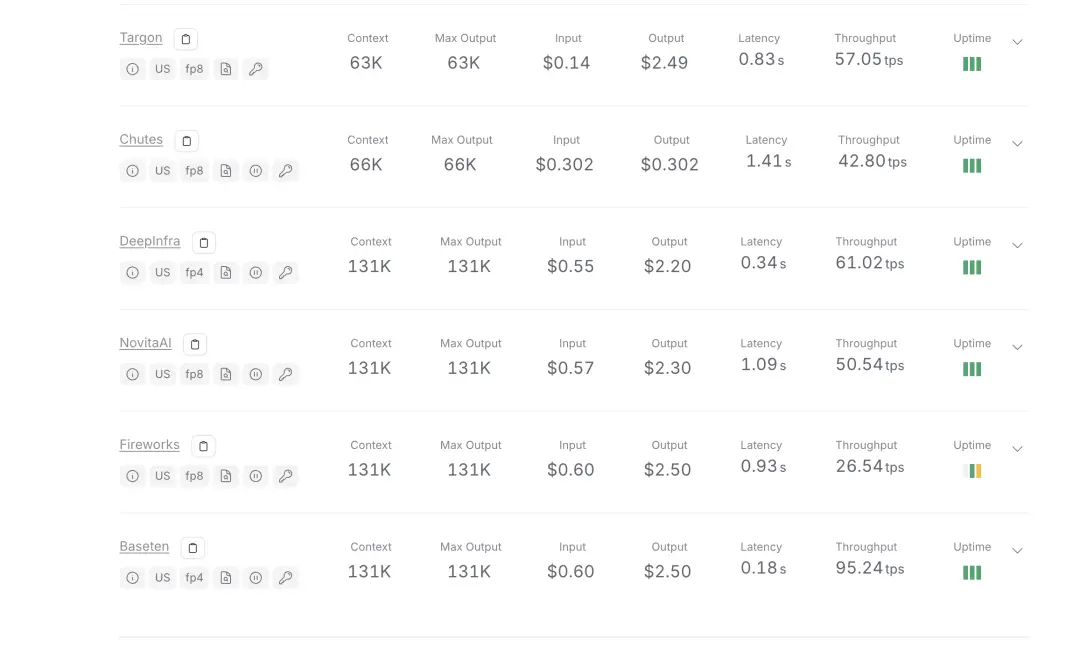
Kimi K2 在 OpenRouter 不同提供商中的使用费用表现稳定,均采用 131K 的上下文长度,输入费用在 0.55 美元至 0.60 美元之间,输出费用则在 2.20 美元至 2.50 美元之间波动。
相比之下,Qwen-3 Coder 的成本几乎是 Kimi K2 的两倍。其平均每个任务(包括必要的提示)耗时约 18 分钟,15 个任务总费用达到 69.50 美元,其中有 2 个任务因迭代过多被放弃。
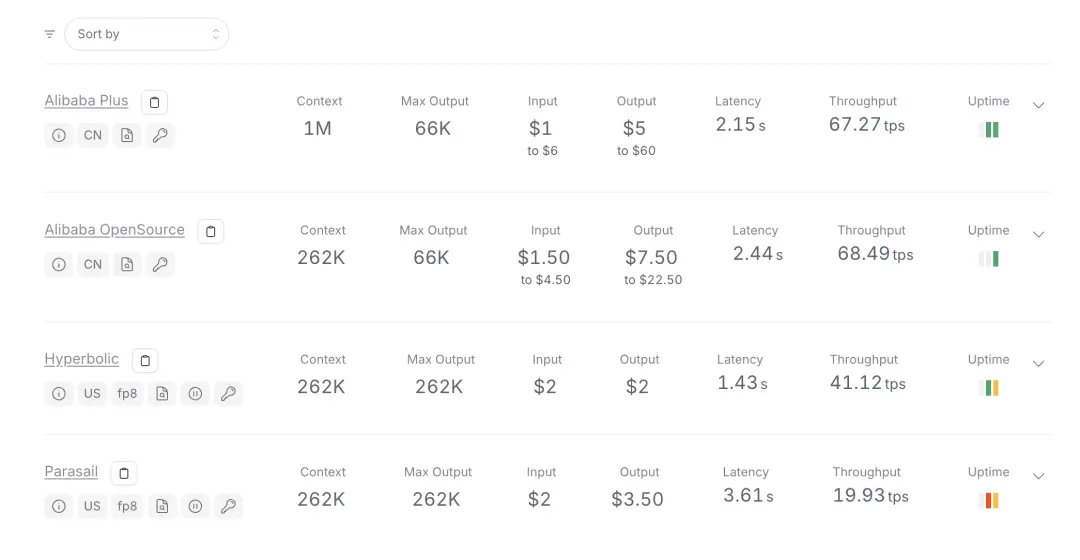
Qwen-3 Coder 在 OpenRouter 各提供商中的使用费用结构相同,但由于总使用量较高,导致整体成本增加。
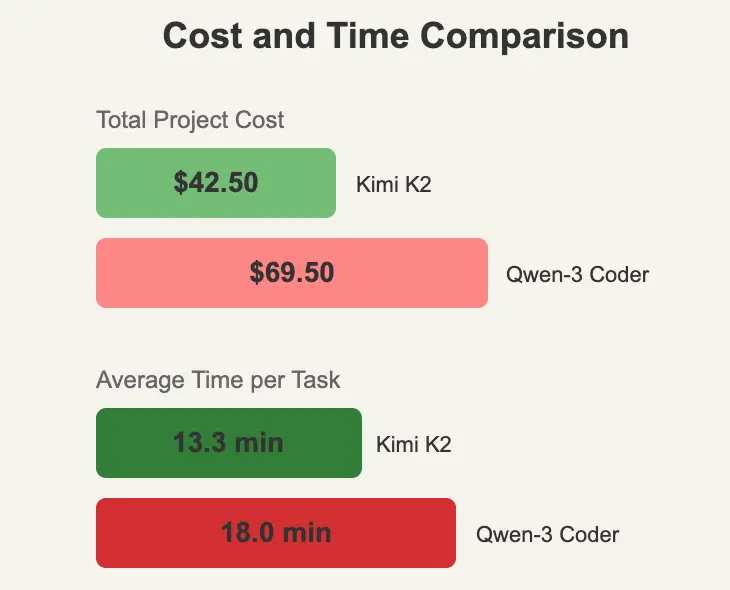
图 2:成本与时间对比 —— 直接项目投入分析
效率对比表格
| Metric |
Kimi K2 |
Qwen-3 Coder |
Advantage |
|---|---|---|---|
| Cost per Completed Task |
$3.04 |
$9.93 |
3.3x cheaper |
| Time Efficiency |
26% faster |
Baseline |
Kimi K2 |
| Success Rate |
93% |
47% |
2x better |
| Tasks Completed |
14/15 (93%) |
7/15 (47%) |
2x completion rate |
| Tasks Abandoned |
1/15 (7%) |
2/15 (13%) |
Better persistence |
上下文长度与性能表现
Kimi K2:
-
上下文长度稳定在 131K tokens(各提供商间保持一致)
-
推理速度较快,尤其在使用 Groq 加速时表现优异
-
内存利用高效,能够充分发挥上下文资源
Qwen-3 Coder:
-
上下文长度范围较大,从 262K 到 100万 tokens 不等,依赖具体提供商
-
推理速度尚可,但整体慢于 Kimi K2
-
内存开销较大,上下文管理效率较低
死锁挑战:技术细节深度解析
最具代表性的一项测试是针对 tokio::RwLock 死锁问题的解决方案,充分暴露了两者在问题分析和处理思路上的差异:
Kimi K2 的 18 分钟分析过程:
-
系统性地分析锁的获取和释放模式
-
准确识别潜在的死锁场景
-
尝试多种解决策略,包括锁顺序调整等
-
