智源研究院联合南开大学计算机学院人类语言技术实验室 HLT Lab 正式发布并开源ChildMandarin和SeniorTalk两大语音数据集,覆盖3-5岁低幼儿童和75岁及以上的超高龄老年人。
“这两项数据集的发布,将为面向儿童与老年人的语音识别、语音理解、语音分析等技术的发展提供宝贵资源,推动智能语音技术进步。”
ChildMandarin 数据集具有以下核心特点:
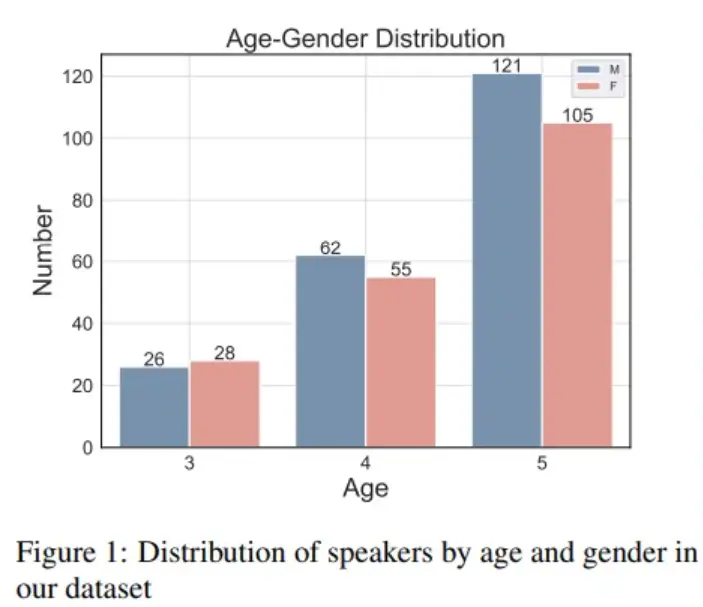
- 数据规模大:397名儿童,共计41.25小时3-5岁对话语音,在同类数据集中具备一定优势;
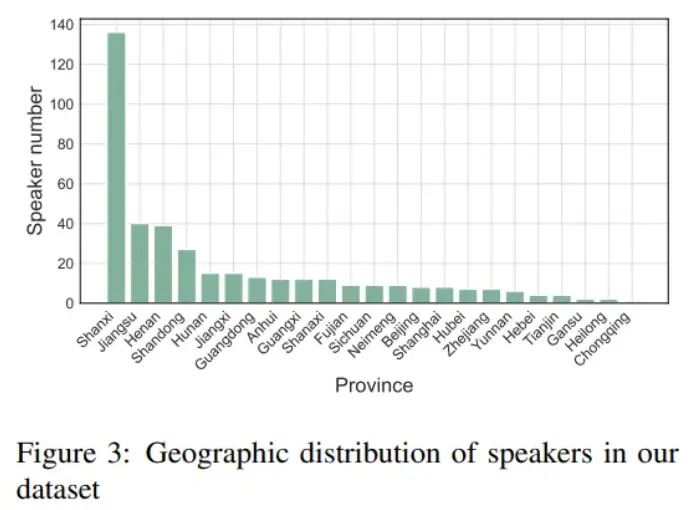
- 地域覆盖广:数据采自22个省市,确保了地域多样性,涵盖不同口音和语音习惯;
- 自然真实交互:采用家长引导式对话的采集方式,以模拟自然交流场景,使语音更具真实性。
SeniorTalk 数据集主要特点包括:
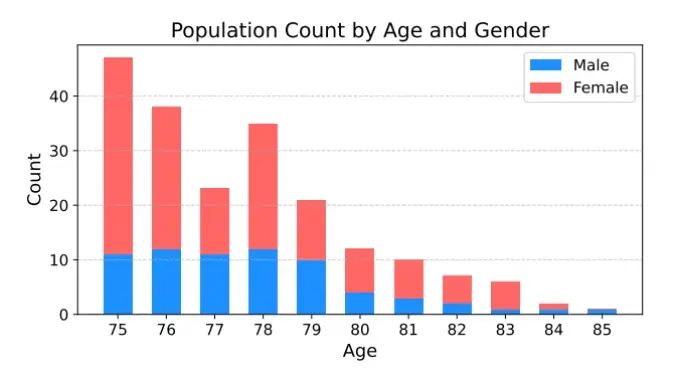
- 数据规模大:202位,55.53小时的超高龄老年人语音数据;
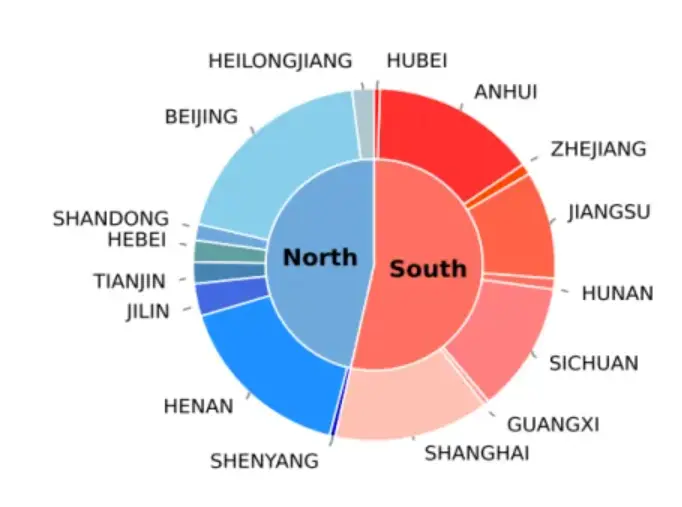
- 地域覆盖广:数据采自16个省市,涵盖不同地域口音;
- 自然真实交互:采用两两自发对话,覆盖退休、健康、生活等话题,贴近真实交流场景。
此外,SeniorTalk包含多维度的精细标注,包括说话人信息、对话内容转写、时间戳(包含句子级和词级)、口音类别标签等。