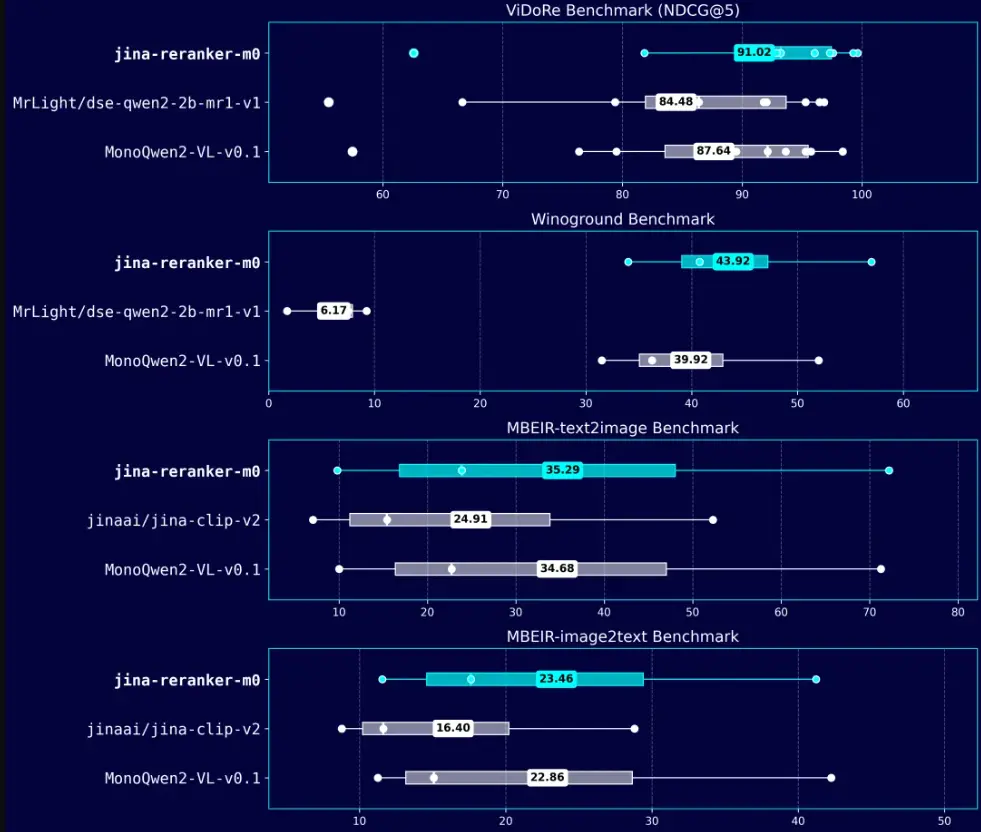
Jina AI 正式发布jina-reranker-m0,一款多模态、多语言重排器(reranker),核心能力在于 对包含丰富视觉元素的文档进行重排和精排,同时兼容跨语言场景。
根据介绍,当用户输入一个查询(query)以及一堆包含文本、图表、表格、信息图或复杂布局的文档时,模型会根据文档与查询的相关性,输出一个排序好的文档列表。模型支持超过 29 种语言及多种图形文档样式,例如自然照片、截图、扫描件、表格、海报、幻灯片、印刷品等等。
相较于前代纯文本的重排器 jina-reranker-v2-base-multilingual,jina-reranker-m0 不仅新增了处理视觉信息的能力,在纯文本重排场景下,针对多语言内容、长文档及代码搜索等任务,其性能也得到了进一步提升。

全新架构
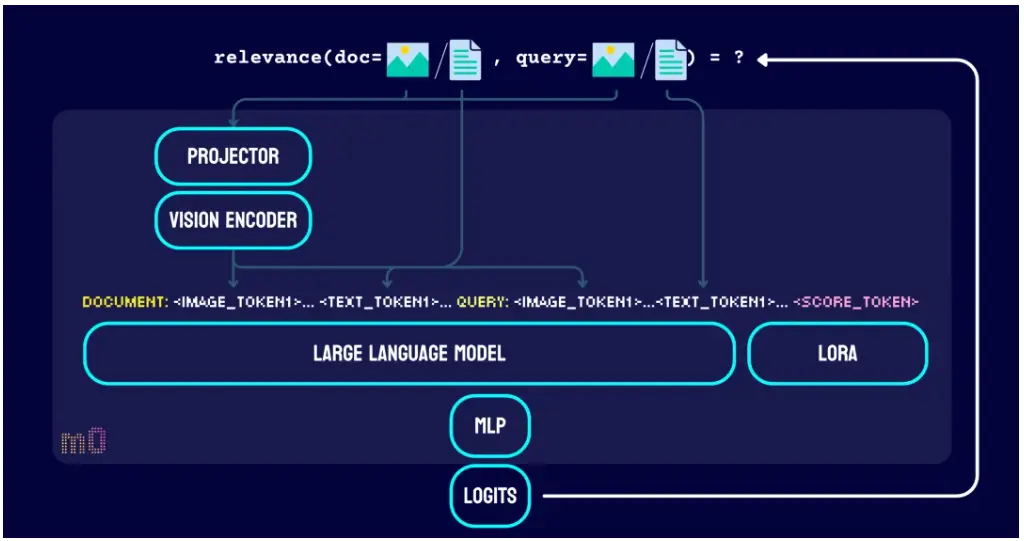
jina-reranker-m0 的模型架构基于 Qwen2-VL-2B 构建的,总参数量达到 24 亿。该模型采用成对比较(pairwise comparison)机制,能够同时评估输入文档里的视觉和文本元素与查询的相关性,进而实现高效的文档排序。
跟 jina-reranker-v2-base-multilingual 不一样,jina-reranker-m0 不再使用经典的交叉编码器(cross-encoder)架构,而是转向了仅解码器(decoder-only)的视觉语言模型。
它复用了 Qwen2-VL 预训练模型中的视觉编码器(vision encoder)和映射(projector),用 LoRA 对其中的大语言模型(LLM)部分进行了微调,并且在之后额外训练了一个多层感知机(MLP),专门用于生成表征查询-文档相关性的排序分数(ranking logits)。通过这种设计,我们构建了一个专门针对排序任务优化的判别式模型(discriminative model)。
| 特性 |
jina-reranker-m0 |
jina-reranker-v2 |
|---|---|---|
| 架构 |
视觉语言模型 (Vision Language Model) |
交叉编码器 (Cross-Encoder) |
| 基础模型 |
Qwen2-VL-2B |
Jina-XLM-RoBERTa |
| 参数量 |
24 亿 |
2.78 亿 |
| 最大上下文长度 (查询 + 文档) |
10,240 tokens |
8,192 tokens |
| 最大图像块数 (动态分辨率,每个块 28x28) |
768 |
❌ (不支持) |
| 多语言支持 |
✅ |
✅ |
| 支持的任务类型 |
文搜文, 文搜图, 图搜文, 文搜混合模态 |
文搜文 |
这个新架构让 jina-reranker-m0 能处理长达 32K token 的输入,并且能无缝地结合图片和文本输入。模型支持的图片尺寸范围很广,从最小的 56×56 像素到高达 4K 分辨率的图片都没问题。处理图片时,ViT(Vision Transformer)和投影器协同工作,把相邻的 2×2 token 压缩成单个视觉 token,再输入给大语言模型。