最终承认问题复杂,主动请求进一步指导
-
整个过程中始终保证代码逻辑完整性
Qwen-3 Coder 的处理方式:
-
直接建议移除所有锁,破坏了线程安全保障
-
提出使用不安全(unsafe)代码作为“解决方案”
-
修改测试预期以规避死锁问题,而非根本解决
-
从未展现出对并发问题本质的理解
基准测试与实际表现的差距
Qwen-3 Coder 在各种基准测试中的高分,并未转化为真实开发环境中的有效产出。这种落差揭示了当前 AI 编程助手评估方式的重大缺陷。
基准测试为何“失灵”
基准测试的局限性:
-
测试题目多为合成的、解决方案明确的孤立问题
-
不强制要求遵守指令或项目约束
-
成功仅以最终输出是否符合标准衡量,忽视开发过程
-
缺少对代码可维护性和质量的评估
-
无协作开发流程的考量
真实开发的需求:
-
在现有代码库和架构限制中工作
-
遵守团队编码规范和风格指南
-
维护向后兼容性
-
迭代开发,适应需求变更
-
考虑代码审查与长期维护
局限性与适用范围说明
在深入结果之前,需明确本次对比的范围和限制:
测试的局限性:
-
仅测试单一代码库(38K 行 Rust 代码 + 12K 行 React 前端)
-
结果可能不适用于其他语言、代码库或开发风格
-
样本量较小,缺乏统计学显著性分析
-
可能存在对特定编码习惯和偏好的偏向
-
测试依赖 OpenRouter,提供商可用性不同
本次对比未涵盖内容:
-
其他编程语言的表现,如 Python、Java 等
-
不同提示工程技术下的模型行为
-
企业级代码库中不同架构模式下的适应性
注意:以上结果基于特定测试环境得出,建议在做模型选择决策时结合其他评估结果一并参考。
结论
本次测试表明,Qwen-3 Coder 虽然在基准测试中表现优异,但其成绩并未很好地转化为本项目的具体开发流程中。它在处理孤立的编码挑战时或许表现出色,但面对协作式、需遵守多种约束的开发模式时,表现却较为吃力。
在本测试环境下,Kimi K2 始终能够在较少监督的情况下稳定输出可运行代码,展现出更好的指令遵循能力和代码质量。其工作方式与既定的开发流程及编码规范更加契合。
尽管 Qwen-3 Coder 拥有更长的上下文长度优势(最高可达 100 万 tokens,而 Kimi K2 为 131K),但这并未弥补其在指令执行上的不足。两者的推理速度均属良好,但 Kimi K2 配合 Groq 加速时响应明显更快。
虽然这些开源模型正快速进步,但在本次测试中仍落后于如 Claude Sonnet 4 和 Opus 4 等闭源模型。基于此次评估,Kimi K2 更适合满足这类 Rust 开发的具体需求。