MiniMax 宣布开源 MiniMax-M1 模型,据称是全球首款开放权重的大规模混合注意力推理模型。
开源地址:
https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
https://github.com/MiniMax-AI/MiniMax-M1
模型亮点:
- 模型采用 MoE 与 lightning attention 相结合架构
- 模型大小为456B ,单 token 激活参数为 45.9 B
- M1 原生支持 100 万 token 的上下文长度
- 包含 40K 和 80K 思维预算两个推理模型
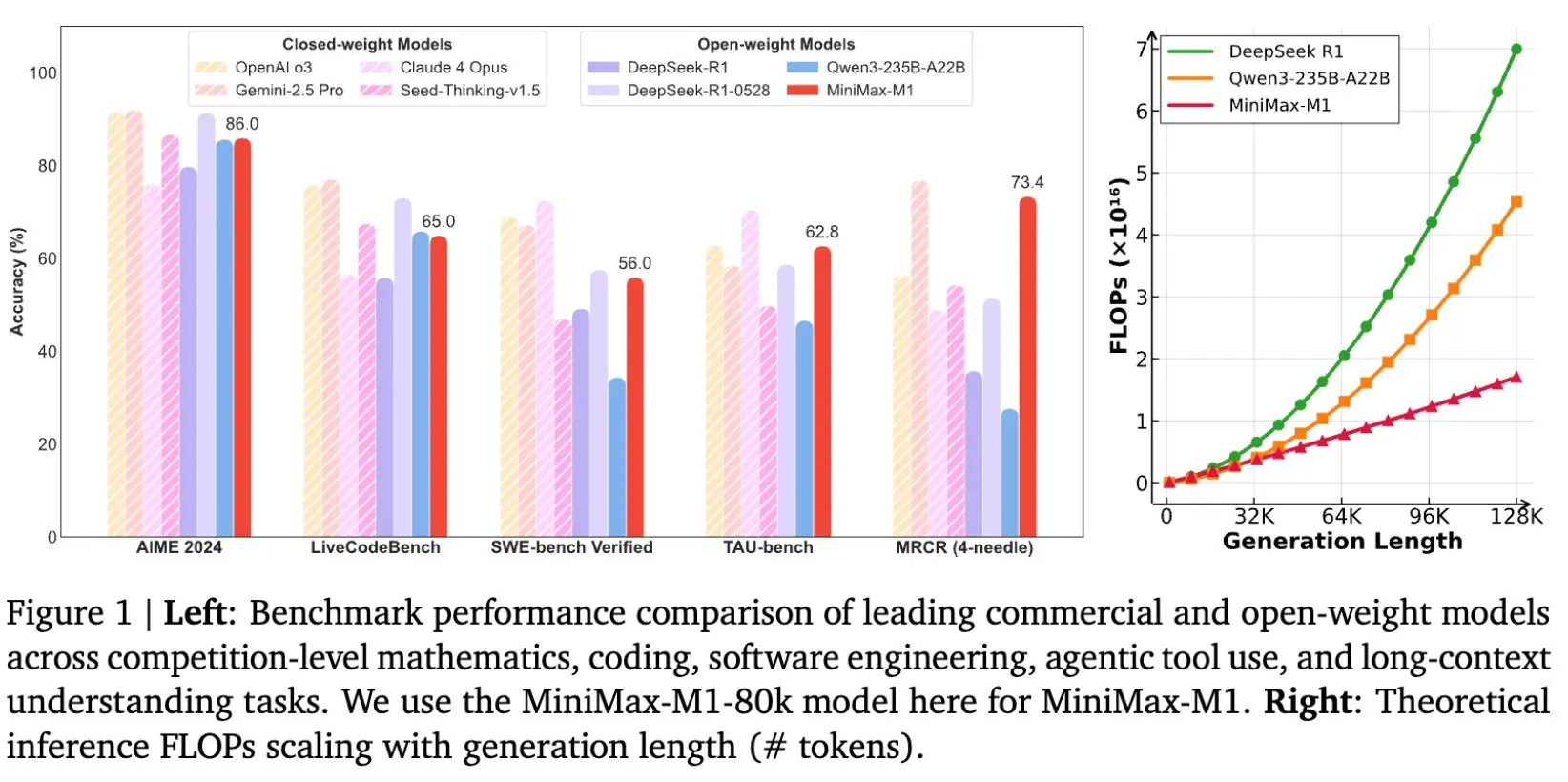
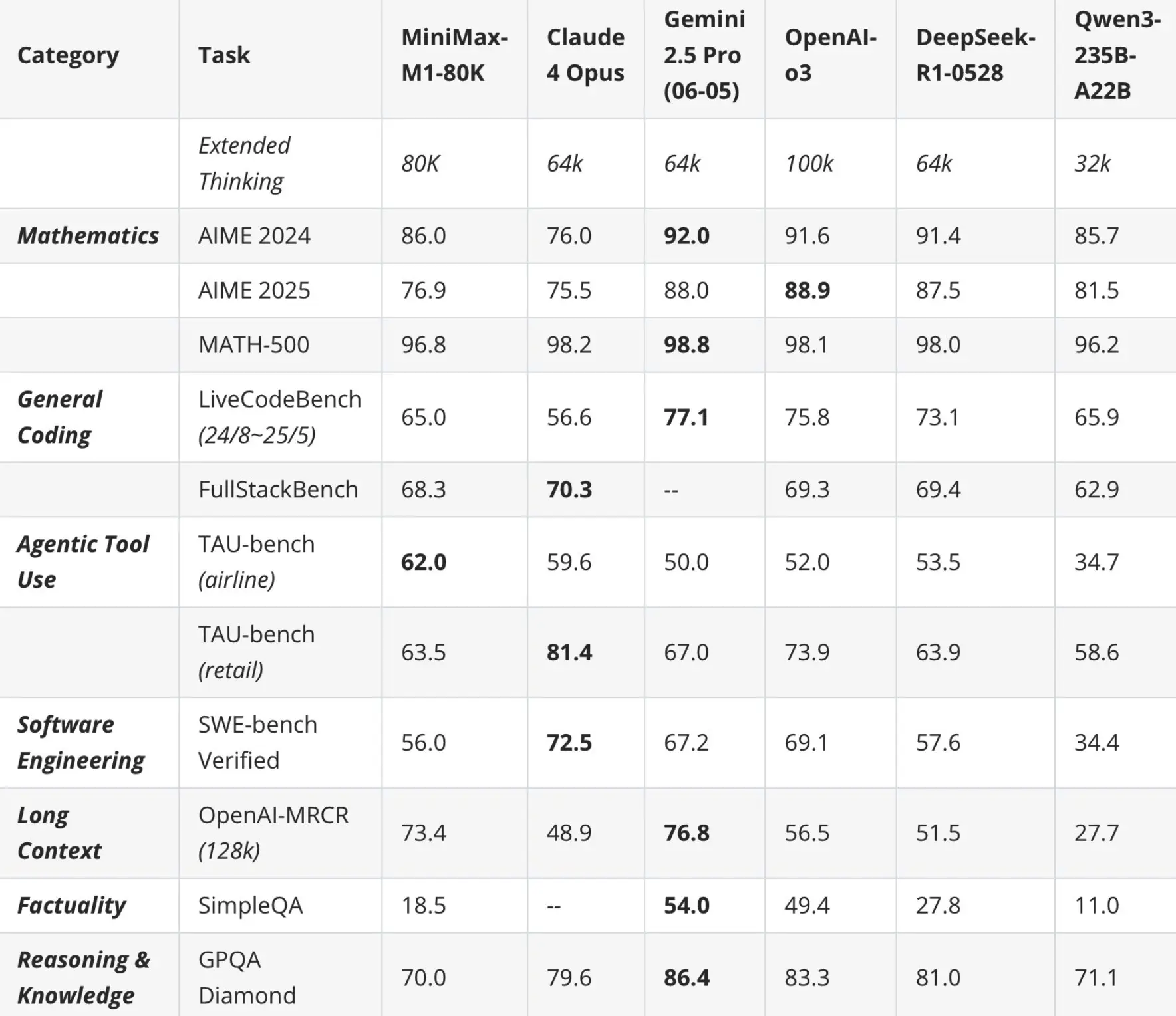
该模型基于 MiniMax-Text-01 模型开发,采用了混合专家模型(MoE)架构并结合了闪电注意力机制。M1 的总参数量高达 4560 亿,每个词元激活 459 亿参数,原生支持 100 万词元的上下文长度,是 DeepSeek R1 上下文大小的 8 倍。
其闪电注意力机制能高效扩展测试时计算,在生成 10 万词元时,M1 的浮点运算次数(FLOPs)仅为 DeepSeek R1 的 25%。这些特性使其特别适用于需要处理长输入和深度思考的复杂任务。