TOGETHER 宣布其 RedPajama 7B 已完成所有训练,并在 Apache 2.0 许可下全部开源。
RedPajama 是一个开源可商用大模型项目,由 TOGETHER 联合蒙特利尔大学的 AAI CERC 实验室、EleutherAI 和 LAION 共同发起。目前包括一个基于 LLaMA 论文的 RedPajama 基础数据集(5 TB 大小),自 4 月份发布至今已被下载数千次,并被用来训练了 100 多个模型;以及一个在 5 月份就宣布训练完成的 RedPajama 3B,和刚宣布训练完成的 RedPajama 7B 大模型。
- RedPajama-INCITE-7B-Base 在 RedPajama-1T 数据集的 1T tokens 上进行训练,并发布了训练和开放数据生成脚本的 10 个 checkpoints,允许模型的完全可重复性。该型号在 HELM 上落后 LLaMA-7B4 分,落后 Falcon-7B/MPT-7B 1.3 分。
- RedPajama-INCITE-7B-Instruct 是 HELM 基准测试中得分最高的开放模型,使其成为各种任务的理想选择。它在 HELM 上的性能表现相较 LLaMA-7B 和目前最先进的开放模型如 Falcon-7B (Base and Instruct) 和 MPT-7B (Base and Instruct) 均高出2-9分。
- RedPajama-INCITE-7B-Chat 在 OpenChatKit 中可用,包括一个用于轻松微调模型的训练脚本,现在可以试用。聊天模型建立在完全开源的数据之上,不使用来自 OpenAI 等封闭模型的提炼数据 - 确保在开放或商业应用程序中的使用。
