Meta 刚刚开源了号称是编程领域“最先进的大语言模型”——Code Llama,可根据代码和自然语言提示生成代码和有关代码的自然语言,支持多种主流编程语言,包括 Python、C++、Java、PHP、Typescript (Javascript)、C# 和 Bash。
Code Llama 完全免费,可用于研究和商业用途,并已在 GitHub 发布:https://github.com/facebookresearch/codellama。
Code Llama 基于 Llama 2 大语言模型打造,提供了三种模型:
- Code Llama - 基础代码模型
- Code Llama - Python - 专门针对 Python 进行优化
- Code Llama - Instruct - 专门用于理解自然语言指令
它们具有开放式模型中领先的性能、填充能力、对大型输入上下文的支持以及用于编程任务的零指令跟随能力。所有模型都是基于 16k 标记序列进行训练,并在最多 100k 标记输入上显示出改进。
运行示例
- 根据自然语言生成代码
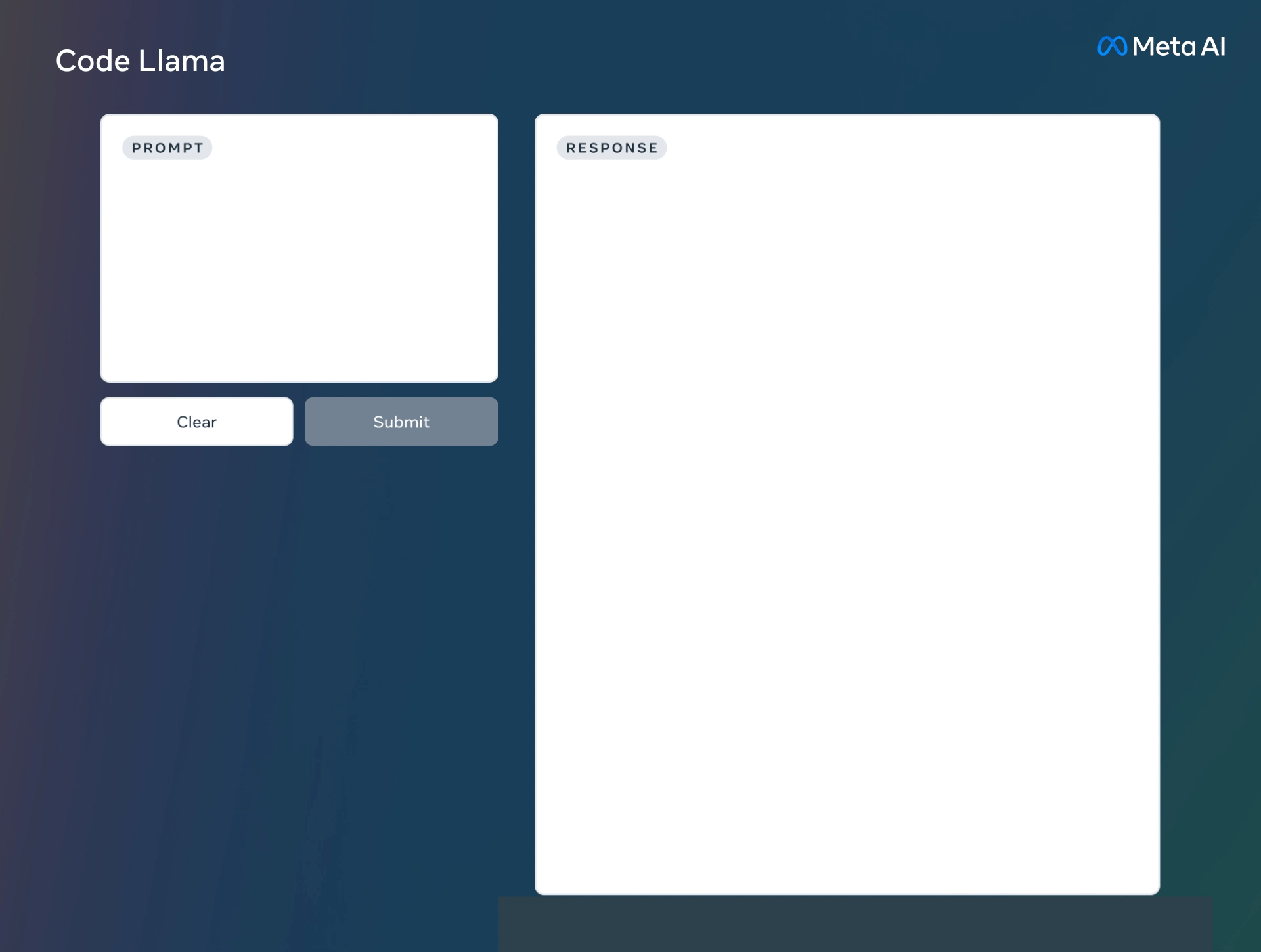