Meta 今天发布了 Llama 3.2 系列开源模型,其中包括小型和中型视觉 LLMs(11B 和 90B),以及适合边缘和移动设备的小型纯文本模型(1B 和 3B),包括预训练和指令调整版本。
LLaMA 3.2 支持同时处理文本、图像和视频,能够理解并生成跨媒体内容。例如,用户可以在同一交互中结合文字和图像。
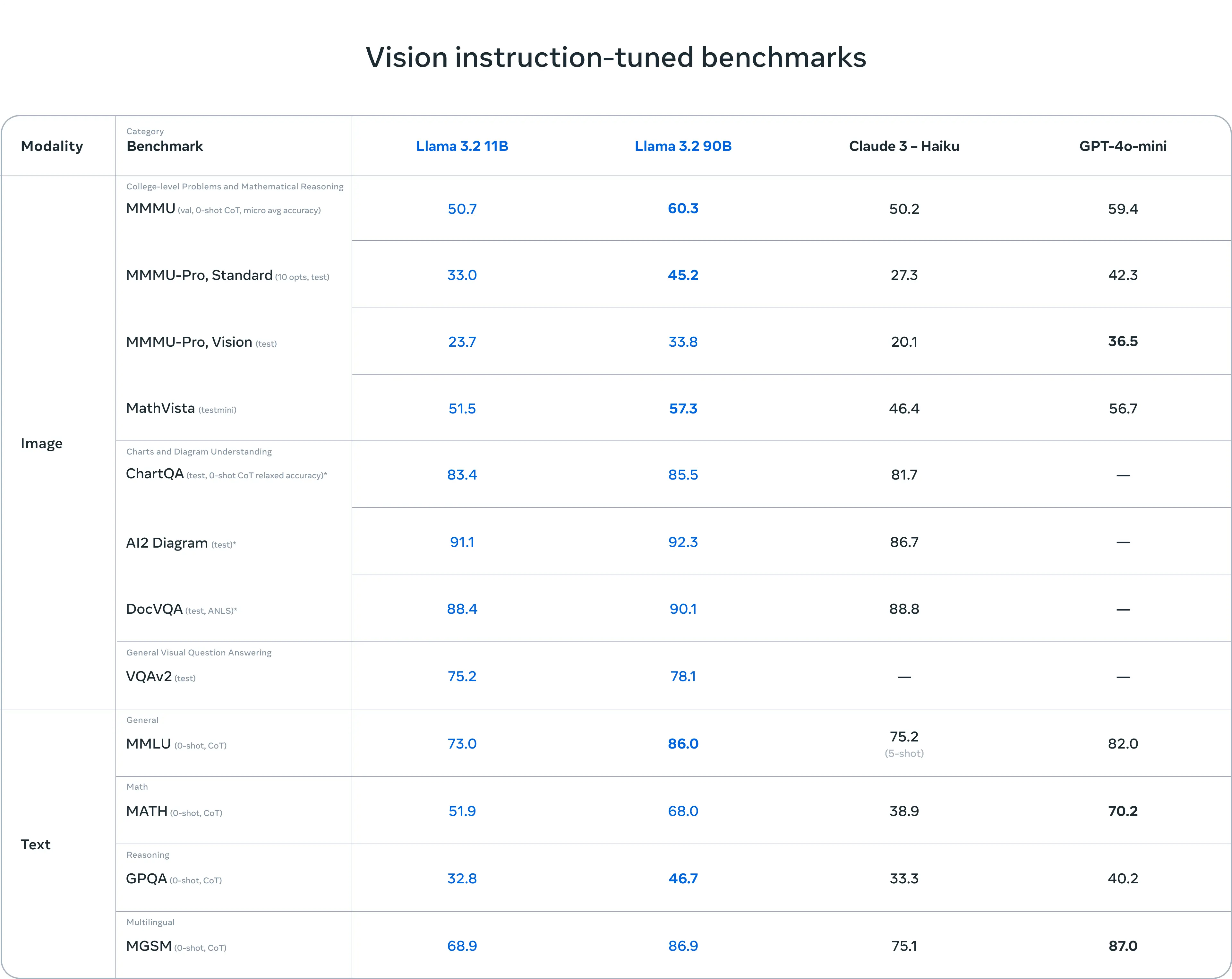
官方的评估结果显示,Llama 3.2 视觉模型在图像识别和一系列视觉理解任务上与 Claude 3 Haiku 和 GPT4o-mini 的性能相当。
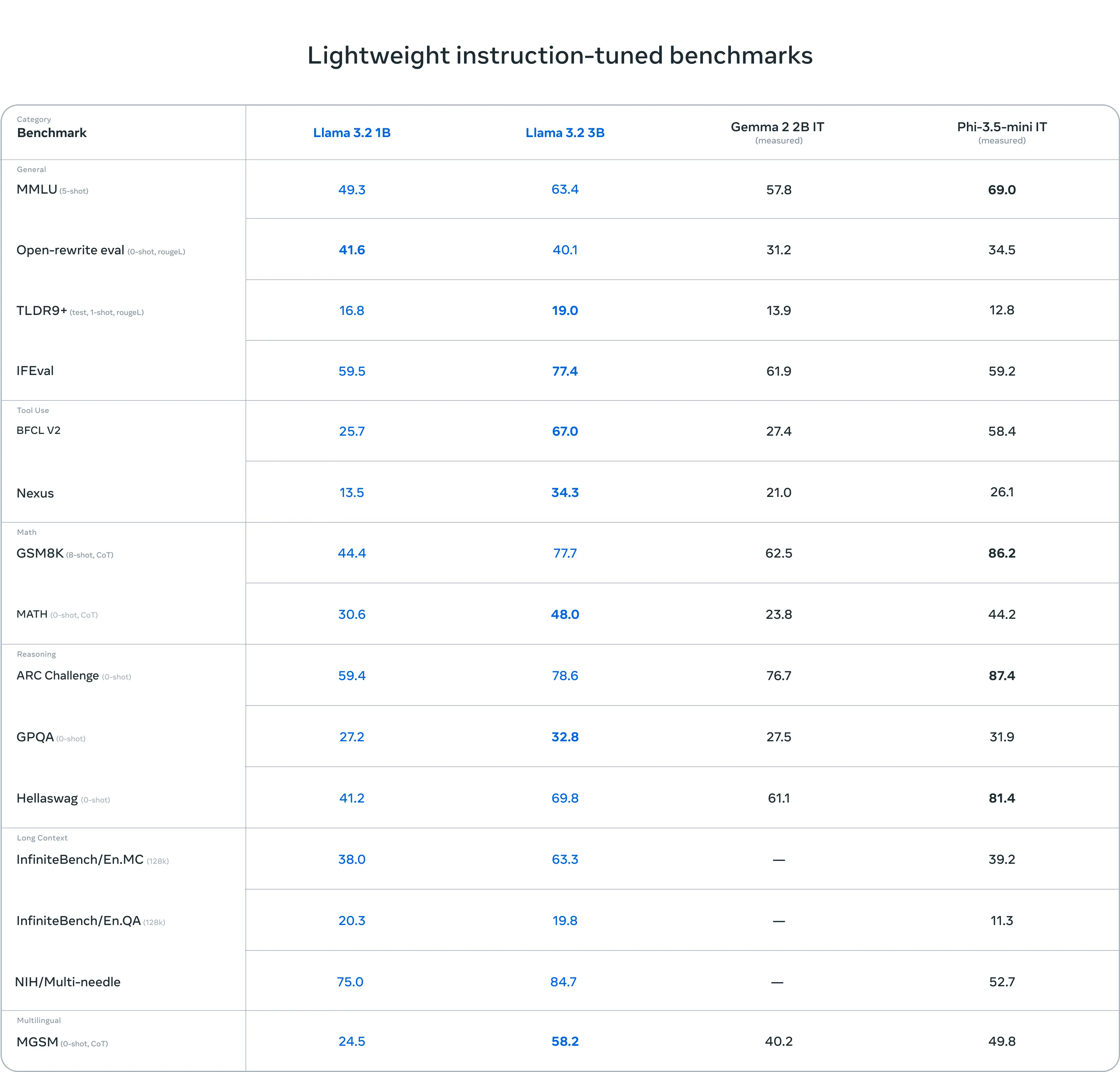
