知名 AI 技术创业者李沐和其团队 Boson.ai 发布了开源 TTS 语言大模型 Higgs Audio v2,该模型不仅支持文本转语音,还能生成多语言自然多说话人对话、自动调整韵律、使用克隆声音哼唱旋律,甚至同时生成语音和背景音乐 。
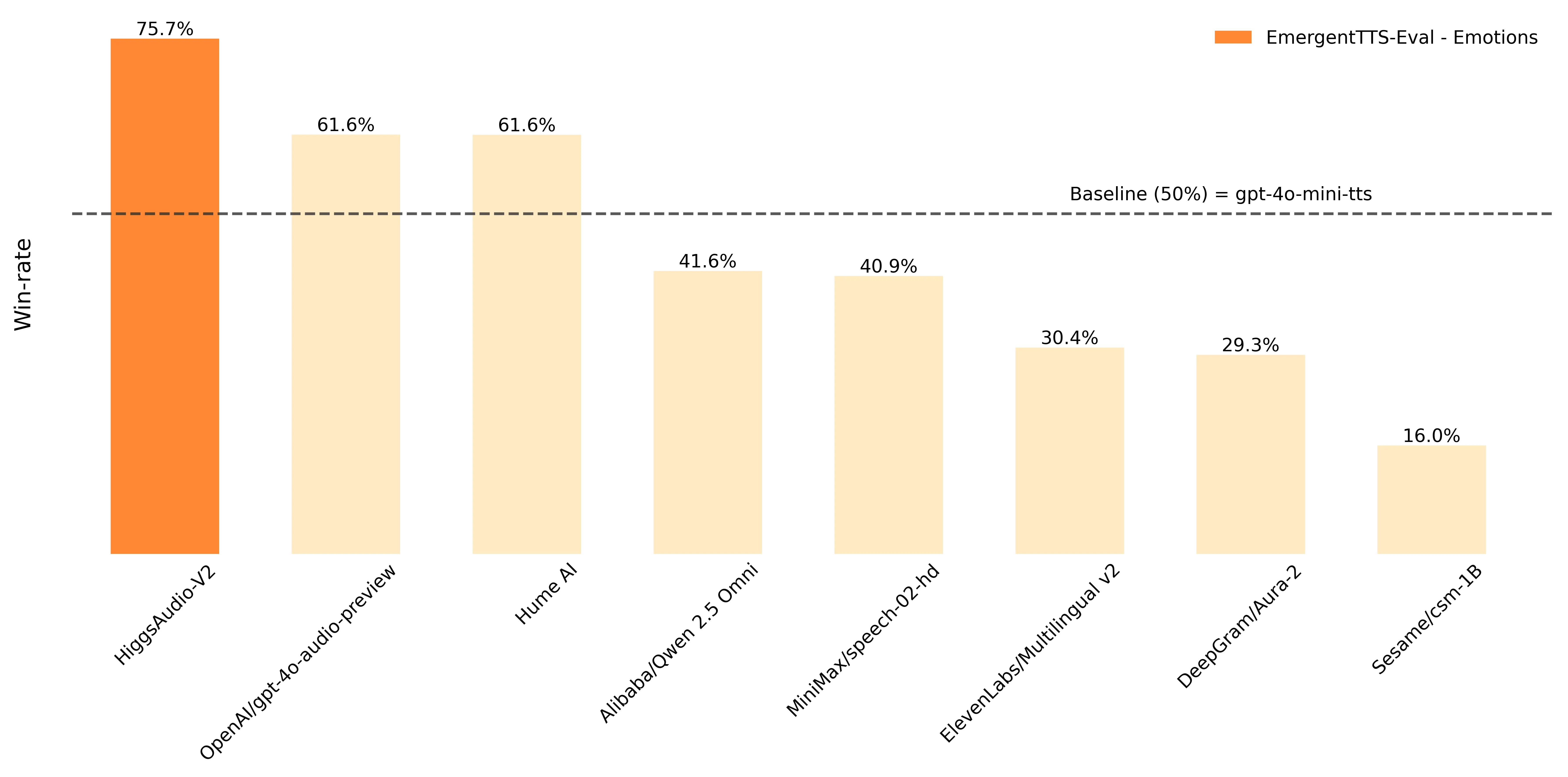
Higgs Audio v2 整合了 1000 万小时语音数据到 LLM 文本训练中,在 EmergentTTS-Eval 基准测试中表现优异(尤其在“情绪”和“问题”类别中,较 GPT-4o-mini-tts 分别高出 75.7% 和 55.7% 的胜率),在传统 TTS 基准测试中也取得了最佳性能。

以下是关于 Higgs Audio V2 的详细介绍:
- 模型特点
- 多模态能力:不仅能处理文本,还能同时理解并生成语音,可完成简单的文本转语音,也能实现更复杂的任务,如写一首歌并唱出来,再加上配乐。
- 独特功能:具备生成多种语言的自然多说话人对话、旁白过程中的自动韵律调整、使用克隆声音进行旋律哼唱以及同时生成语音和背景音乐等能力。
- 性能优势:在emergenttts-eval基准上,相较于其他模型,性能遥遥领先,尤其是在“情绪”和“问题”类别中,相比gpt-4o-mini-tts高出了75.7%和55.7%的胜率。在seed-tts eval和情感语音数据集(esd)等传统tts基准测试中也取得了最佳性能。
- 技术原理