其中,Base 模型是基础大语言模型,在 RedPajama 数据集上进行了训练,采用和 Pythia 模型一样的架构。LM Harness 结果:
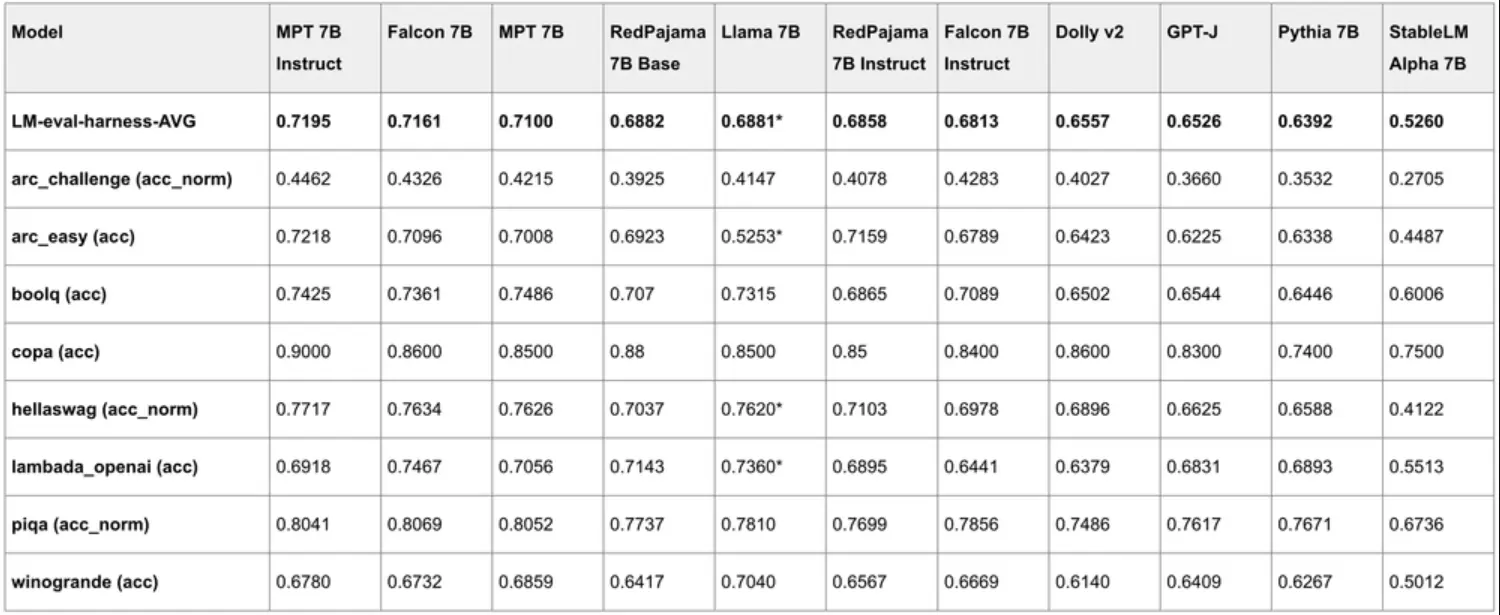
Instruct 则是基于 Base 模型针对 few-shot prompts 微调的结果,通过对 P3 (BigScience) 和 Natural Instruction (AI2) 的各种 NLP 任务进行训练,针对少样本性能进行了优化。Instruct 版本在少数几个任务上表现出优异的性能,超过了类似规模的领先开放模型;RedPajama-INCITE-7B-Instruct 似乎是此类规模下最好的开放式指令模型。HELM 基准测试结果:
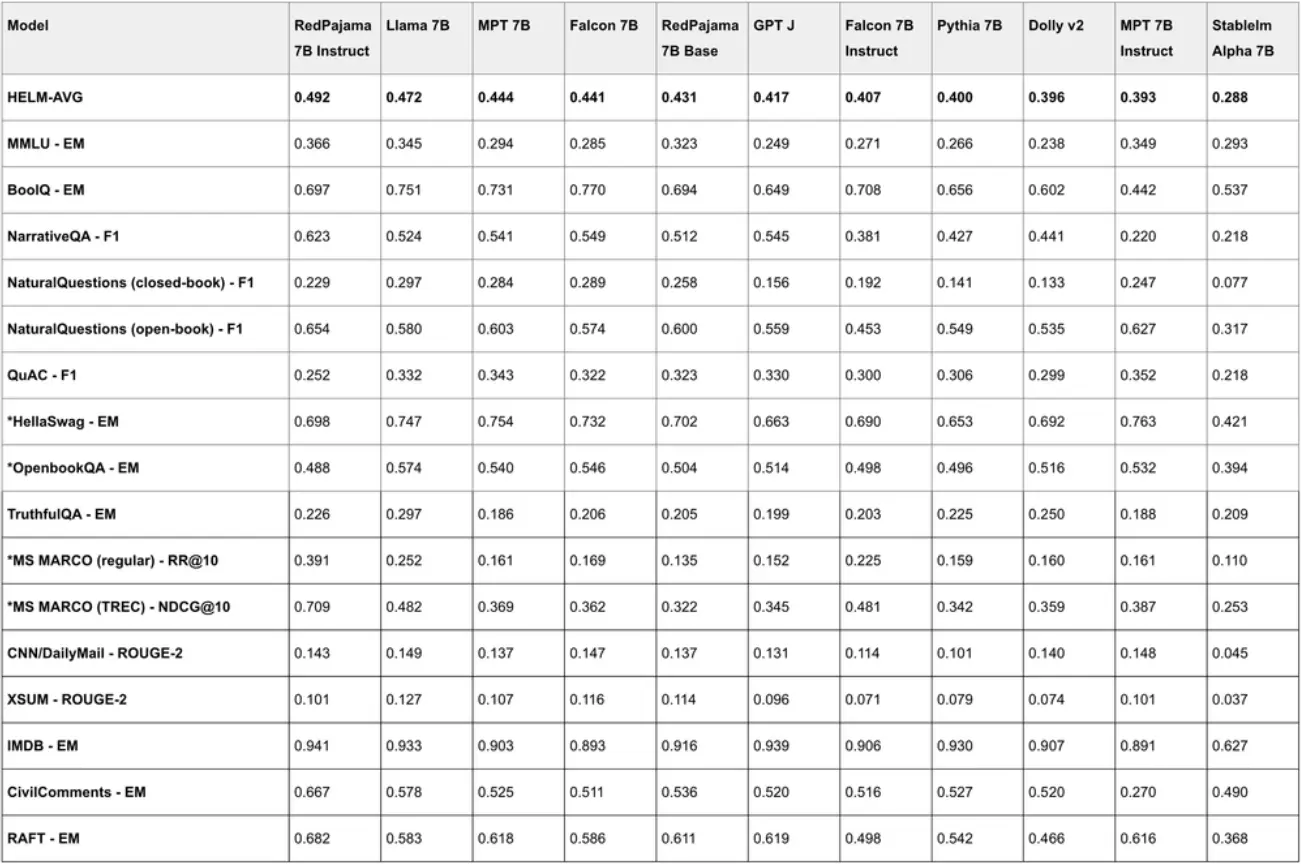
此外,官方还宣布正在开发新版本的 RedPajama,即 RedPajama2,目标是在 2-3T tokens 数据集上进行训练。主要有以下规划:
- 尝试基于 DoReMi 类似的技术来自动学习不同数据的混合。
- 引入 Pile v1(来自 Eleuther.ai)和 Pile v2(CrperAI)等数据集,以丰富当前数据集的多样性和规模。
- 处理更多的 CommonCrawl。
- 探索更多的数据去重复策略。
- 引入至少 1500 亿 tokens 的代码数据集,以帮助提高编码和推理任务的质量。
更多详情可查看官方博客。