Jina AI 宣布正式推出 jina-embeddings-v4,一款全新的多模态向量模型,参数规模达到 38 亿,并首次实现了对文本与图像的同步处理。
项目团队在模型内置了一套面向特定任务的 LoRA 适配器,专门强化了模型在处理查询-文档检索、语义匹配以及代码搜索等任务时的表现。
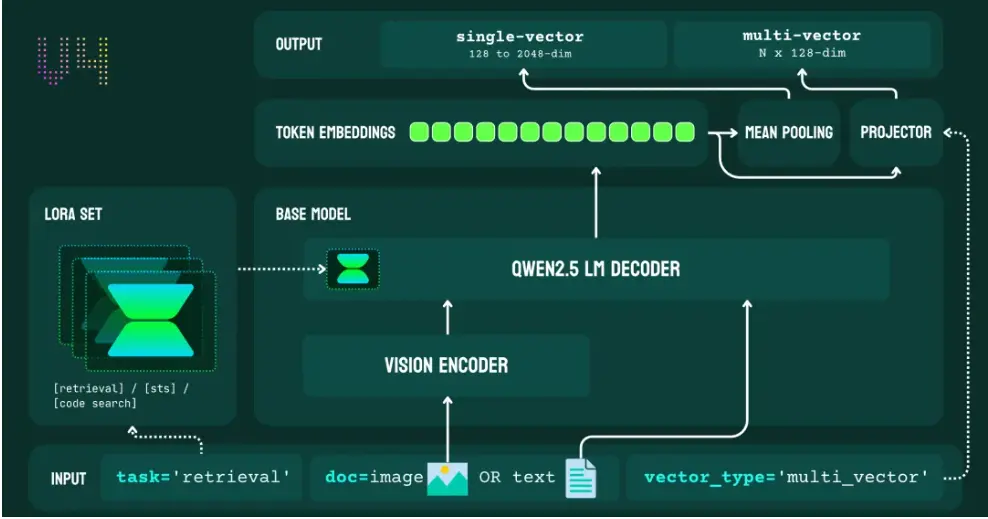
公告称,在 MTEB、MMTEB、CoIR、LongEmbed、STS、Jina-VDR 及 ViDoRe 等多项基准测试中,jina-embeddings-v4 在多模态、多语言检索任务上均展现了顶尖性能。它尤其擅长解读富含视觉信息的内容,无论是表格、图表还是复杂的示意图,都能精准捕捉其深层语义。此外,模型还同时支持单向量和多向量表示,灵活满足各种场景需求。
