继开源 Skywork-R1V 后,昆仑万维宣布再开源多模态推理模型的全新升级版本 —— Skywork-R1V 2.0(简称 R1V 2.0) 。
公告称,Skywork-R1V 2.0 是当前最均衡兼顾视觉与文本推理能力的开源多模态模型,该多模态模型在高考理科难题的深度推理与通用任务场景中均表现优异,真正实现多模态大模型的“深度 + 广度”统一。
R1V 2.0 模型亮点:
- 中文场景领跑:理科学科题目(数学/物理/化学)推理效果拔群,打造免费AI解题助手;
- 开源巅峰:38B 权重 + 技术报告全面开源,推动多模态生态建设;
- 技术创新标杆:多模态奖励模型(Skywork‑VL Reward) 与 混合偏好优化机制(MPO),全面提升模型泛化能力;选择性样本缓冲区机制(SSB),突破强化学习“优势消失”瓶颈。
基准测试结果表明,R1V 2.0 相较于 R1V 1.0 在文本与视觉推理任务中均实现显著跃升。
- 在 MMMU 上取得 73.6 分,刷新开源 SOTA 纪录;
- 在 Olympiad Bench 上达到 62.6 分,显著领先其他开源模型;
- 在 MathVision、MMMU-PRO 与 MathVista 等多项视觉推理榜单中均表现优异,多项能力已可媲美闭源商业模型,堪称当前开源多模态推理模型中的佼佼者。
在文本推理方面,在 AIME2024 和 LiveCodeBench 等挑战中,R1V 2.0 分别取得了78.9 分和 63.6 分,展现出了人类专家级数学与代码理解能力。在与专用文本推理模型对比中,R1V2.0 同样展现出卓越的文本推理能力。
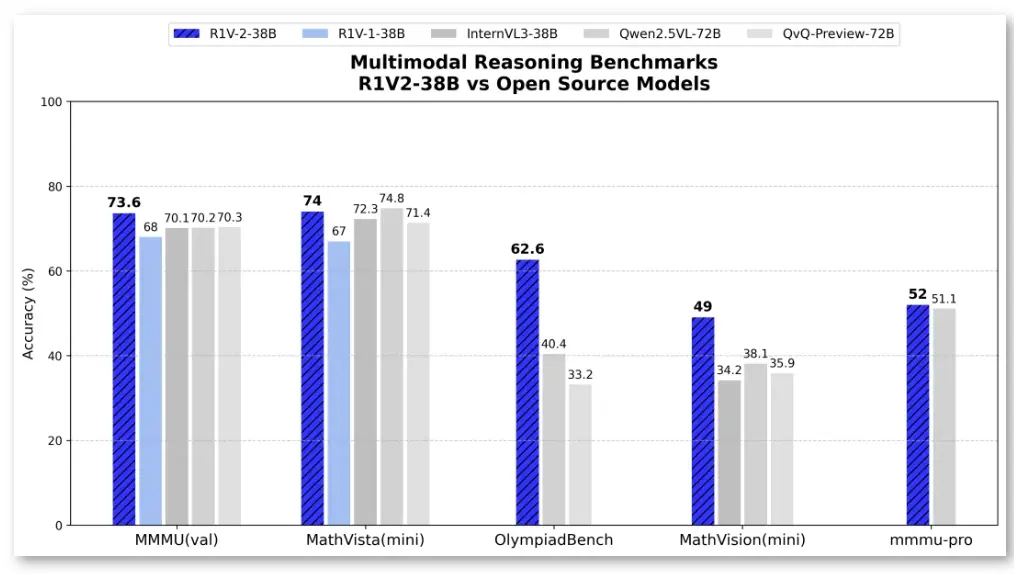
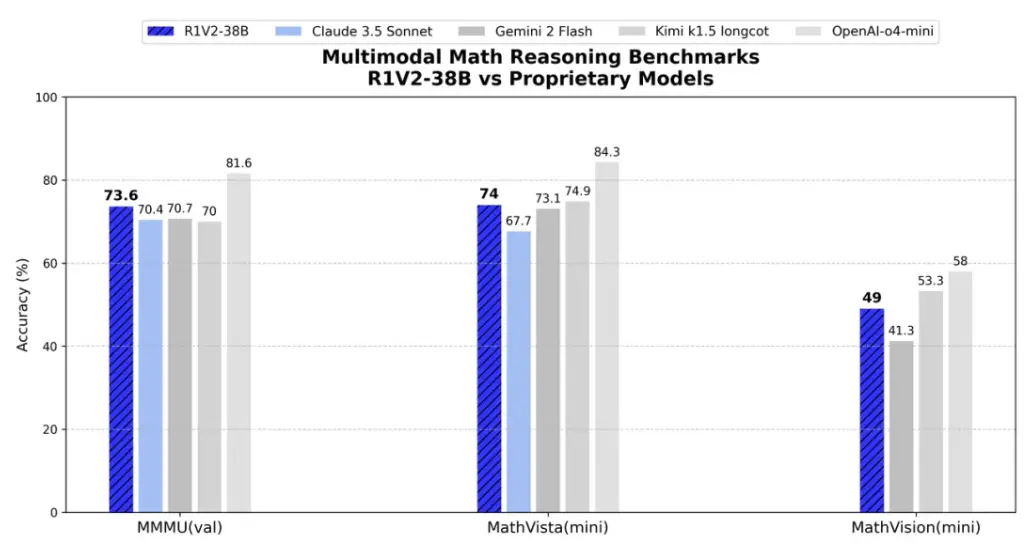
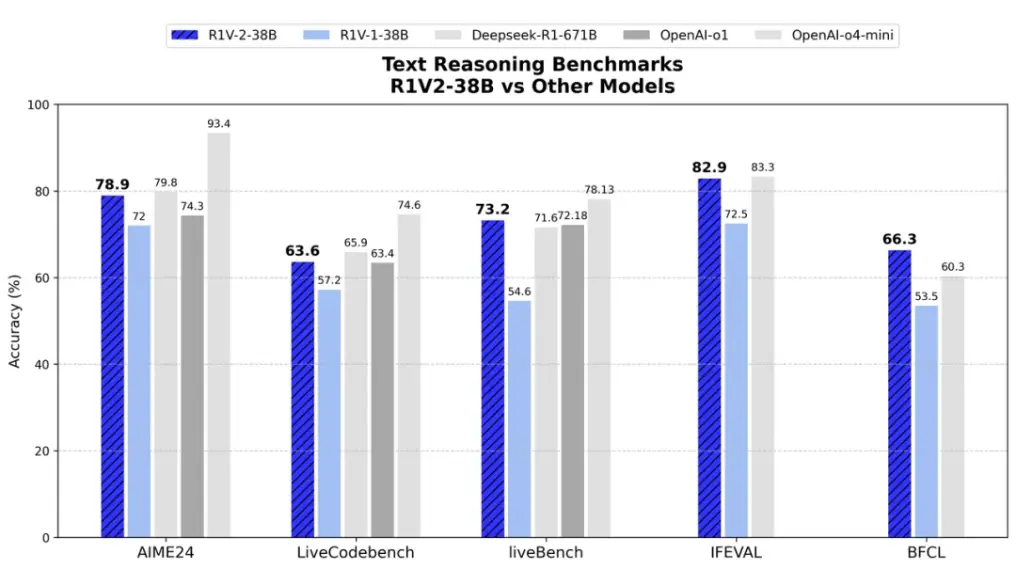