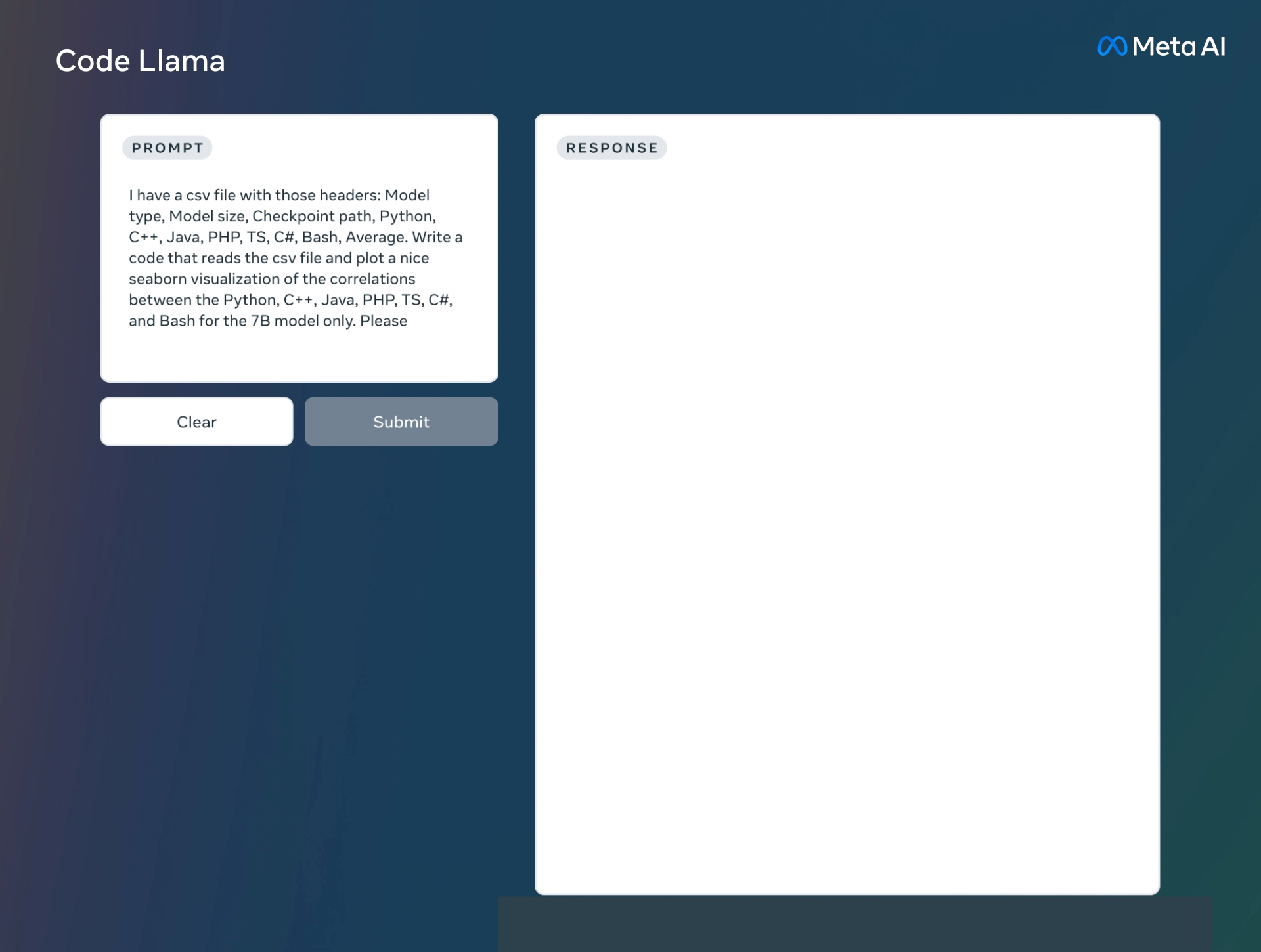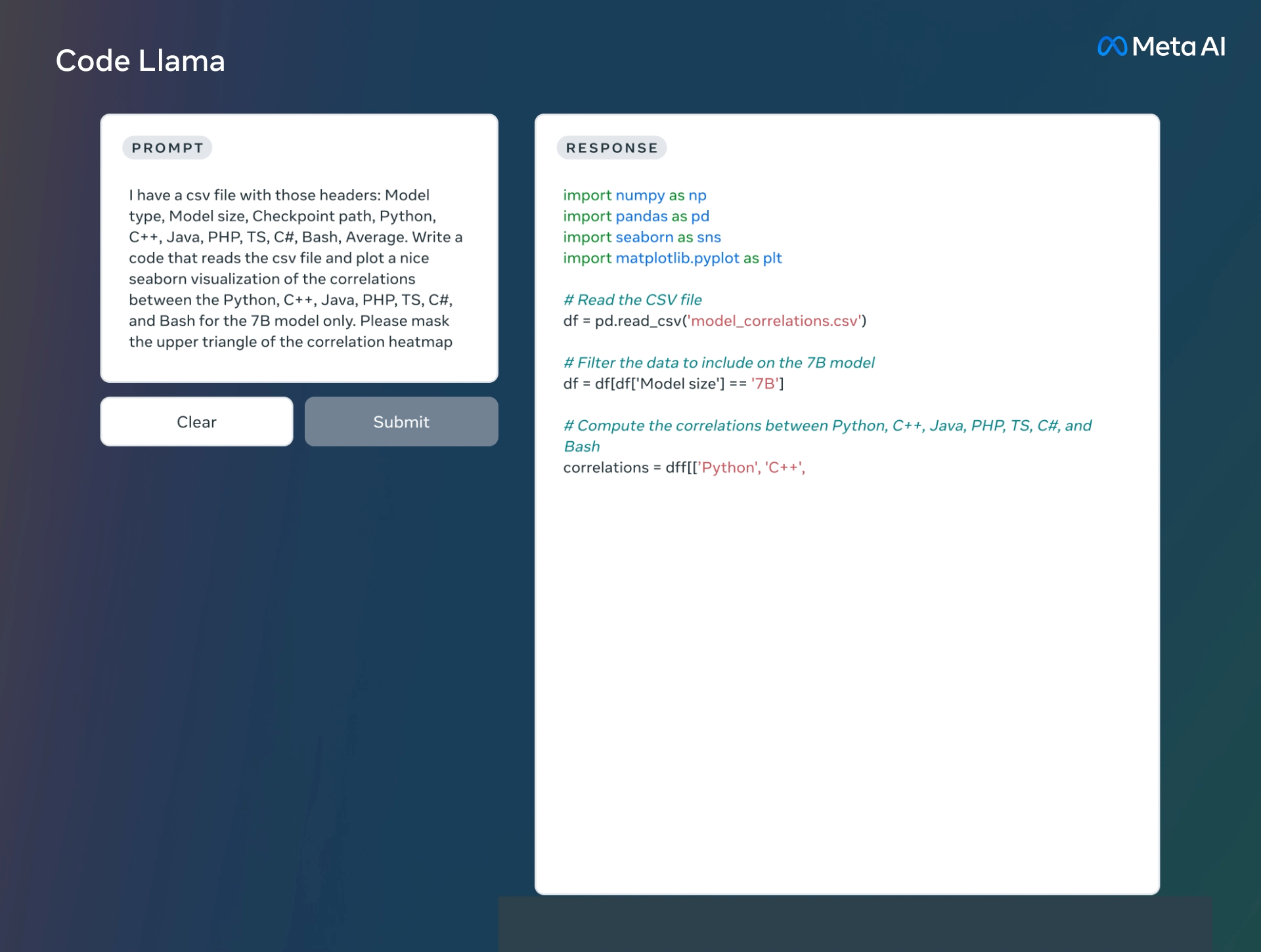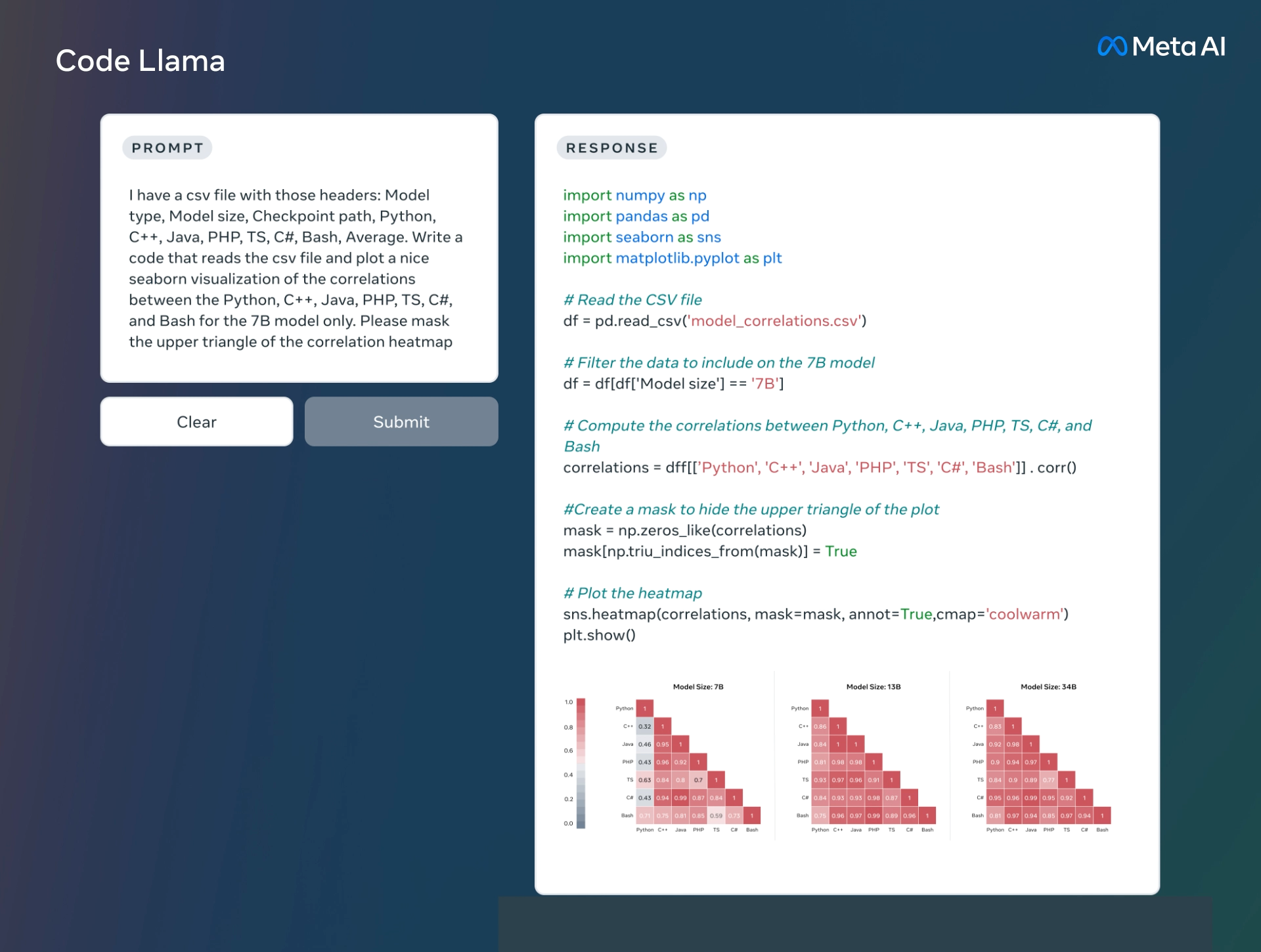
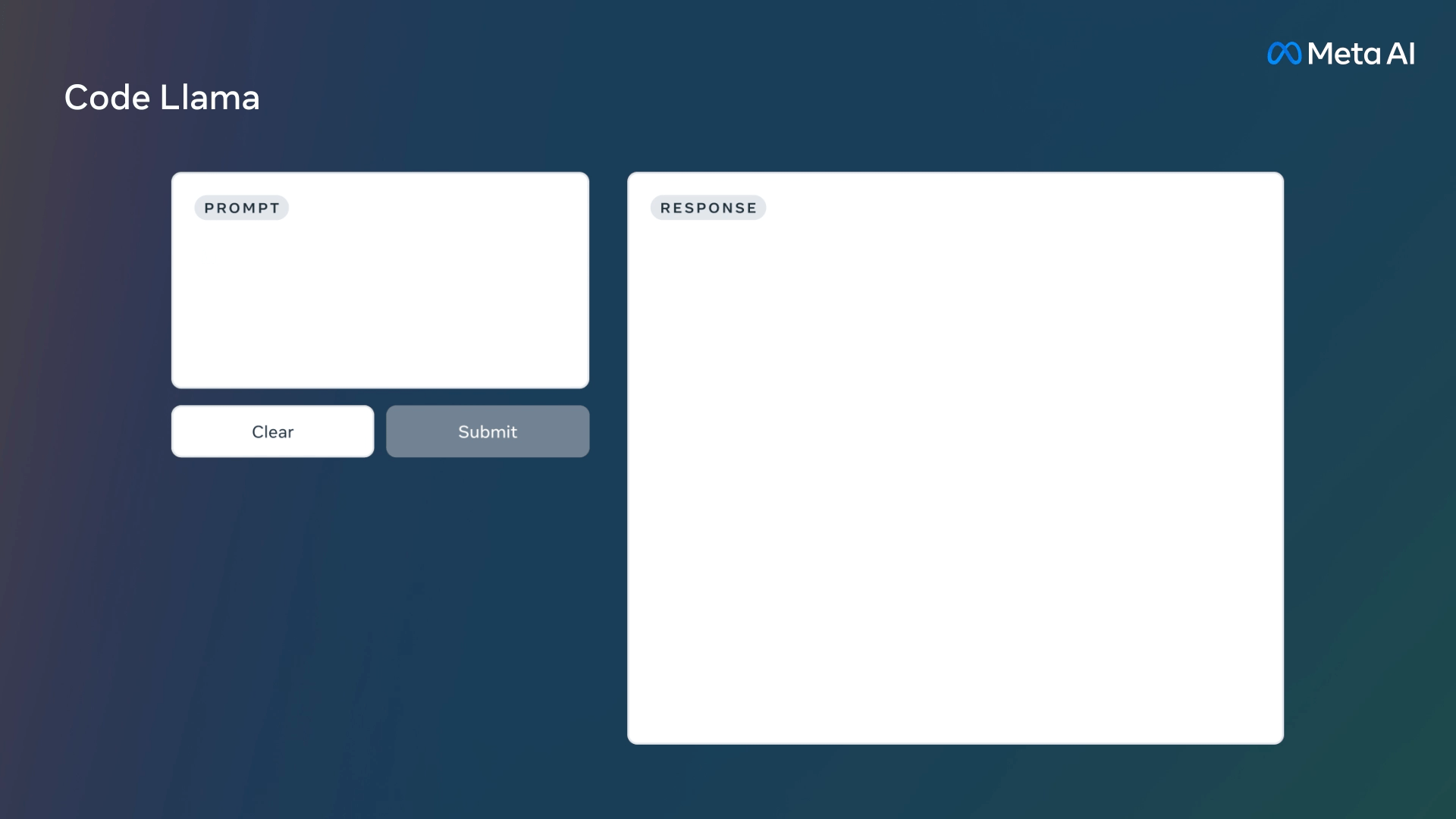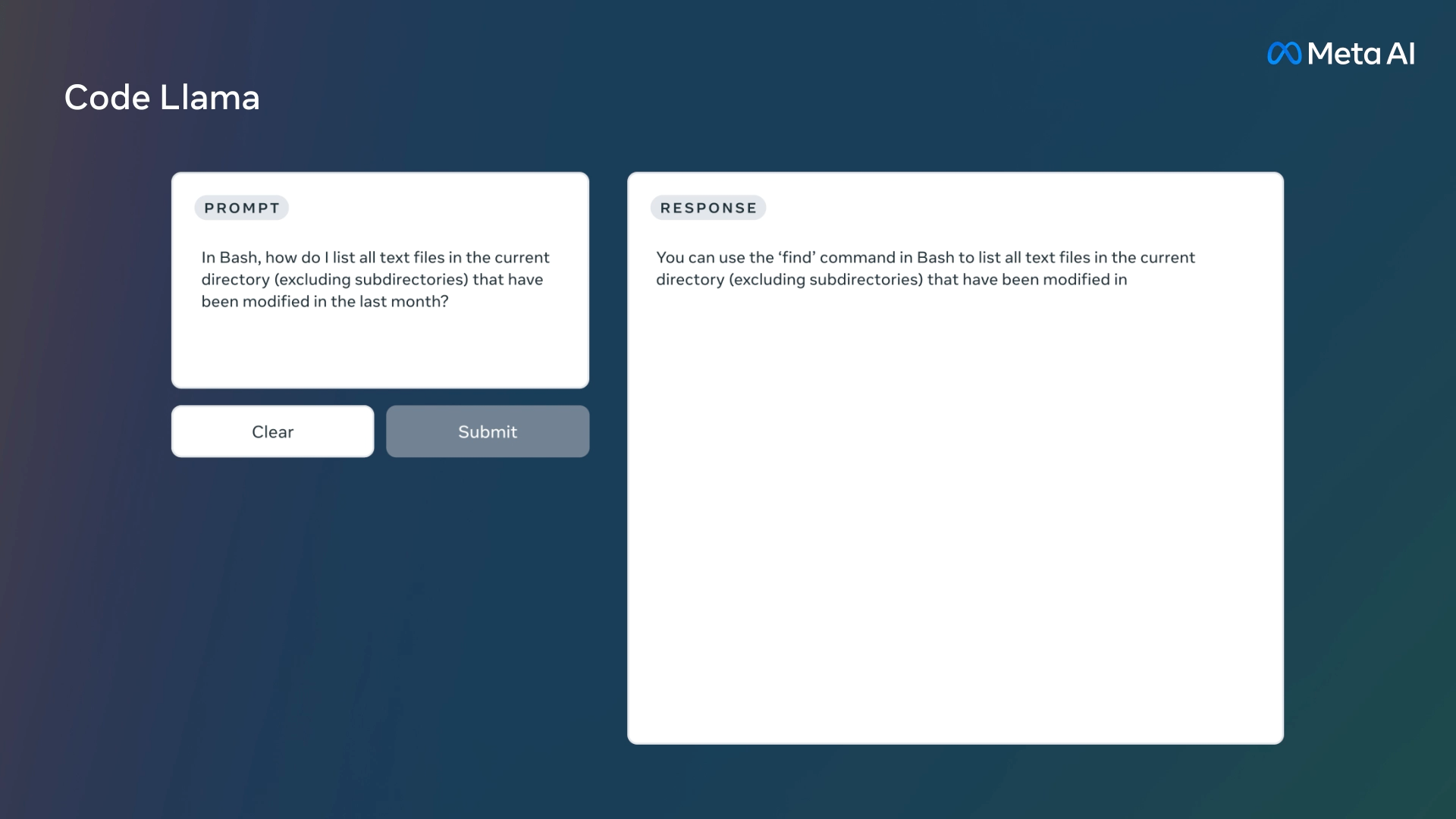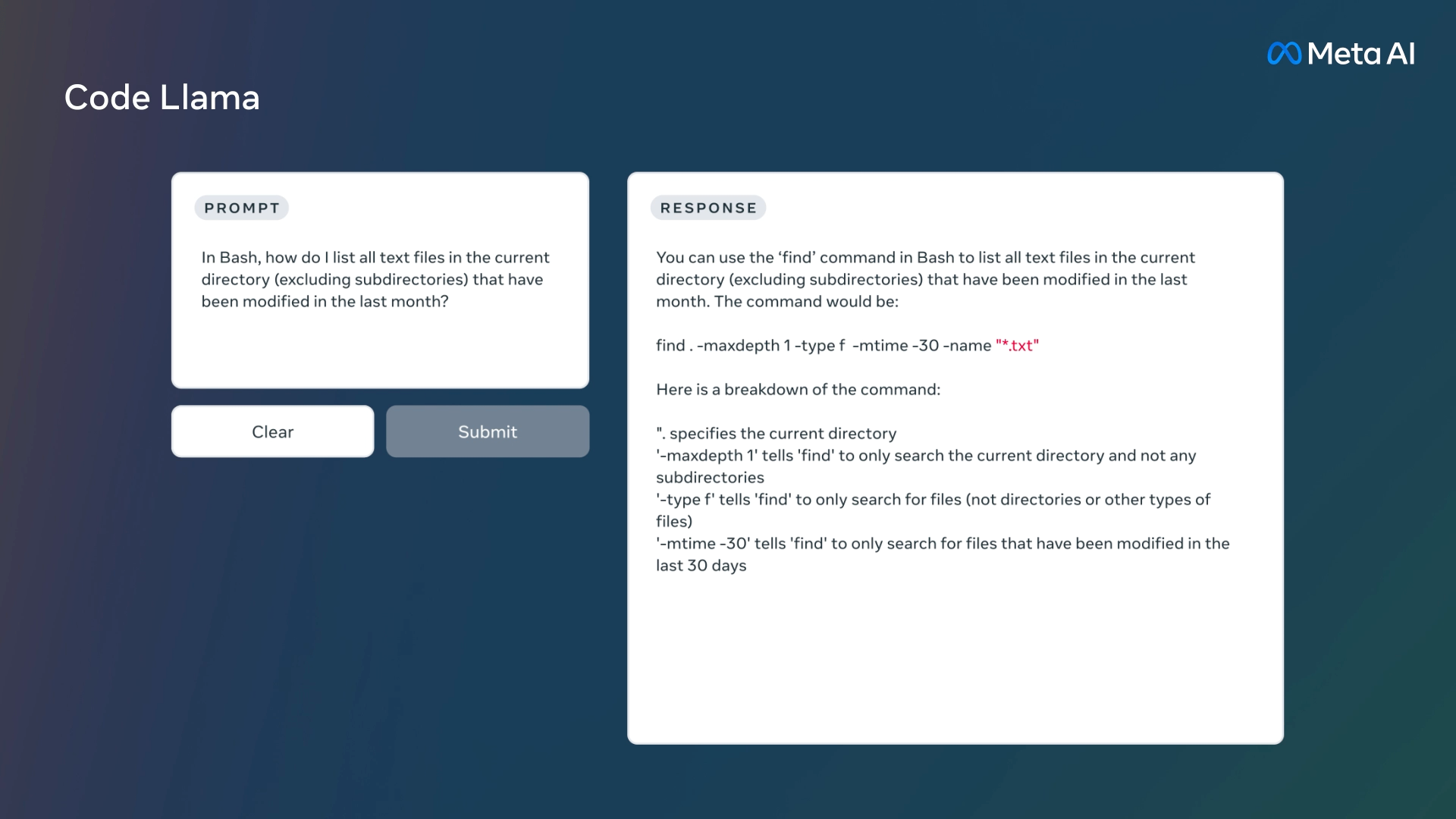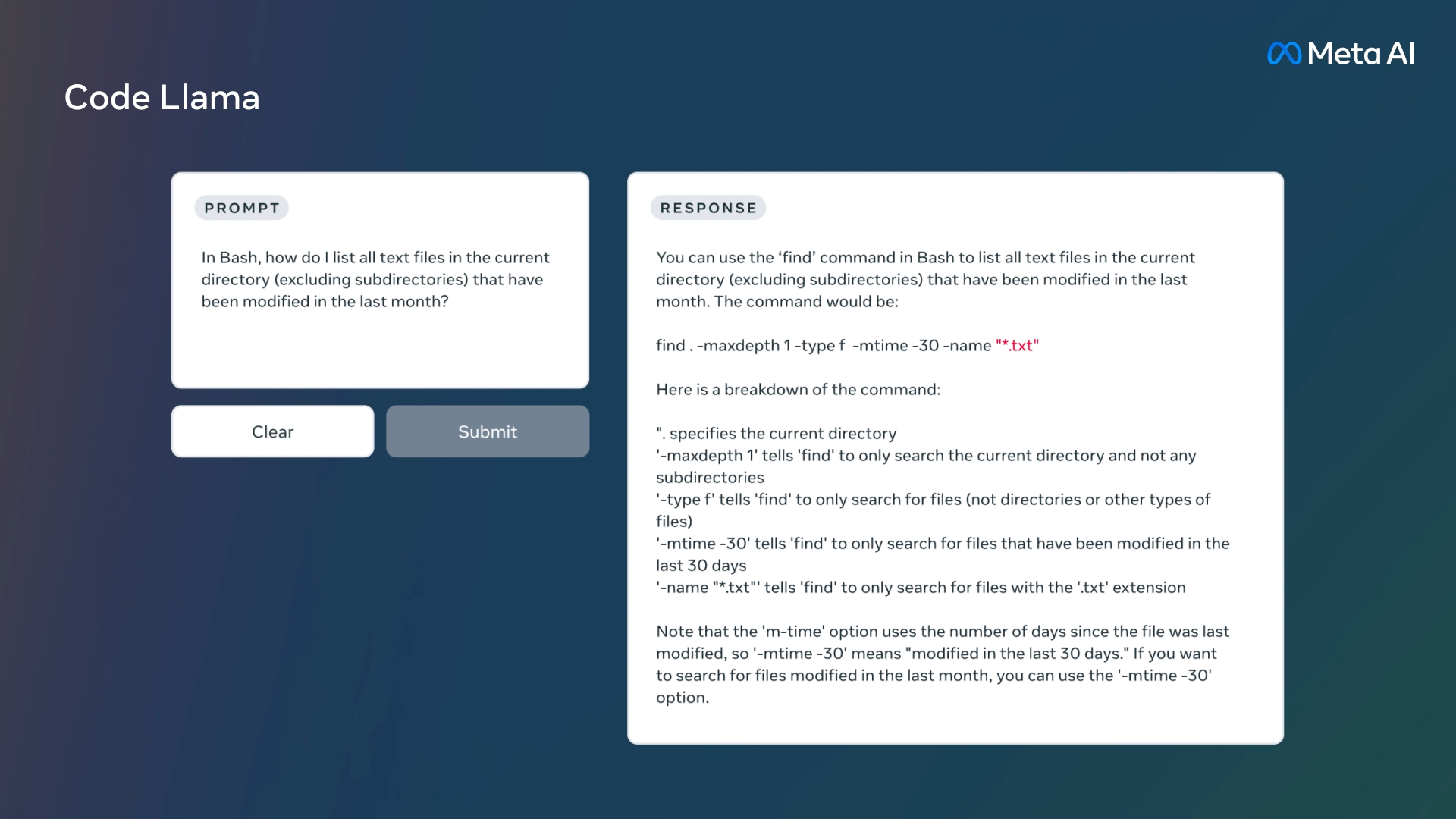
- 解释代码功能/结构
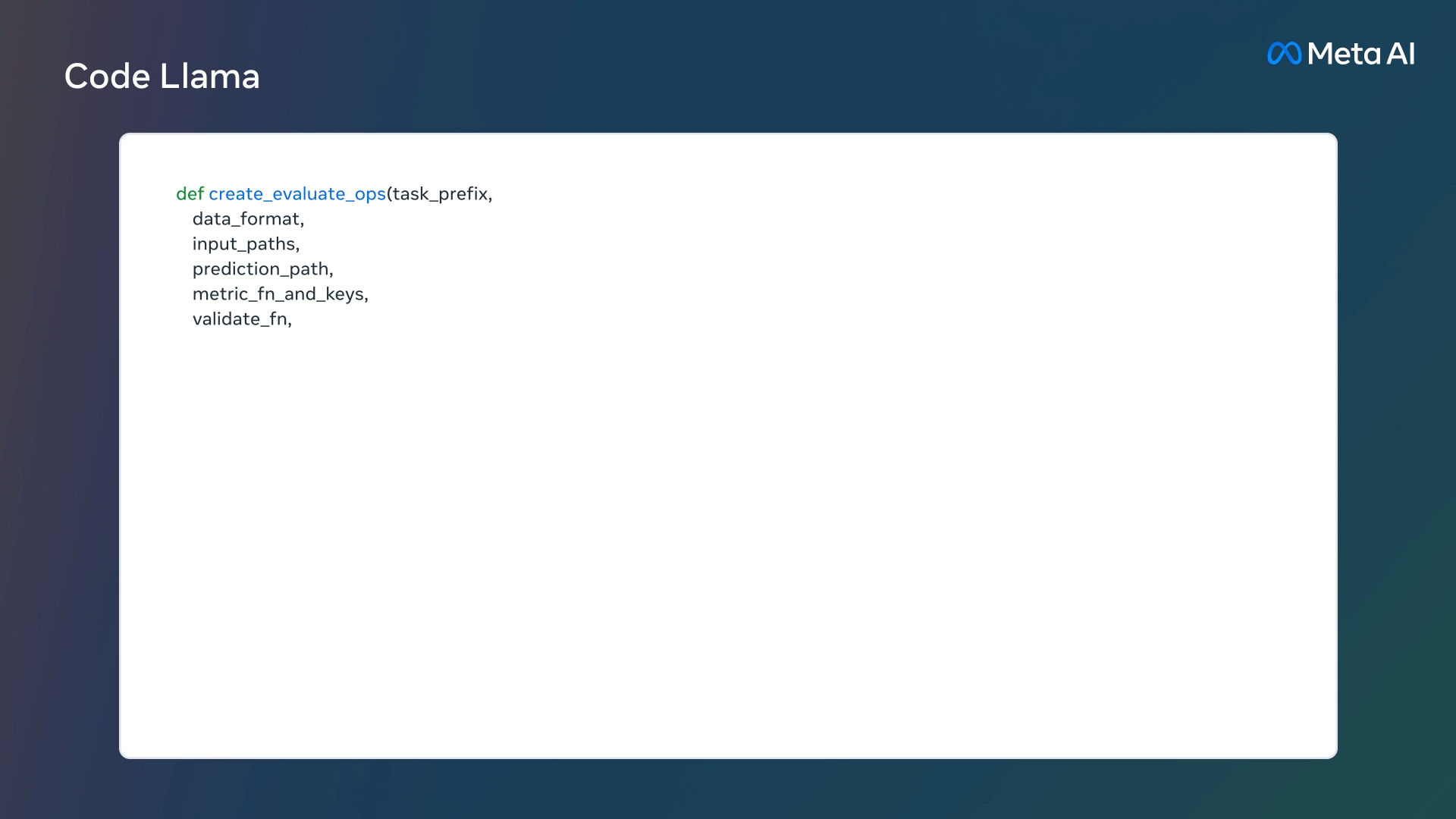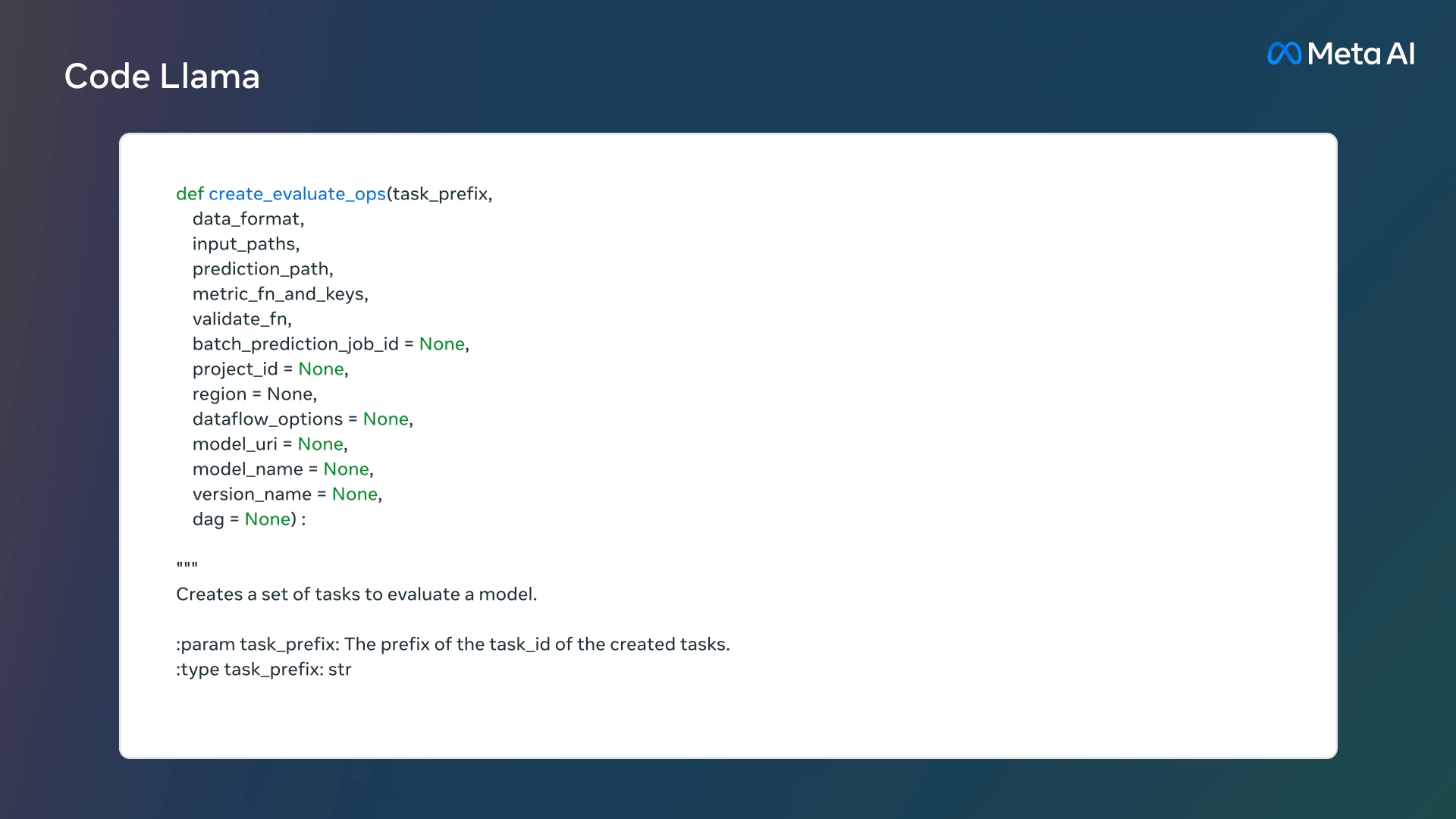