英伟达发布了一个包含300万高质量样本的视觉语言模型训练数据集,以支持OCR、VQA和图像字幕生成等多种应用。
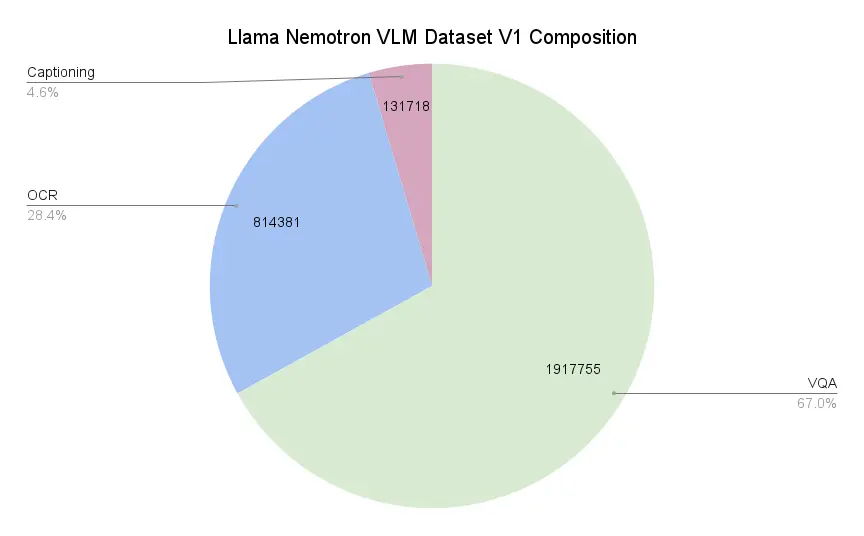
数据集构成
- 67.0% 视觉问答(VQA)样本
- 28.4% OCR 样本
- 4.6% 图像描述(Captioning)样本
主要用途
- 文档理解:支持复杂版面、表格、图文混排的 OCR 与内容提取。
- 企业级 AI 开发:数据已清除版权限制,可直接商用。
- 模型训练支持:配套 NVIDIA NeMo Curator 工具,便于进一步清洗和定制。
数据来源与构建方式
- 基于开源数据集重新标注,确保可商用;
- 使用 NVIDIA 自研模型进行增强,如加入链式思考(Chain-of-Thought)解释、模板化问答生成、答案扩展等;
- 提供中英双语的 OCR 数据,涵盖字符级、词级、页面级标注。
模型配套
该数据集是 Llama 3.1 Nemotron Nano VL 8B 模型的训练基础,该模型在 OCRBench V2、DocVQA、ChartQA 等基准测试中表现领先,已作为 NVIDIA NIM API 和 Hugging Face 模型库的一部分开放使用。
如需获取数据集,可直接访问 Hugging Face 页面:https://huggingface.co/datasets/nvidia/Llama-Nemotron-VLM-Dataset-v1