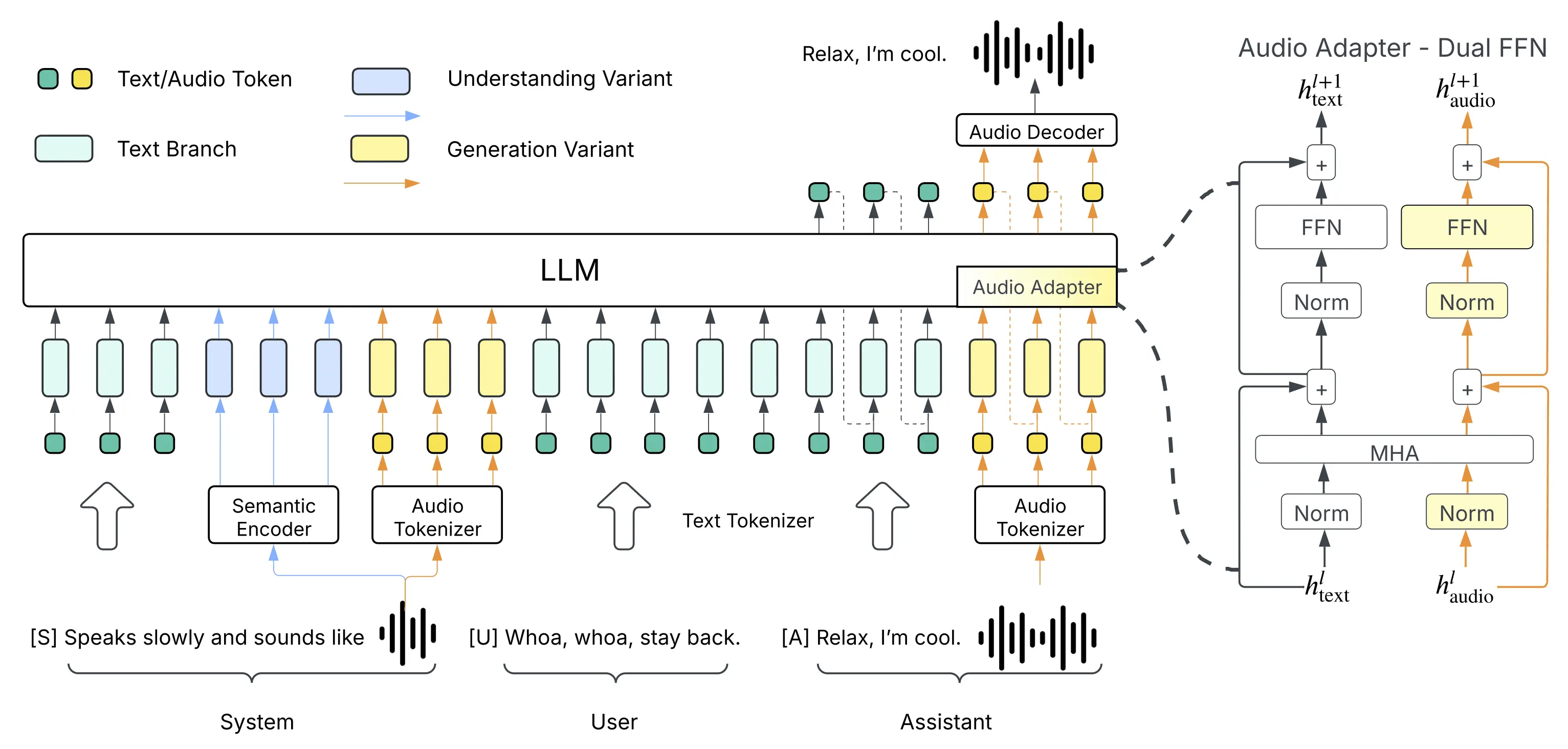
- 数据处理:将语音信号以每秒25帧的速度运行,通过统一的离散化音频分词器,将其表示为长度为10的编号序列,也就是一个个token,以捕获语义和声学特征。
- 模型架构:利用预训练的大型语言模型,将其强大的语言理解、语境感知和推理能力扩展到音频任务。通过在大量的配对文本-音频数据集上端到端地训练大型语言模型,实现了语音和文本的整合。
- 上下文学习:融入了上下文学习,使模型能够快速适应而无需重新训练。通过简单的提示,例如简短的参考音频样本,可以即时进行零样本语音克隆,匹配说话风格。
- 应用场景
- 实时语音聊天:可实现低延迟、理解情绪并表达情绪的自然语音交互,而不仅仅是机械的问答,适用于虚拟主播、实时语音助手等场景。
- 音频内容创作:能够生成自然多说话人对话、旁白等音频内容,为有声读物、互动培训和动态故事讲述等提供支持。
- 语音克隆:可以复制特定人物的声音,用于制作鬼畜视频、虚拟主播等,为娱乐和创意领域提供了新的可能性。
该模型代码已全部开源至 GitHub:https://github.com/boson-ai/higgs-audio,和 Hugging Face(https://huggingface.co/bosonai/higgs-audio-v2-generation-3B-base),支持本地安装(需 GPU 版 PyTorch 或使用 Docker 简化安装)。