智源研究院宣布已发布大型开源文本数据集CCI 4.0,兼顾多样性与高质量,从单一语言数据集扩展为多语种数据集。
根据介绍,本次发布包括了中、英语两种语言,并将在随后的发布中,开源更多语言的版本。此外,CCI 4.0首次采用CoT方法进行推理轨迹数据合成,以提升预训练模型的基础推理能力。
CCI 4.0数据集由智源研究院牵头,联合包括阿里云、上海人工智能实验室、华为、出门问问、金山办公、昆仑万维、面壁智能、奇虎科技、美团、稀宇科技、月之暗面、紫东太初、中科闻歌、科大讯飞等多个机构共同贡献。
智源研究院于2023年11月首次发布中文互联网语料库CCI 1.0,并于2024年3月和10月分别完成CCI2.0和CCI3.0的迭代,系列数据集的下载量已超过14万次,支持500余个企事业单位的大模型研发。
此次开源的CCI 4.0-M2-V1包括3个子数据集,即CCI 4.0-M2-Base V1、CCI 4.0-M2-CoT V1和CCI 4.0-M2-Extra V1,数据总量达35TB。其中,CCI 4.0-M2-Base V1是中英双语数据集,数据总量达26000GB,中文数据量为4300GB,相较于CCI 3.0数据规模增加4倍;CCI 4.0-M2-CoT V1 是中英双语合成数据集,包含用于提升推理能力的超过4亿条逆向合成人类思考轨迹数据,总token数量达425B(4250亿),比当前全球最大的开源合成数据集Cosmopedia规模提升近20倍。
Huggingface地址:
- https://huggingface.co/datasets/BAAI/CCI4.0-M2-Base-v1
- https://huggingface.co/datasets/BAAI/CCI4.0-M2-CoT-v1
- https://huggingface.co/datasets/BAAI/CCI4.0-M2-Extra-v1