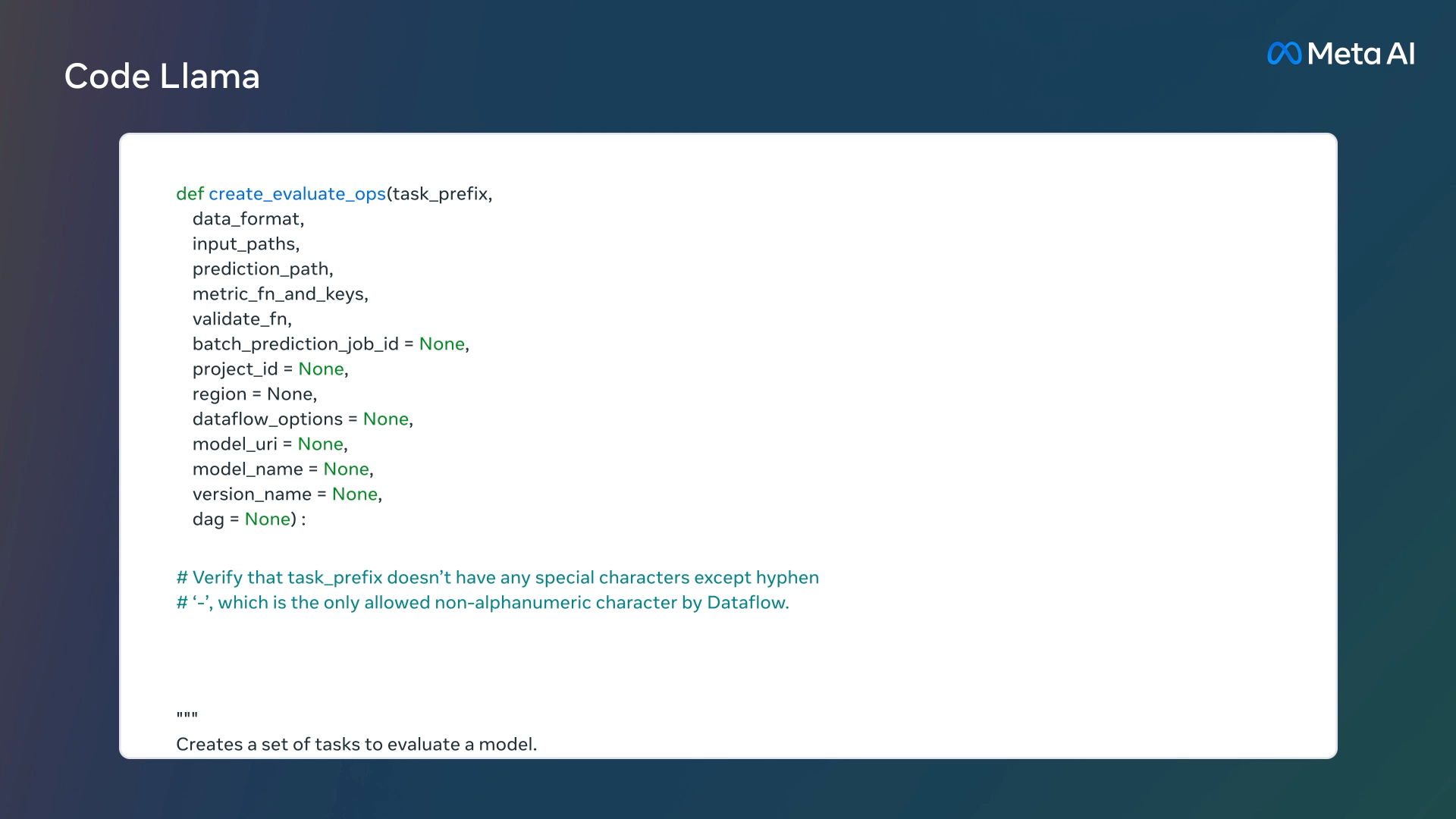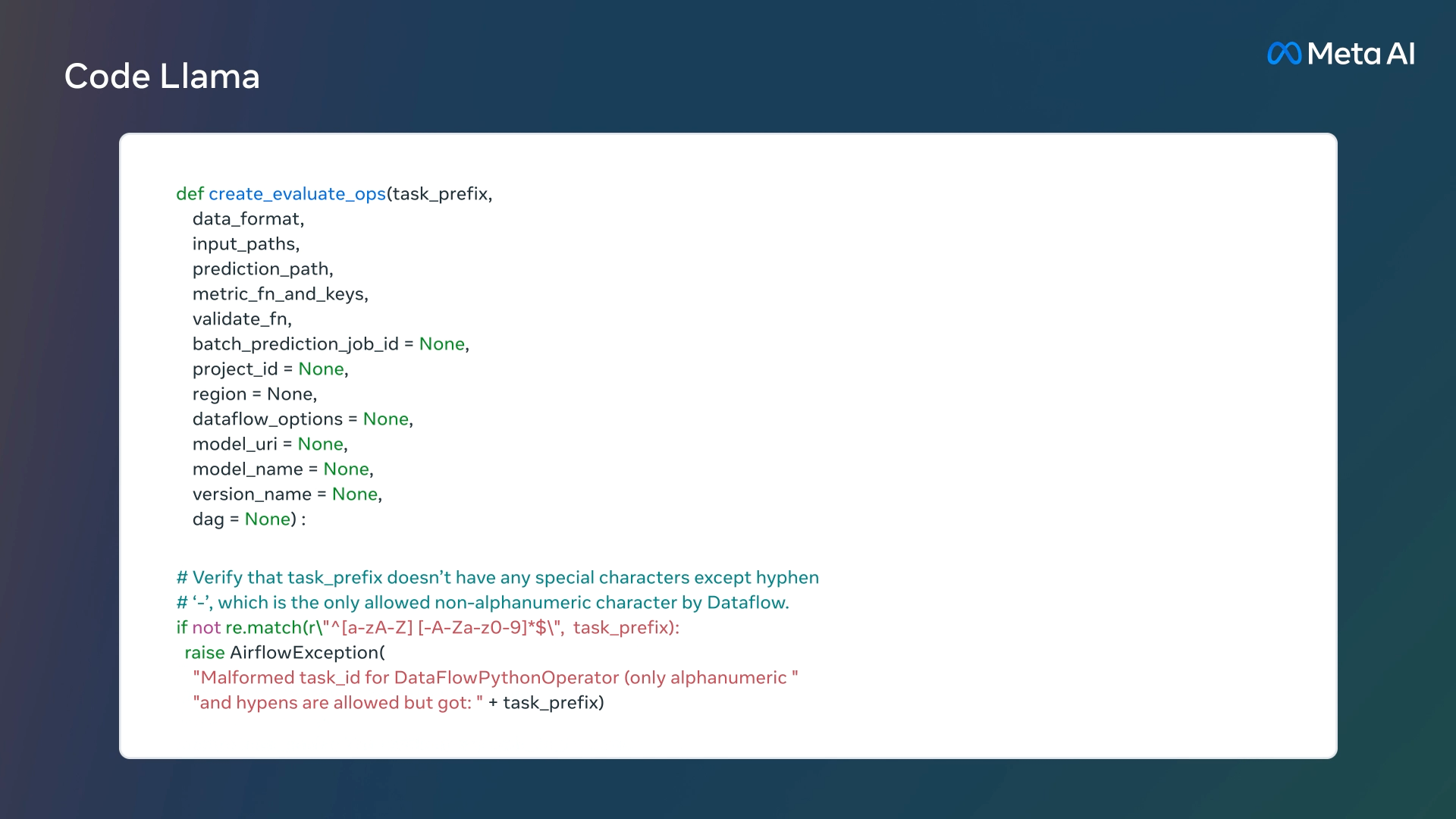
Code Llama 提供了三种不同大小的模型,分别具有 7B、13B 和 34B 参数,可以用于代码补全和调试。