智源研究院发文宣布,为了推动不同架构 AI 硬件系统的创新和落地,打造开源、统一的 AI 系统软件生态,联合多家机构开源 AI 编译器 FlagTree。
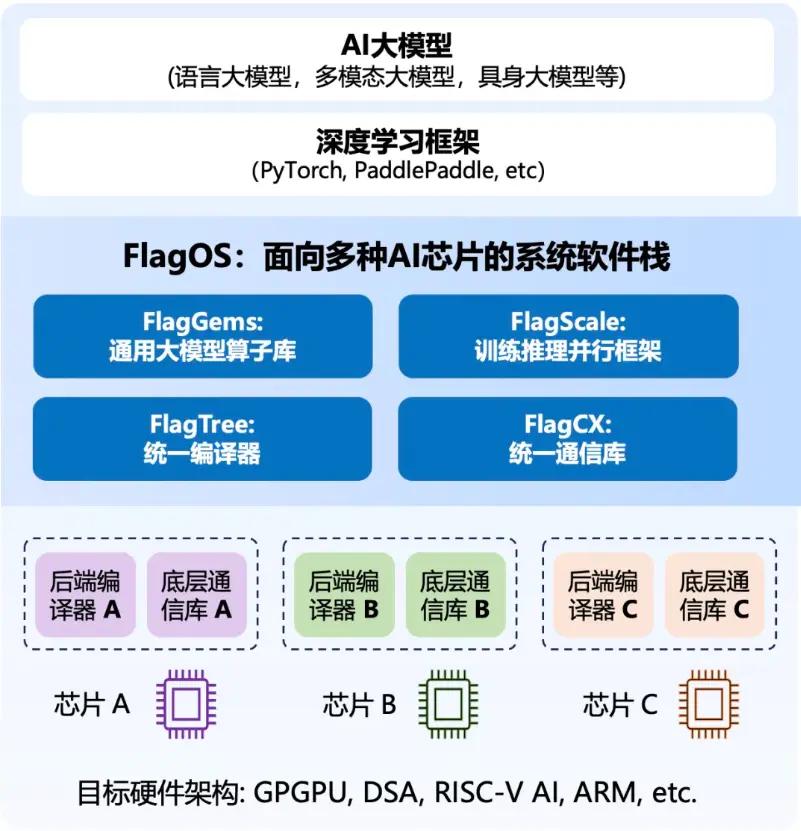
FlagTree 的开源,是开源、统一 AI 系统软件生态 FlagOS 发展进程中又一个重要的里程碑事件。至此,FlagOS 已经形成了具备高性能通用 AI 算子库FlagGems/FlagAttention、统一 AI 编译器 FlagTree、大模型训推一体框架 FlagScale 和统一通信库 FlagCX 的较为完整的系统软件技术栈。
FlagTree 开源社区希望通过开放合作的方式,打造一个支持Triton语言,面向多种 AI 硬件架构、增强对AI硬件特性支持能力的开源、统一 AI 编译器。从而为开发者提供更多选择,推动各种AI系统创新技术的普及和多元发展。
FlagOS 生态社区为 FlagTree 开源社区成立了开源治理委员会、技术指导委员会、项目管理委员会、社区秘书处等多个组织,已经有十多家机构加入 FlagTree 开源社区。
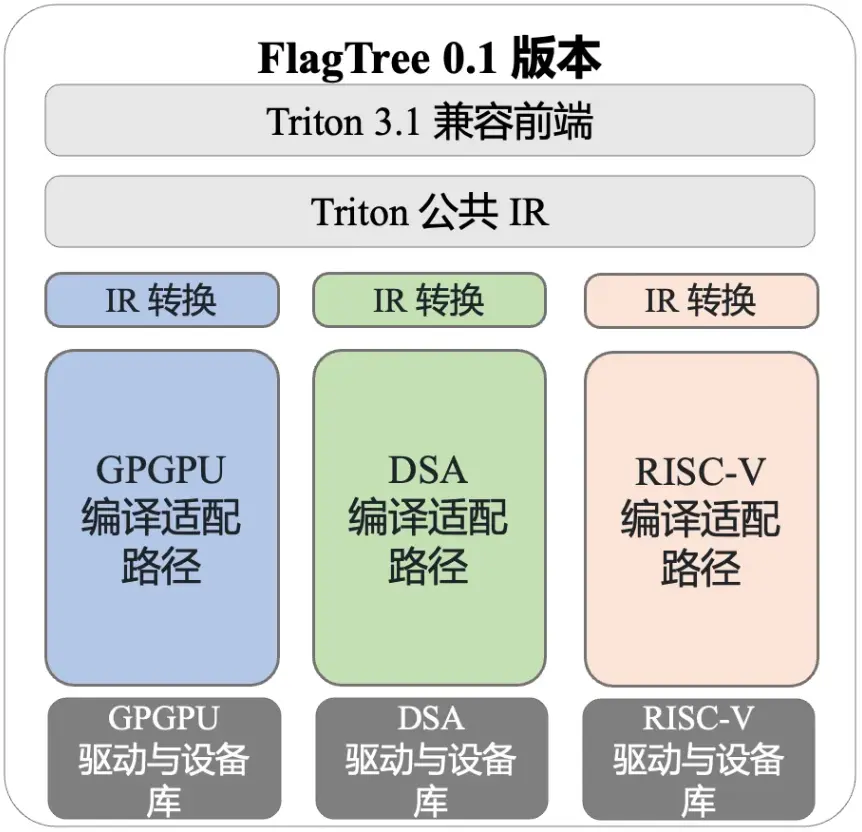
当前发布的 FlagTree v0.1版本能够兼容现有的 Triton 适配方案,实现了 Triton 语言的单版本多后端支持。目前,FlagTree 为支持多后端的编译器构建统一代码仓库;同时,FlagTree 统一承担对 Triton语言上游社区快速更迭的跟进任务,拉齐各芯片后端适配 Triton 的版本,为顺畅适配 Triton 语言的算子库铺平道路。
重要特性:
- 兼容现有两种主流编译路径:技术路线上,FlagTree 兼容 TritonGPU Dialect、Linalg Dialect 向下编译的两条编译路径,未来会充分收集各芯片平台的编译诉求,对中间层 IR 做统一设计。
- 接入形式灵活:源码、动态库
- 支持多种AI硬件后端:英伟达、摩尔线程等五家厂商
- 架构插件化设计:支持高差异度模块,相关的芯片平台可自行维护这部分模块的代码仓库
- 跨平台编译与快速验证能力
- CI/CD:构建完备CI/CD,覆盖多元 AI 芯片
- 维护 Triton 官方版本升级,减少重复投入
- FlagGems 和 FlagTree 联动,统一算子库与编译器
- 安全合规:由于本代码库有来自多个团队的贡献,我们使用专业工具保障项目代码的安全合规
下一个 FlagTree 版本将在以下方面进行重要更新:
- 在现有多种芯片后端的支持基础上,继续扩展更多后端的支持,包括在近期已经正式加入FlagTree开源社区的华为、清微智能和ARM中国等。
- 升级 Triton 新版本特性,包括3.2.x、3.3.x。
- 对非 GPGPU 后端提供多种接入范式,如新增 FLIR 仓库支持基于 Linalg Dialect 扩展
- GPGPU 后端代码整合,规范接入标准
- 针对不同的硬件特性提供编程接口及编译支撑,从而在非侵入式修改语言层的前提下通过指导信息提升性能,如支持 DMA、Shared Memory 的硬件感知提示
- FlagGems 和 FlagTree 联动,统一算子库与编译器,包括版本适配、后端适配、推理芯片适配等