R1V 2.0 引入了全新的「多模态奖励模型 Skywork-VL Reward」及「规则驱动的混合强化训练机制」。在显著增强推理能力的同时,进一步稳固了模型在多任务、多模态场景中的稳定表现与泛化能力。
Skywork-VL Reward 在多个权威评测榜单中表现优异:在视觉奖励模型评测榜单 VL-RewardBench 中取得了 73.1 的SOTA成绩,同时在纯文本奖励模型评测榜单 RewardBench 中也斩获了高达 90.1 的优异分数。
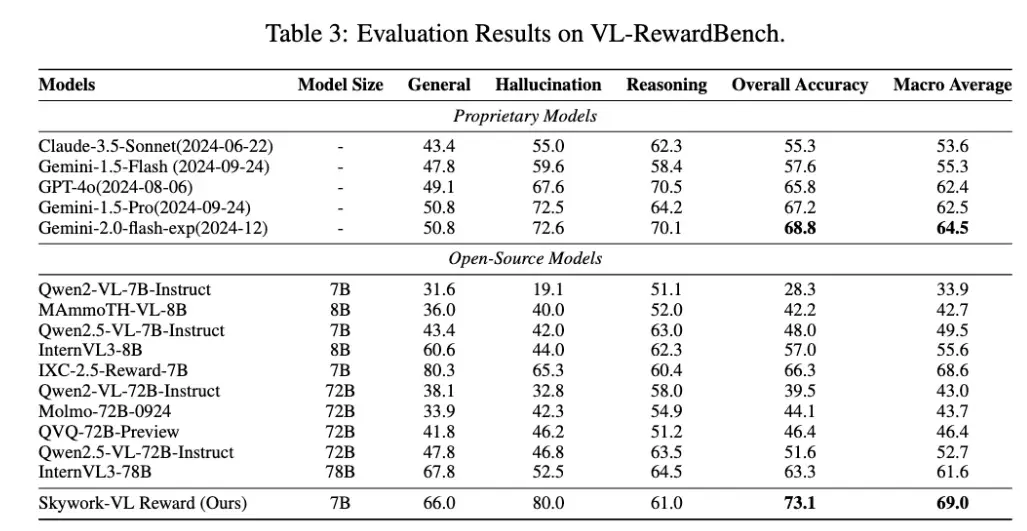
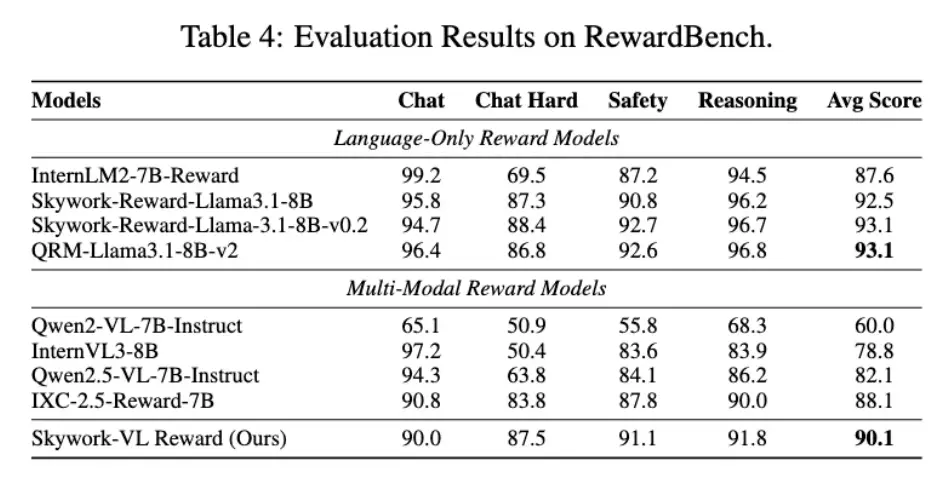
目前,Skywork-VL Reward 也已完整开源。
此外,R1V 2.0 还引入了 MPO(Mixed Preference Optimization,混合偏好优化) 机制,并在偏好训练中充分发挥 Skywork-VL Reward 奖励模型的指导作用。