每个模型都使用 500B 代码 tokens 和代码相关数据进行训练,此外 7B 和 13B 基础模型和指令模型经过了中间填充 (FIM) 功能的训练,支持在现有代码中插入代码的功能。
Meta 表示这三种不同大小模型满足了不同的服务和延迟要求。例如,7B 模型可以在单个 GPU 上运行。 34B 模型返回最佳结果并提供更好的编码辅助,但较小的 7B 和 13B 模型速度更快,更适合需要低延迟的任务,例如实时代码补全。
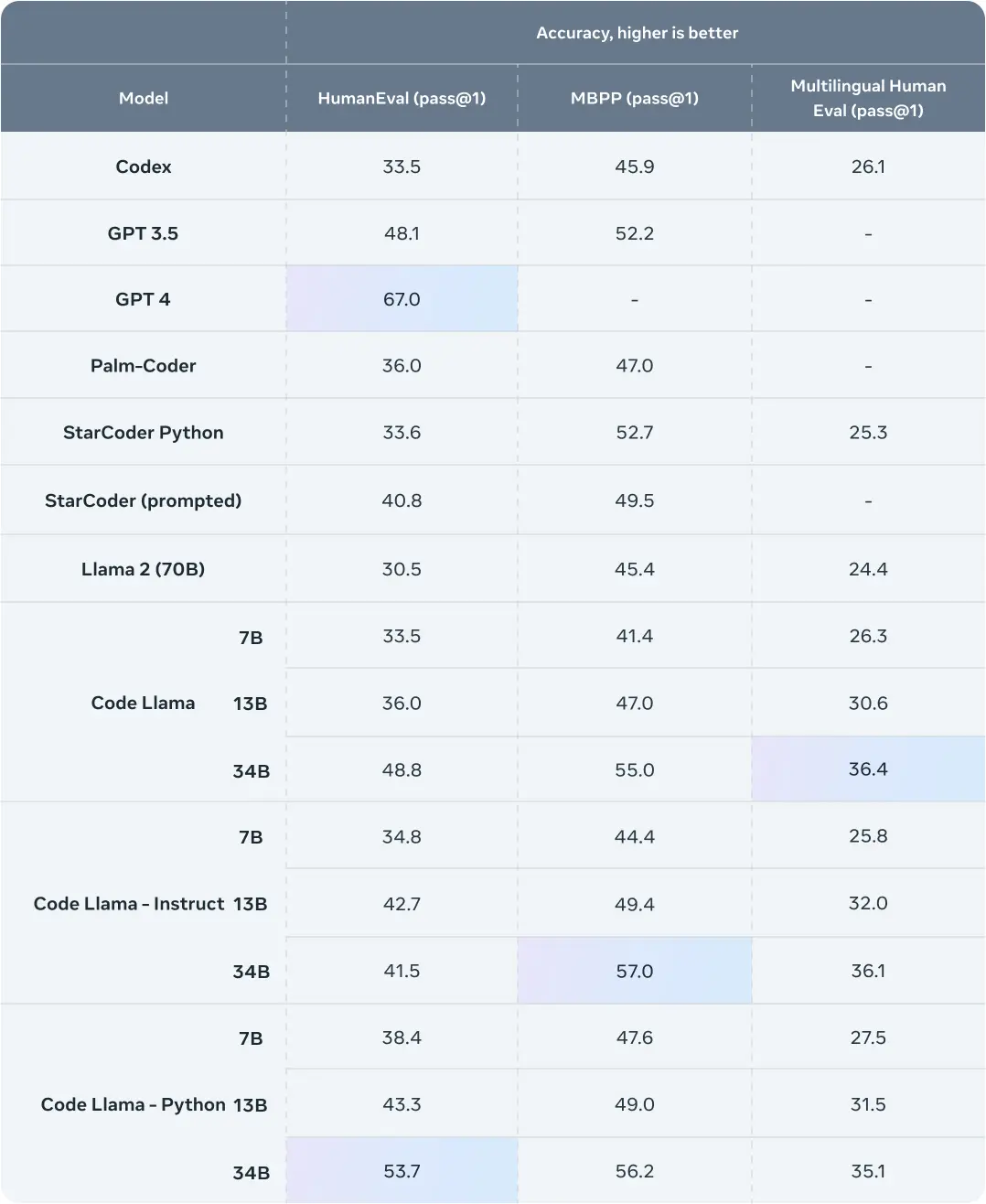
根据 Meta 提供的数据,Code Llama 在流行的编码基准测试 HumanEval 和 Mostly Basic Python Programming (MBPP)上的性能优于现有解决方案,并与 ChatGPT 相当。