针对不同来源的数据,CCI 4.0在建设过程中采取了去重、质量分类、QA合成、loss过滤的处理原则。针对英文数据,进行领域分类和流畅度过滤等处理;针对中文数据,进行全局及分领域来源字符串去重,常规、低质、分领域流畅程度过滤,多种质量打分和分档等处理;针对合成数据,进行语义分段及摘要、总结思维链及合成问题等处理。智源研究院就CCI 4.0数据集开源进行了严格评审,以确保数据安全合规。
CCI 4.0数据集中的英文语料、中文语料及合成数据对模型训练效率及性能均有有效提升。
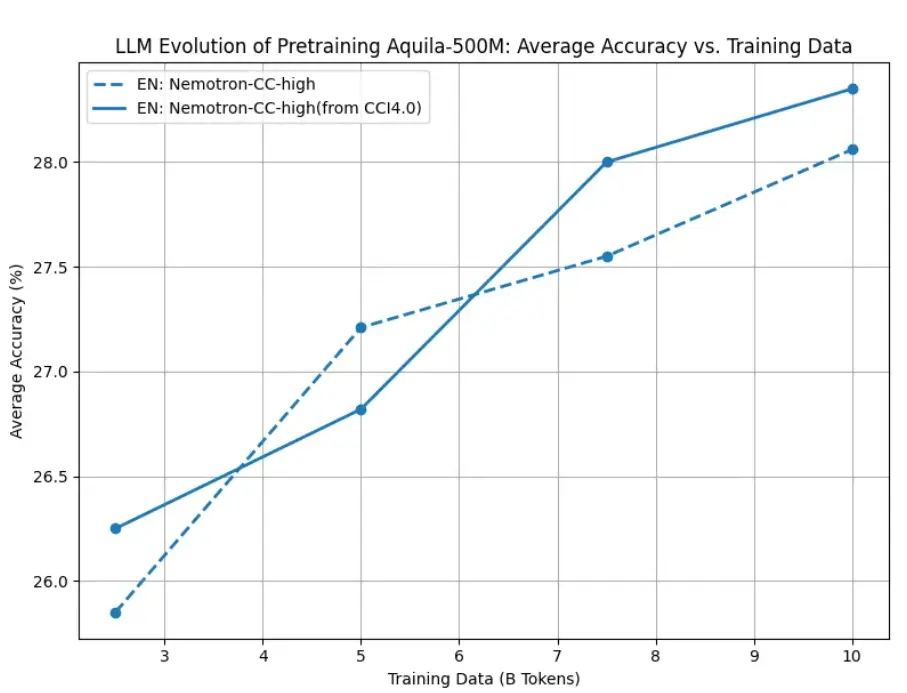
图1:CCI 4.0的数据加工方法在Nemotron-CC高质量数据集的使用前后效果对比
如图1所示,针对相同的英文网页原始语料(Nemotron-CC-high),CCI 4.0设计了基于loss过滤操作的有效性验证实验,通过使用过滤前与过滤后(Nemotron-CC-high from CCI4.0)的英文语料分别训练模型,再进一步对比模型在下游任务上的平均性能表示。结果显示,在训练过程中基于loss过滤的英文语料可在训练过程中提升模型的训练效率。
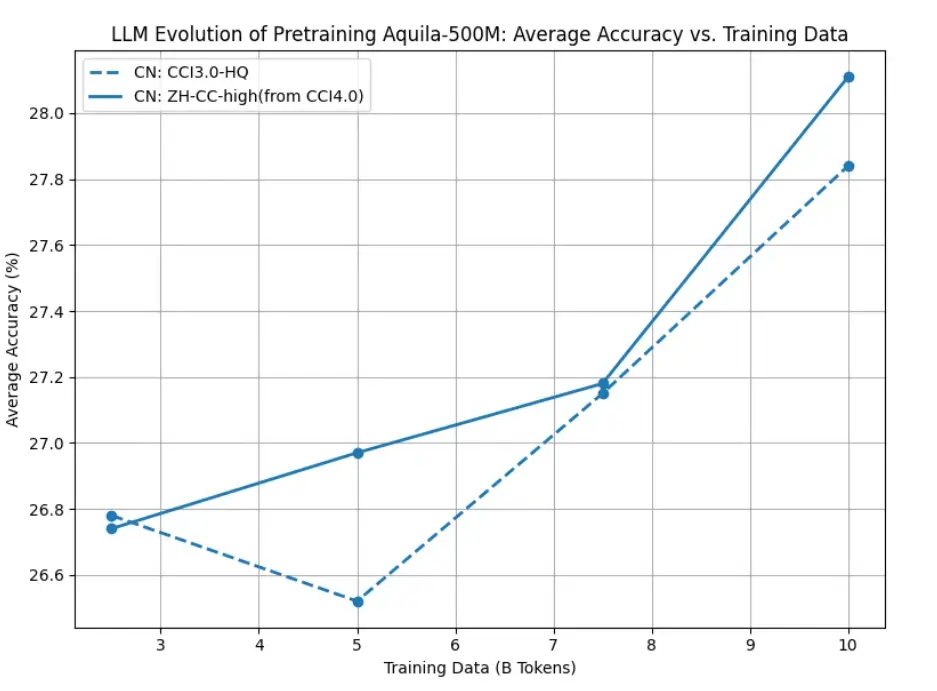
图2:CCI4.0-HQ中文数据集和CCI3.0-HQ数据集在训练500M模型效果上的对比
如图2所示,针对中文语料,设计了中文语料处理有效性的验证实验,以CCI 3.0中的中文网页语料数据作为基线方法进行模型训练表现对比,结果显示,相较于CCI 3.0的高质量中文数据集, CCI 4.0中的高质量中文网页数据仍可继续提升模型的训练效率。
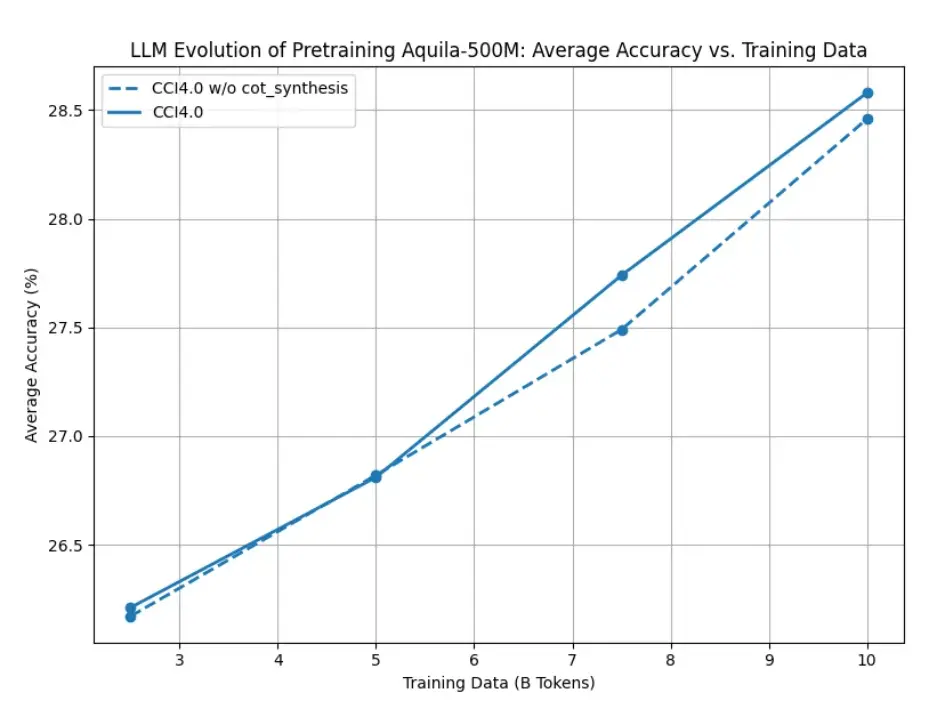
图3:CCI 4.0-M2-CoT合成数据集效果验证
如图3所示,为验证合成数据的作用,设计了合成数据对于模型预训练的性能影响对比实验。分别使用含有合成数据的预训练语料和不含合成数据的预训练语料训练模型,结果显示,含有合成数据的预训练语料可在训练后期增强了模型在下游任务上的表现。