智源研究院宣布已开源与南开大学共同构建的 Chinese-LiPS 中文多模态语音识别数据集。
作为首个“唇读信息+幻灯片语义信息”结合的中文多模态语音识别数据集,Chinese-LiPS数据集面向中文讲解、科普、教学、知识传播等复杂语境,致力于推动中文多模态语音识别技术的发展。
评测实验结果显示,在仅采用语音单模态输入的情况下,模型的字符错误率(CER)为 3.99%。当将语音、唇读信息、通过 OCR 技术从幻灯片提取的文本以及从图像和图形内容中获取的语义信息进行融合时,模型的字符错误率显著下降至 2.58%。
该数据集具备以下四大核心特点:
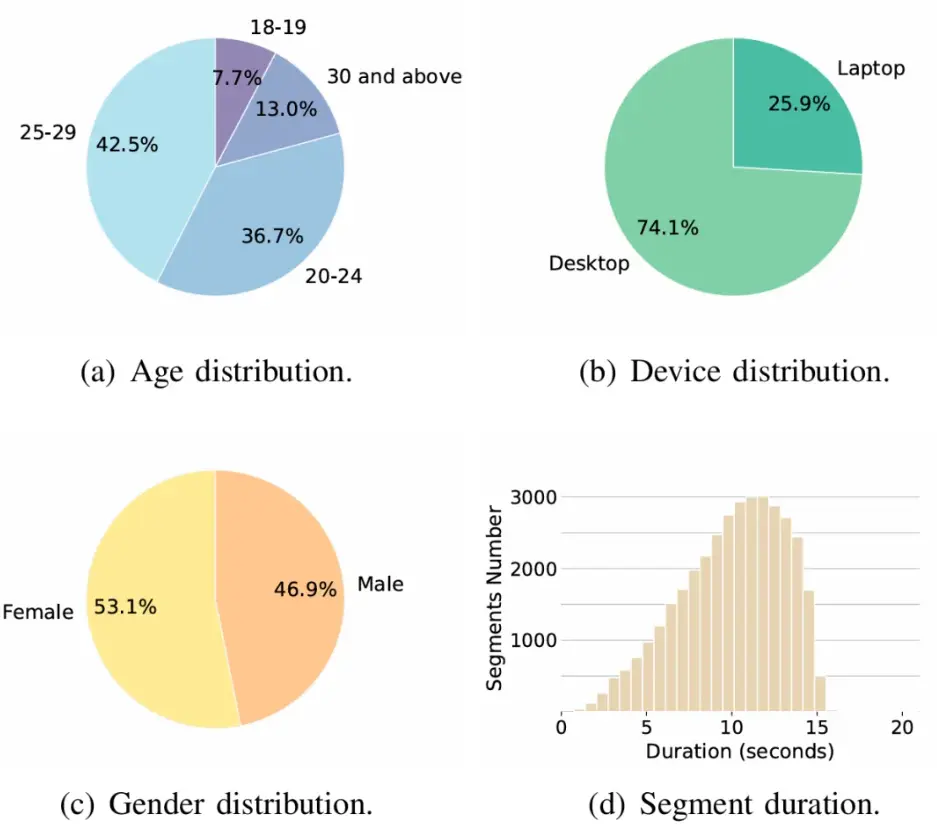
- 数据规模大:Chinese-LiPS总时长约为100小时,包含36,208条高质量语音片段,由207位专业讲者录制,具备良好的代表性与多样性。
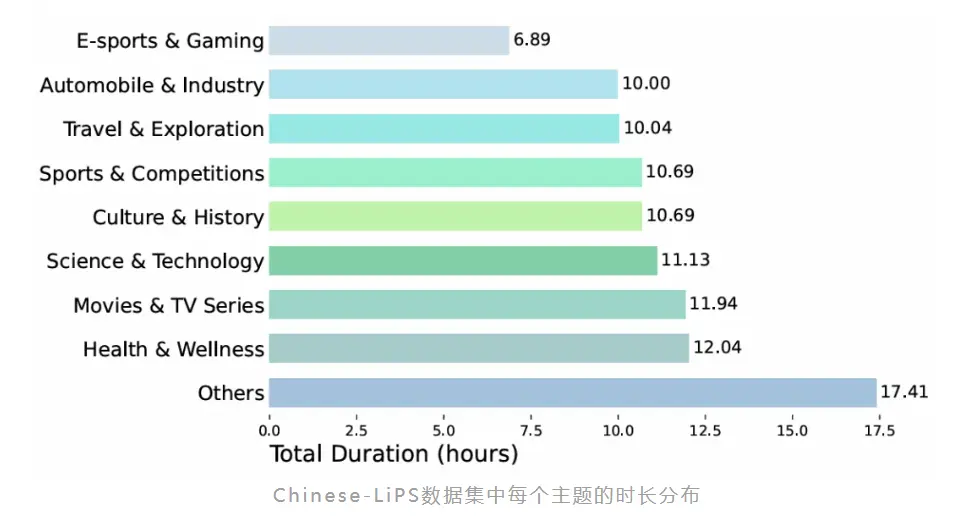
- 覆盖主题丰富:内容涵盖科学技术、健康养生、文化历史、旅游探索、汽车工业、体育赛事等9大热门领域,主题分布均衡,充分体现了真实教学与讲解类语境下的表达特点与术语密度。
- 高质量幻灯片制作:由领域专家设计内容并参与标注,确保幻灯片图文信息的准确性与专业性。PPT内容结构清晰、设计精美,包含丰富的图像与视觉语义信息,而非单一文字堆砌。
- 高质量视频录制:视频由专业讲者在安静环境中录制,画面高清,涵盖唇读视频(720P)与幻灯片视频(1080P)两类模态,保障语音与唇动精准对齐,确保数据质量一致可靠。