Mistral AI 宣布推出其首个针对企业的音频模型系列 Voxtral。包含两种规模:适用于生产规模应用的 24B 版本,以及适用于本地和边缘部署的 3B 版本。两个版本均基于 Apache 2.0 许可证发布。
公告称,Voxtral 解决了开发者需要在低成本的开源系统和高效但封闭的解决方案之间做选择的问题。该模型以不到同类 API 一半的价格,在开放环境中提供最先进的准确率和原生语义理解,使得高质量的语音智能能够大规模访问和控制。
Voxtral 的功能包括:
- 长格式上下文: Voxtral 具有 32k 个 token 上下文长度,可处理长达 30 分钟的转录音频或 40 分钟的理解音频
- 内置问答和摘要:支持直接针对音频内容提问或生成结构化摘要,无需链接单独的 ASR 和语言模型
- 原生多语言:自动语言检测和最先进的性能,支持世界上使用最广泛的语言(英语、西班牙语、法语、葡萄牙语、印地语、德语、荷兰语、意大利语等),帮助团队通过单一系统服务全球受众
- 直接从语音进行函数调用:支持根据语音用户意图直接触发后端函数、工作流或 API 调用,将语音交互转化为可操作的系统命令,而无需中间解析步骤。
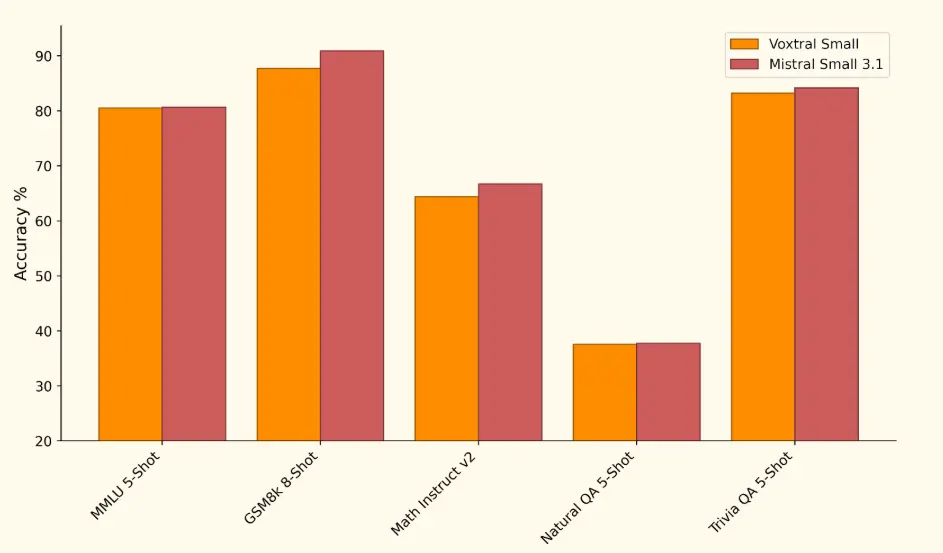