像 <|vision_start|> 和 <|vision_end|> 这样的特殊 token 用来明确标示出视觉 token 的边界,让语言模型能准确解析视觉信息,并把视觉和文本元素整合起来,进行复杂的多模态推理。
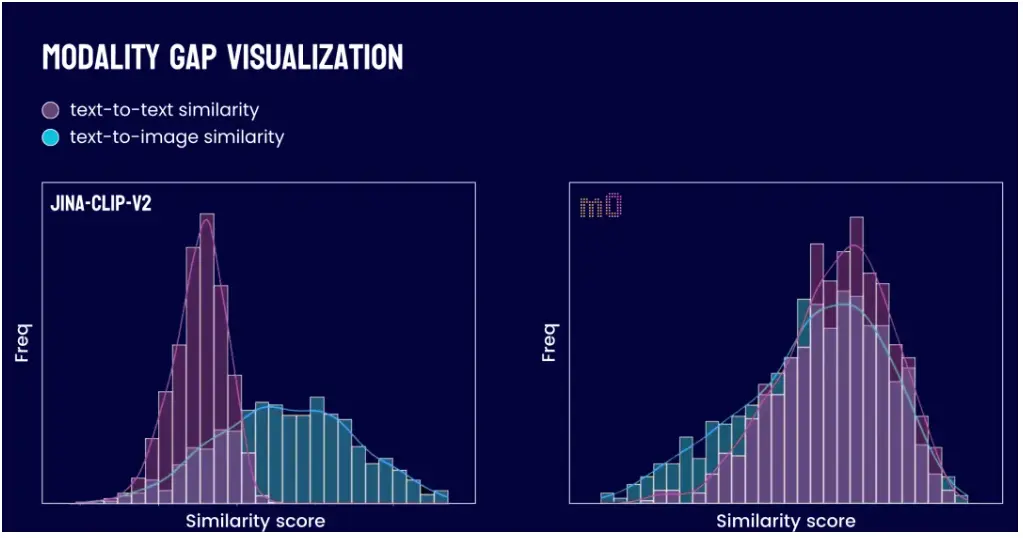
此架构还有效地缓解了模态鸿沟(modality gap)问题。这一问题曾困扰如 jina-clip-v1 和 jina-clip-v2 等早期模型。在那些模型中,图像向量倾向于与图像向量聚集,文本向量则与文本向量扎堆,导致两者在表征空间中形成分离,存在一道鸿沟。这就导致当你的候选文档既有图片又有文本时,用文本查询来检索图片效果就不好。有了 jina-reranker-m0,你现在可以放心把图像和文档放在一起排序,不需要担心模态鸿沟,实现真正的统一多模态搜索体验。
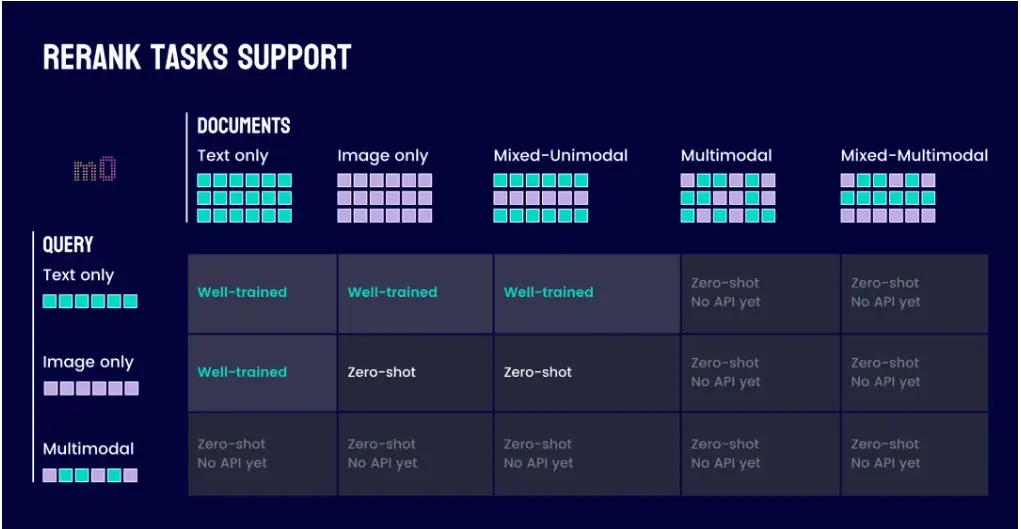
jina-reranker-m0 支持多种查询和文档输入组合来进行重排。经过显式训练与优化,在以下任务上达到了行业顶尖(state-of-the-art,SOTA)水平:
- 文本到文本 (Text-to-Text)
- 文本到图像 (Text-to-Image)
- 图像到文本 (Image-to-Text)
- 文本到混合单模态文档 (Text-to-Mixed-Unimodal):指使用文本查询对一个同时包含纯文本文档和纯图像文档的候选集进行统一排序
对于其他的输入组合(如图像到图像、图像到多模态文档、文本到多模态文档),模型也具备零样本(zero-shot)处理能力,底层架构兼容这些模态组合的输入,只是训练阶段没有针对这些模态组合进行优化设计。