LLaSM 是一个开源可商用的中英文双语语音 - 语言助手,其相关论文“LLaSM: Large Language and Speech Model”与最近正式在 arXiv 上发布。论文的署名组织包括:LinkSoul.AI、北京大学和 01.ai (零一万物),其中共同一作 Yu Shu 和 Siwei Dong 均来自 LinkSoul.AI。
LinkSoul.AI 是一家 AI 初创公司,曾推出过首个开源 Llama 2 的中文语言大模型;零一万物则是李开复旗下的大模型公司。
“多模态大型语言模型近来备受关注。不过,大多数研究都集中在视觉-语言多模态模型上,这些模型在遵循视觉和语言指令方面具有很强的能力。然而,我们认为语音也是人类与世界互动的一种重要方式。因此,对于通用助手来说,能够遵循多模态语音语言指令至关重要。”

根据介绍,LLaSM 是一个经过端到端训练的大型多模态语音语言模型,具有跨模态对话能力,能够遵循语音语言指令。早期实验表明,LLaSM 为人类与人工智能的交互提供了一种更方便、更自然的方式。便捷的语音输入将大幅改善以文本为输入的大模型的使用体验,同时避免了基于 ASR 解决方案的繁琐流程以及可能引入的错误。
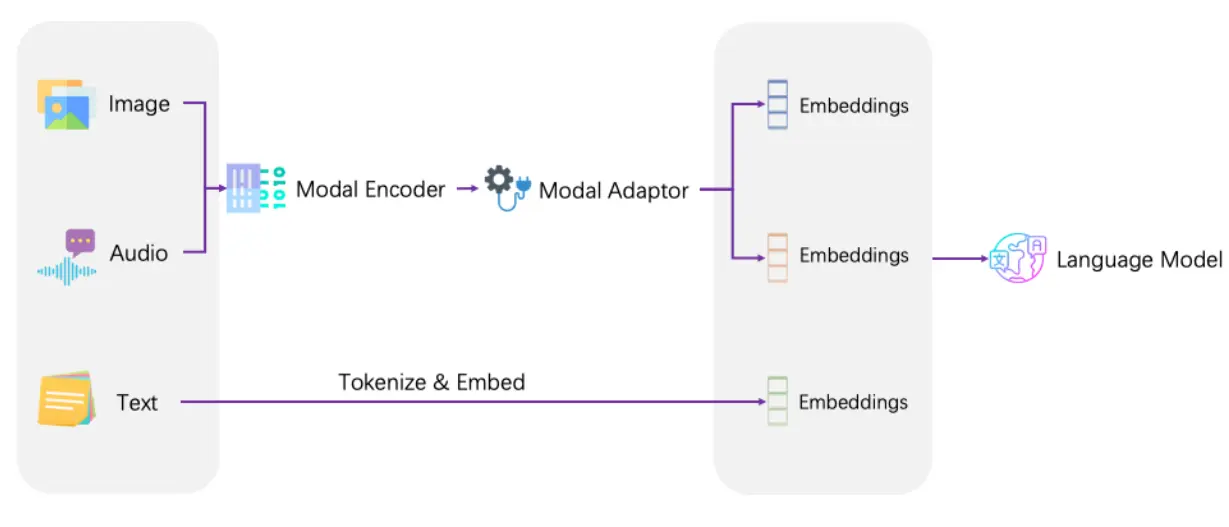
LLaSM 的模型架构如上图所示。研究人员首先使用 Whisper 将原始音频数据编码为嵌入词,然后在预训练阶段训练模态适配器,以对齐音频嵌入词和文本嵌入词。音频嵌入式和文本嵌入式连接在一起,形成交错的输入序列,输入到大语言模型中。考录到同时具备中文和英文能力,LLM 的选择则为 Chinese-LLAMA2-7B -LLAMA2-7B。在跨模态指令微调阶段,模态适配器和 LLM 会接受多任务训练。
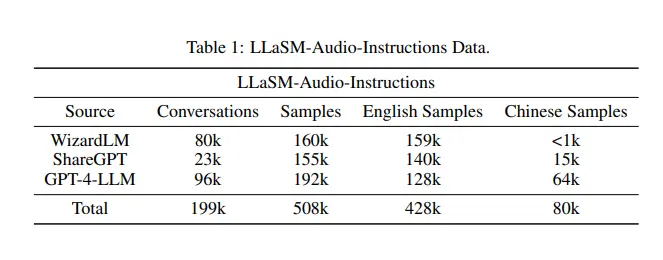
与此同时,研究人员还发布了一个大规模的中英文语音-文本跨模态指令遵循数据集 LLaSM-Audio-Instruction;通过从 GPT4-LLM、ShareGPT 和 WizardLM 中精心挑选对话,并使用文本到语音技术生成大量对话音频数据。
该数据集共包含 19.9 万个对话和 50.8 万个语音-文本样本。在 50.8 万个语音-文本样本中,有 8 万个中文语音样本,42.8 万个英文语音样本;是目前所知最大的中英文语音-文本跨模态指令跟随数据集。不过其目前还在整理中,官方表示整理完后会进行开源。

更多详情可查看完整论文。