- 文本处理能力强:保留了其语言模型主干 Mistral Small 3.1 的文本理解能力
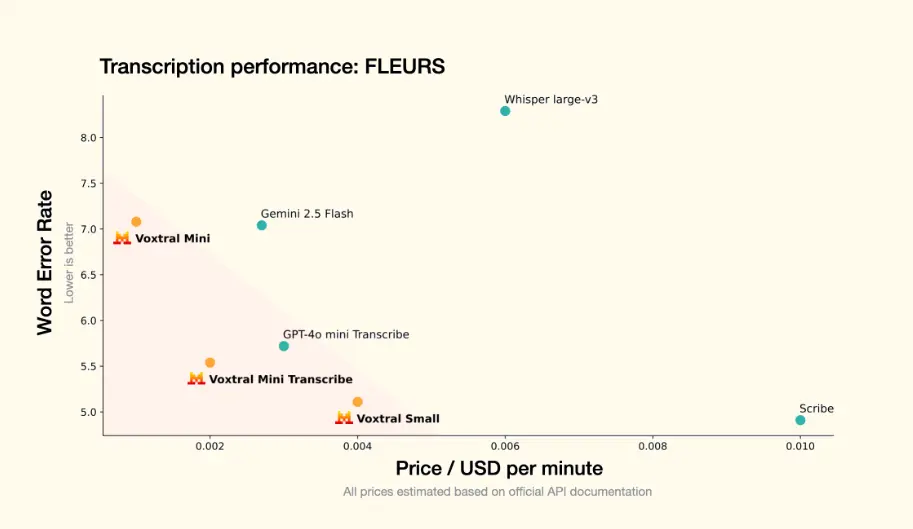
“这些功能使 Voxtral 模型成为现实世界交互和后续操作(例如摘要、答案、分析和洞察)的理想选择。对于成本敏感的用例,Voxtral Mini Transcribe 的性能优于 OpenAI Whisper,但价格不到后者的一半。对于高端用例,Voxtral Small 的性能与 ElevenLabs Scribe 相当,但价格也不到后者的一半。”
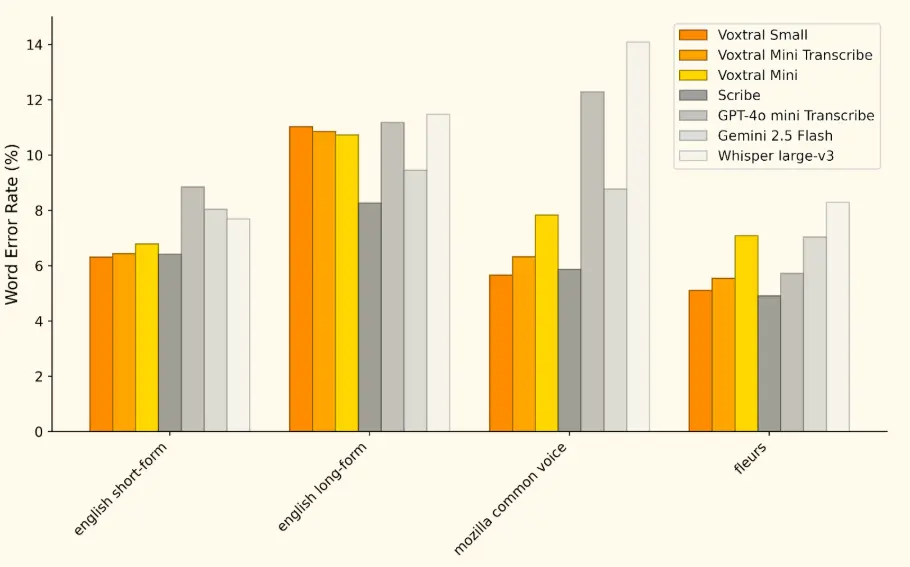
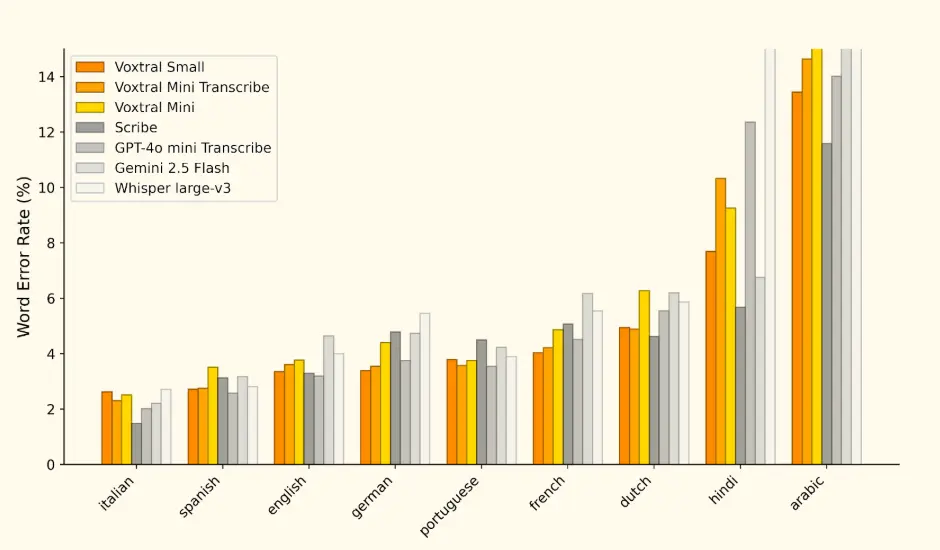
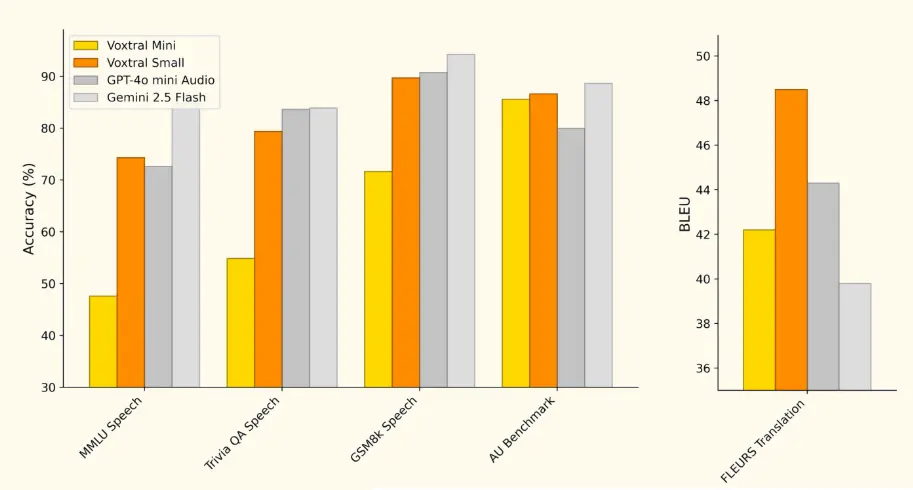
Mistral AI 指出,基准测试结果表明 Voxtral 的表现全面超越了目前领先的开源语音转录模型 Whisper large-v3。它在所有任务上都超越了 GPT-4o mini Transcribe 和 Gemini 2.5 Flash,并在英语短格式和 Mozilla Common Voice 上取得了最佳成绩,超越了 ElevenLabs Scribe,展现了其强大的多语言能力。
更多详情可查看官方公告。