Llama3.2-3B 文本模型在循指令、总结、提示重写和工具使用等任务上优于 Gemma 2 2.6B 和 Phi 3.5-mini 模型。
多模态模型
Llama3.2的11B和90B模型多模态是基于Llama3.1-8B、70B文本模型上,增量增加图像模型。
pretrain阶段:
-
文本模块由Llama3.1模型初始化,并初始化图像编码器,利用大规模噪声(图像、文本、6B数据对)对数据进行预训练
-
再用中等规模的高质量的领域、知识增强的(图像、文本、3M数据对)数据预训练。
posting-train阶段:
-
通过监督微调、拒绝采样和直接偏好优化进行多轮对齐
-
使用 Llama 3.1 模型 过滤和增强 图像上的问题和答案,利用合成数据生成和奖励模型对所有候选答案打分排序,获取高质量的微调数据
-
还添加了安全数据
端侧小模型
1B和3B模型都是基于8B模型裁剪后进行模型初始化,并且利用8B和70B模型进行模型蒸馏,9T数据预训练。
特别注意,这里蒸馏不是那种通过更大模型进行数据生成的蒸馏,而是再模型训练阶段,利用8B 和 70B 模型输出的 logits 影响模型loss,也就是传统的蒸馏方法。
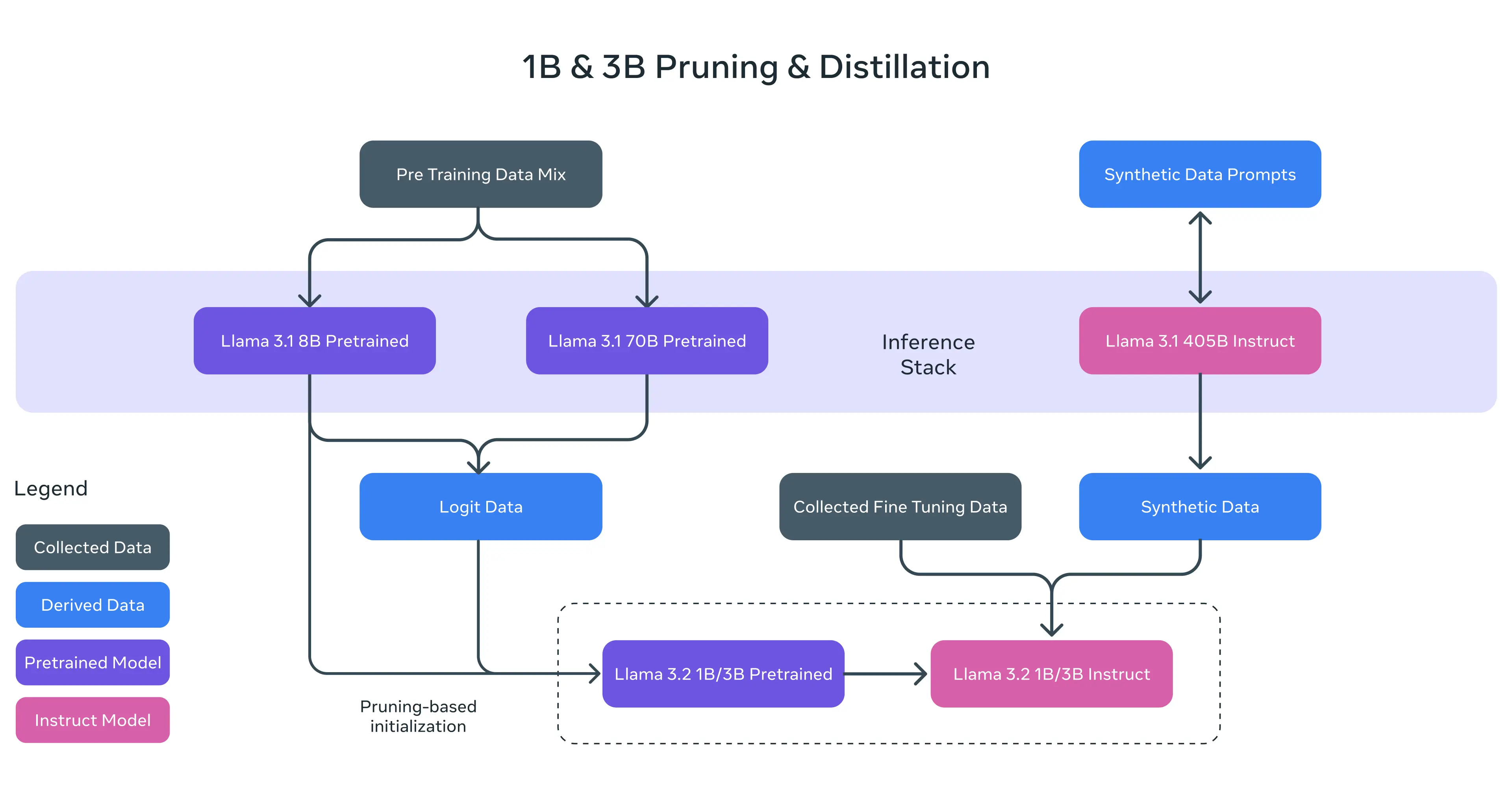
在post-traning阶段,训练方式语Llama3.1一致,采样监督微调、拒绝采样和直接偏好优化模型。
最后模型支持上下文扩展到 128K 个,同时也针对性优化了模型的多种能力,例如摘要、重写、指令遵循、语言推理和工具使用。