人工智能公司Jina AI 宣布推出其第二代文本嵌入模型: jina-embeddings-v2 。这款模型现在是唯一支持 8K(8192个 token)上下文长度的开源产品。在能力和性能上与OpenAI的 text-embedding-ada-002 相当。
与OpenAI的8K模型 text-embedding-ada-002 进行比较,jina-embedding-v2 在分类平均值、重排平均值、检索平均值和摘要平均值方面超越了 OpenAI 的 text-embedding-ada-002。
| Rank | Model | Model Size (GB) | Embedding Dimensions | Sequence Length | Average (56 datasets) | Classification Average (12 datasets) | Reranking Average (4 datasets) | Retrieval Average (15 datasets) | Summarization Average (1 dataset) |
|---|---|---|---|---|---|---|---|---|---|
| 15 | text-embedding-ada-002 | Unknown | 1536 | 8191 | 60.99 | 70.93 | 84.89 | 56.32 | 30.8 |
| 17 | jina-embeddings-v2-base-en | 0.27 | 768 | 8192 | 60.38 | 73.45 | 85.38 | 56.98 | 31.6 |
text-embedding-ada-002 的特点:
- 从零到卓越:这个
jina-embeddings-v2是从头开始构建的。在过去的三个月里,Jina AI的团队进行了密集的研发、数据收集和调整。 - 利用8K解锁扩展上下文潜力:
jina-embeddings-v28K的上下文长度为新的行业应用开启了大门:- 法律文件分析:确保对大量法律文本中的每一个细节进行捕捉和分析。
- 医学研究:为了进行高级分析和发现,全面地嵌入科学论文。
- 文学分析:深入研究长篇内容,捕捉微妙的主题元素。
- 财务预测:通过详细的财务报告获得卓越的洞察力。
- 会话式AI:提升聊天机器人对复杂用户查询的响应能力。
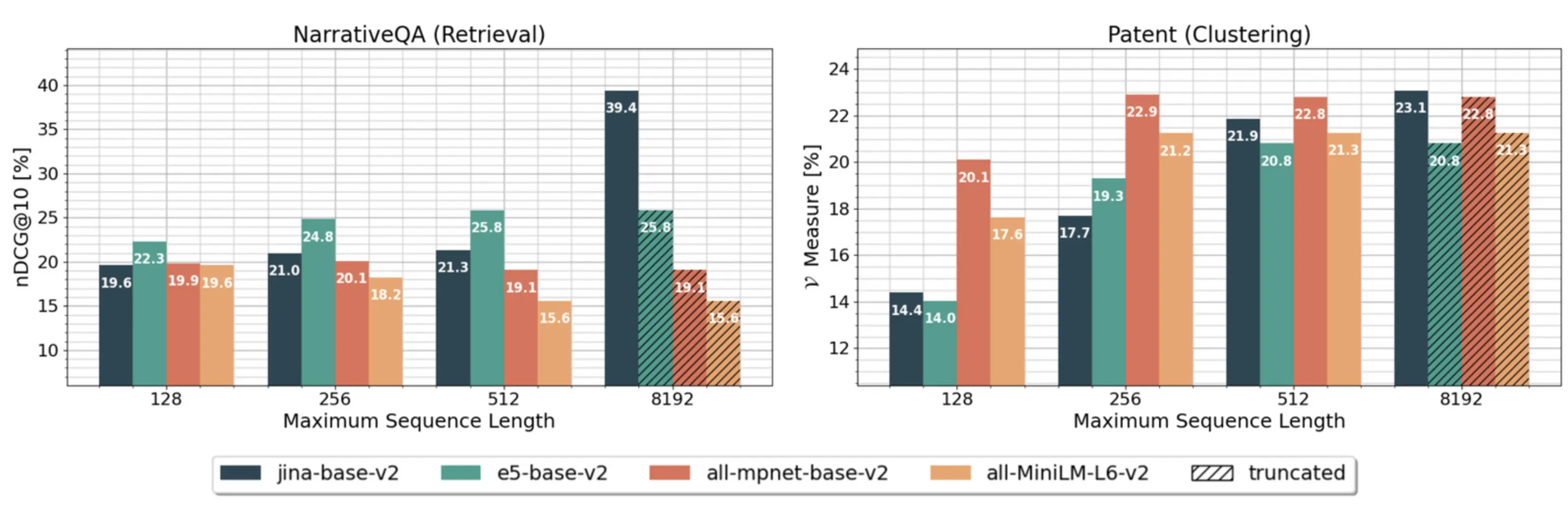
同时,基准测试显示,在多个数据集中,这种 8K 上下文长度的扩展使得jina-embeddings-v2超越了其它领先的嵌入模型:
接下来,Jina 将会有一篇相关的学术洞察文章发表。同时团队正在开发类似OpenAI的嵌入式API平台的产品;语言方面,正在进入多语种嵌入领域,目标是推出德英模型。