“jina-embeddings-v4 是我们迄今为止最具突破性的一款向量模型。作为一款开源模型,它的性能表现已全面超越来自主流供应商的顶尖闭源模型。”
- 在多语言检索方面,其性能比 OpenAI 的 text-embedding-3-large 高出 12%(66.49 vs 59.27)。
- 在长文档任务上,性能提升了 28%(67.11 vs 52.42)。
- 在代码检索方面,效果比 voyage-3 好 15%(71.59 vs 67.23)
- 综合性能与谷歌的 gemini-embedding-001 模型并驾齐驱
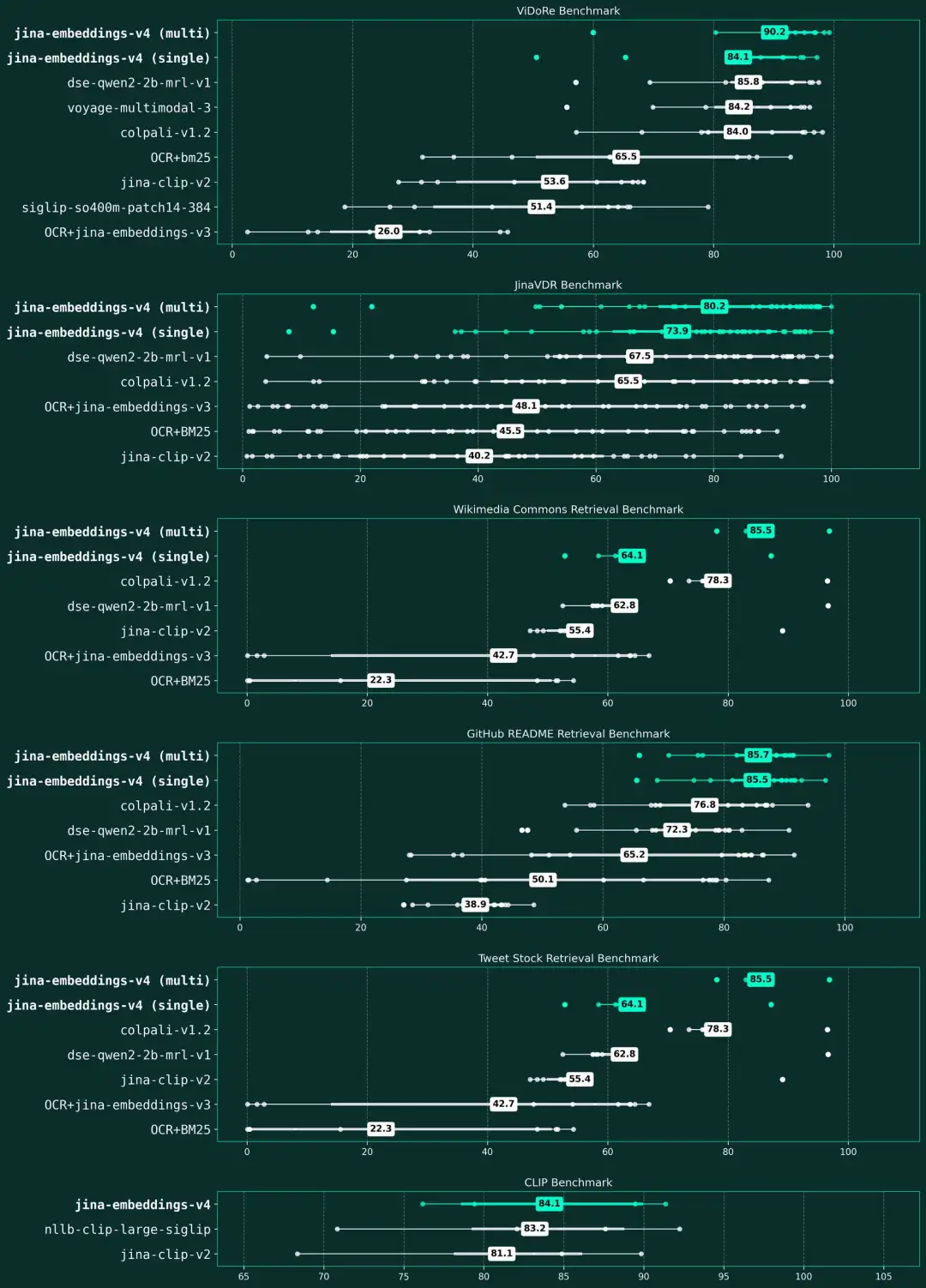
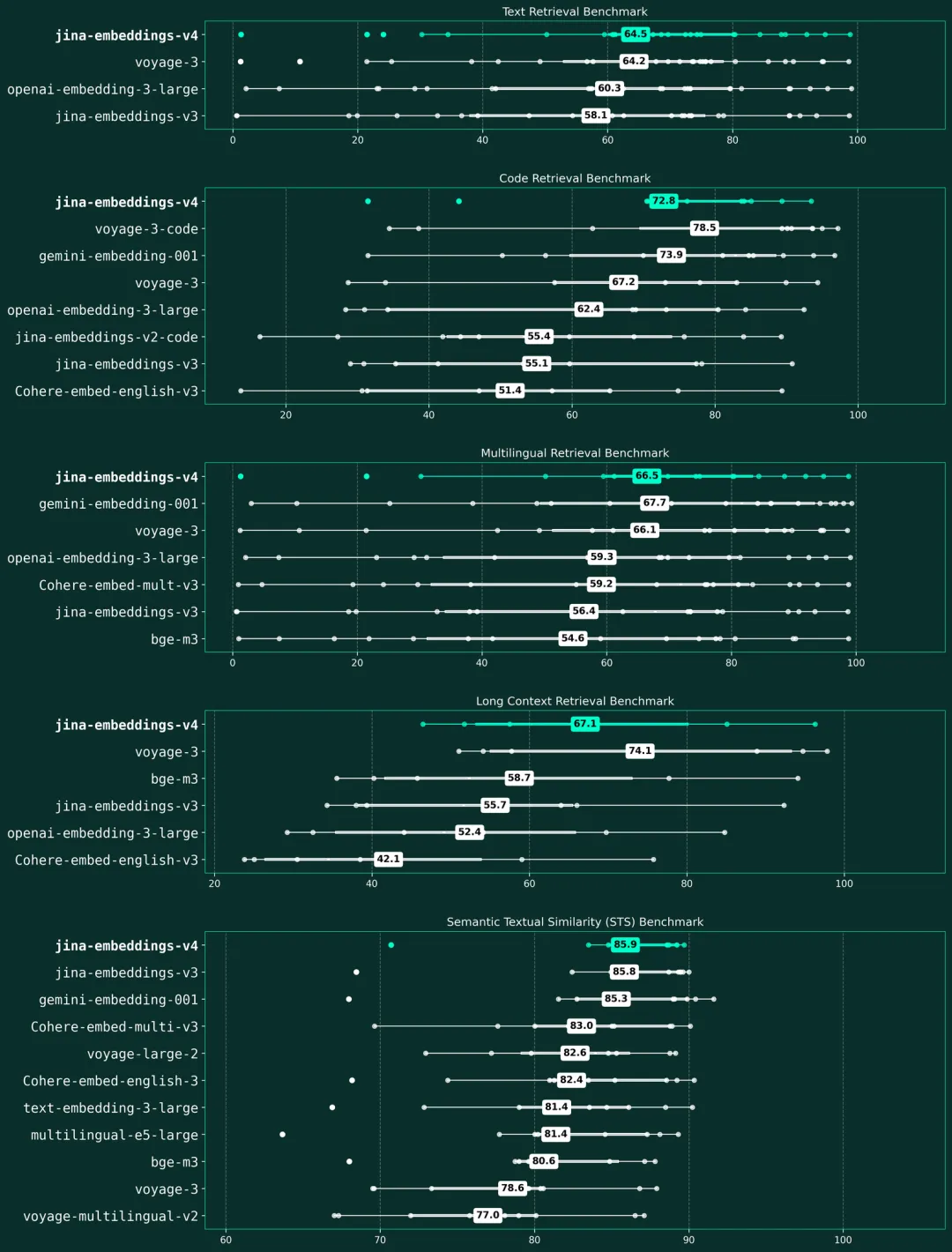
更多详情可查看官方公告。