深言科技与清华大学 NLP 实验室共同研发的语鲸LingoWhale-8B模型已面向社会开源。
深言科技(DeepLang AI)由清华大学计算机系自然语言处理实验室(THUNLP)与北京智源人工智能研究院(BAAI)共同孵化,是国内最早开展大模型研发与探索大模型落地的创业公司之一。公司创始团队曾深度参与智源·悟道大模型的研发,目前已发布产品包括世界首个中文及跨语言反向词典WantWords、名句语义检索系统WantQuotes、智能写作工具深言达意等。
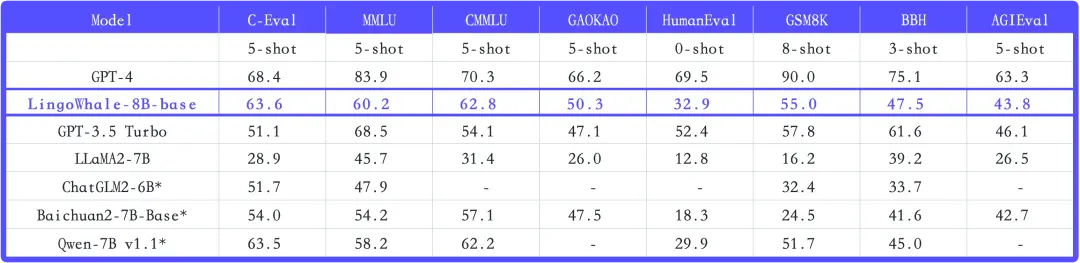
根据介绍,LingoWhale-8B模型是拥有约80亿参数的中英双语大语言模型,在C-Eval、MMLU、CMMLU等多个权威的公开评测基准上,在10B以下开源模型中达到领先效果。
LingoWhale-8B是深言科技与清华大学NLP实验室共同推出的语鲸系列大模型中首个开源的中英双语大语言模型。
LingoWhale-8B模型在数万亿token的高质量中英数据上进行预训练,具有强大的基础能力,在多个公开评测基准上均达到领先效果。在预训练阶段,模型使用8K的上下文长度进行训练,能够完成更长上下文的理解和生成任务。LingoWhale-8B模型对学术研究完全开放,开发者通过邮件申请并获得官方商用许可后,即可免费商用。
在开源模型权重的同时,项目团队也提供了符合用户习惯的Huggingface推理接口以及LoRA等参数高效微调示例,便于开发者快速使用LingoWhale-8B模型。
受模型参数量影响,大模型固有的幻觉问题、数学计算能力相对较弱、生成内容有无法预见性等问题在LingoWhale-8B模型中仍然存在。因此建议在使用前了解这些问题,评估可能存在的风险。后续版本的语鲸大模型将会针对此类问题进行持续优化。
测评分析
截至10月24日,在中文领域权威评测C-Eval中,LingoWhale-8B模型的性能仅次于GPT-4。在C-Eval、CMMLU、GAOKAO测评中,性能超过GPT-3.5Turbo,在10B以下尺寸模型中性能处于领先位置。
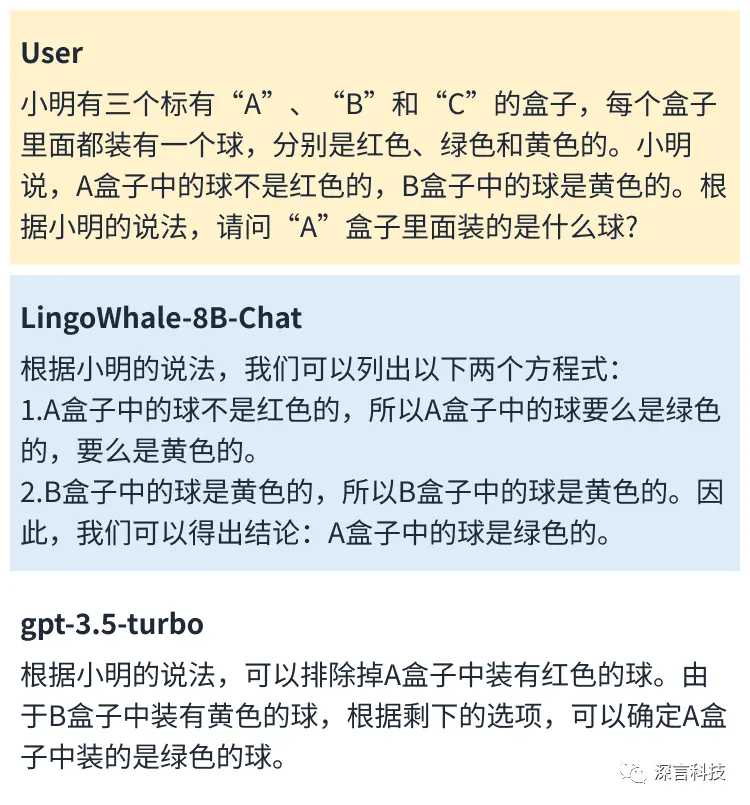
一些示例: