水木分子联合清华大学智能产业研究院(AIR)宣布开源全球首个可商用多模态生物医药百亿参数大模型 BioMedGPT-10B,可用于提升药物研发各个环节的效率,包括新药立项评估、药物设计和优化、临床试验设计、适应症拓展等。
此外,该模型在生物医药专业领域问答能力比肩人类专家水平,在自然语言、分子、蛋白质跨模态问答任务上达到 SOTA,已成功通过了美国医师资格考试。
开源地址:
- https://github.com/PharMolix/OpenBioMed
- https://huggingface.co/PharMolix/BioMedGPT-LM-7B
BioMedGPT 是全新的多模态语义理解框架,它运用了生物医学领域中的预训练大语言模型—BioMedGPT-LM作为桥梁,将自然语言、生物编码语言以及化学分子语言等连接起来。
BioMedGPT 架构::
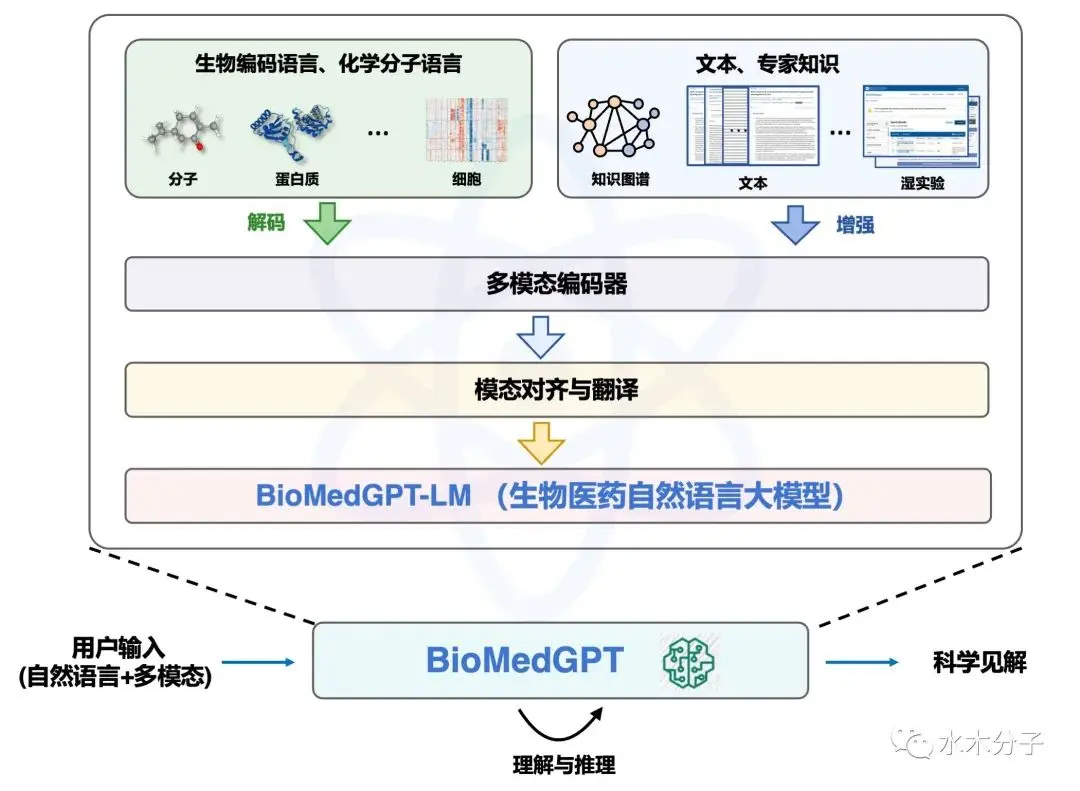
BioMedGPT-LM 通过充分利用海量生物医学相关数据,对通用的基于GPT架构的大型语言模型进行微调,在生物医学领域发挥更出色的性能。
作为连接桥梁,BioMedGPT-LM能够连接各种生物模态的编码,包括分子、蛋白质、细胞和基因表达数据,同时还能够整合知识图谱、文档、数值实验结果以及其他格式所体现的专业知识。通过跨模态特征融合模块集成,不同模态的生物编码语言、化学分子语言与自然语言能够在同一个特征空间中实现统一融合。
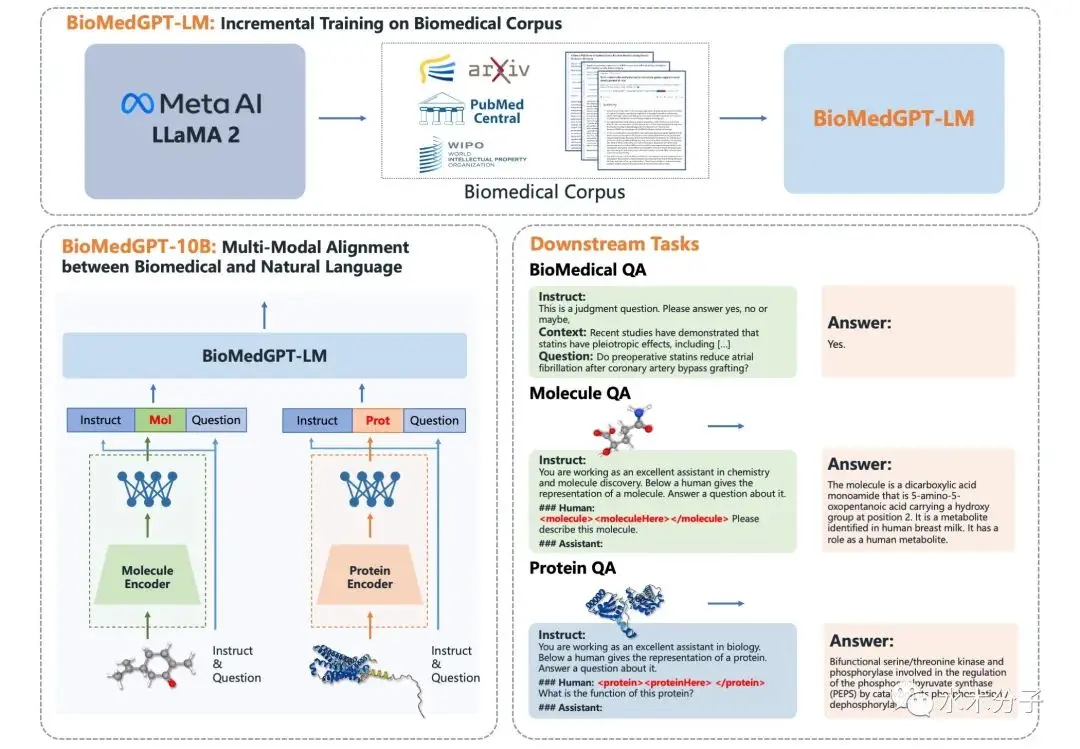
同时,水木分子、AIR联合开源了全球首个免费可商用、生物医药专用Llama 2大语言模型BioMedGPT-LM-7B。“AIR-智源健康计算联合研究中心” 合作开源了小分子药物基础模型DrugFM。此次开源的生物医药基础模型重科研、可商用,为生物医药研究与应用提供大模型底座。