Mistral AI 现已开源发布全新轻量级 AI 模型 Mistral Small 3.1。Mistral Small 3.1 能够处理文本和图像,参数仅为 240 亿。该模型提高了文本能力和多模态理解能力,并具备 128K 上下文窗口。
核心特性
- 轻量级部署:可在 单个 RTX 4090 或 32GB RAM 的 Mac 上运行,非常适合本地或设备端应用。
- 快速对话响应:优化交互体验,适用于虚拟助手等需要即时反馈的应用场景。
- 低延迟函数调用:在自动化和代理工作流中可快速执行函数,提高效率。
- 专属微调(Fine-Tuning):支持特定领域的定制优化,以满足不同业务需求。
- 强大的推理能力:为社区创新提供坚实基础,例如 Nous Research 在 Mistral Small 3 之上构建的 DeepHermes 24B。
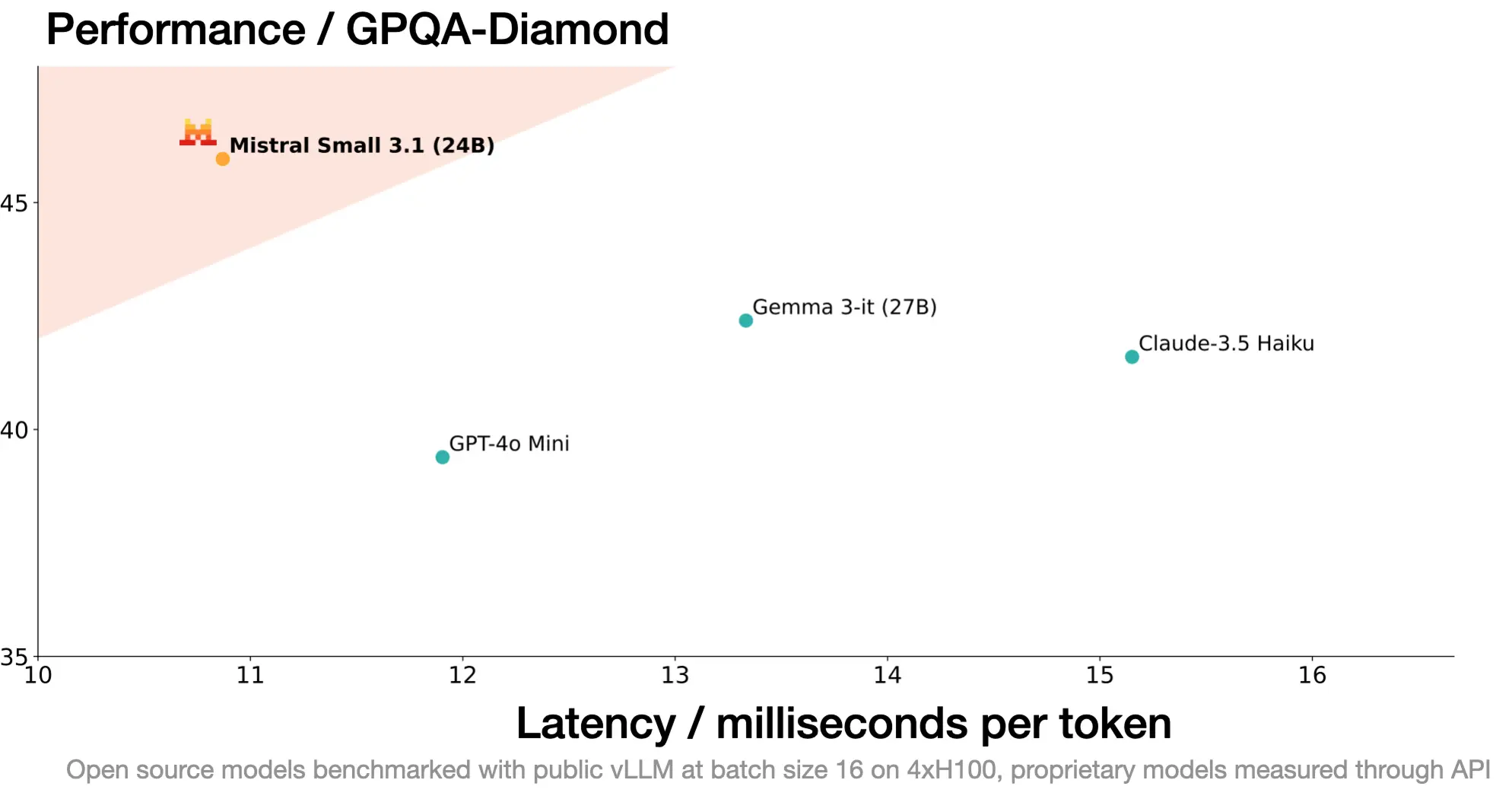
Mistral AI 表示,Mistral Small 3.1 的数据处理速度约为每秒 150 个字节,非常适合需要快速响应的应用。该模型被设计用于处理各种生成式人工智能任务,包括指令跟踪、对话辅助、图像理解和函数调用。它为企业级和消费级人工智能应用奠定了坚实的基础。
下载地址:Mistral Small 3.1 Base & Mistral Small 3.1 Instruct