腾讯宣布开源混元大模型家族的新成员——混元-A13B模型。该模型采用基于专家混合(MoE)架构,总参数规模达800亿,激活参数为130亿。
公告称,该模型在保持顶尖开源模型效果的同时,大幅降低了推理延迟与计算开销。对个人开发者和中小企业来说,极端条件下仅需1张中低端GPU卡即可部署。
在性能表现上,混元-A13B模型在数学、科学和逻辑推理任务中展现出领先效果。例如,在数学推理测试中,模型能够准确完成小数比较并展现分步解析能力。对于时下热门的智能体(Agent)应用,模型可调用工具,高效生成出行攻略、数据文件分析等复杂指令响应。
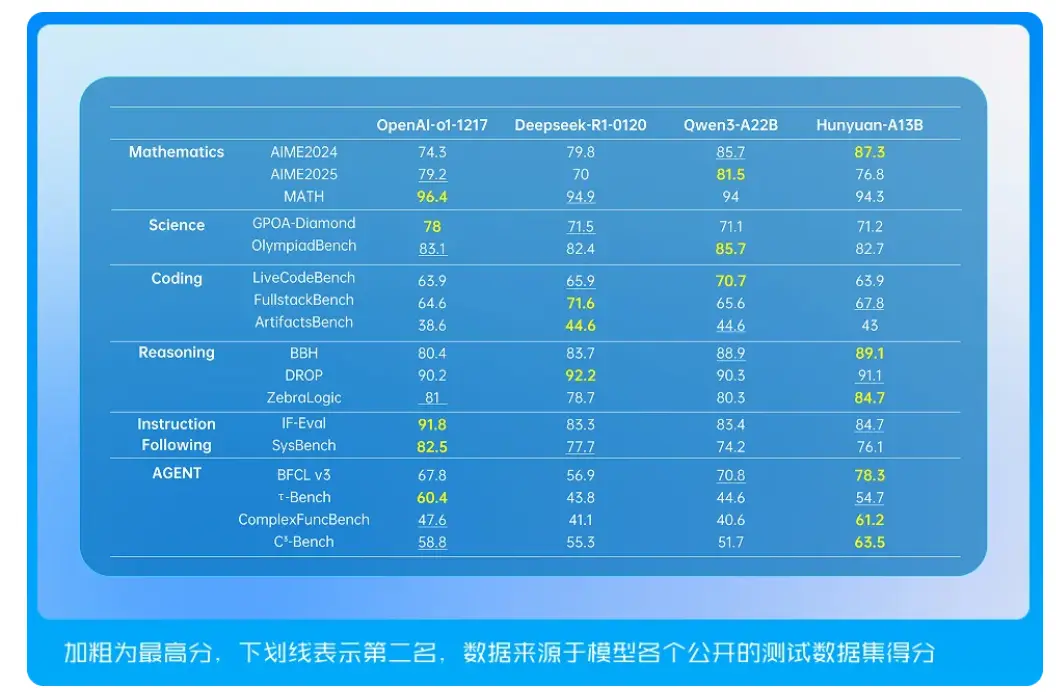
根据介绍,预训练中,混元-A13B模型使用了20万亿高质量网络词元语料库,提升了模型推理能力的上限;完善了MoE 架构的 Scaling Law (即规模定律)理论体系,为 MoE 架构设计提供了可量化的工程化指导,提升了模型预训练效果。
用户可以按需选择思考模式,快思考模式提供简洁、高效的输出,适合追求速度和最小计算开销的简单任务;慢思考模式涉及更深、更全面的推理步骤。这优化了计算资源分配,兼顾效率和准确性。
此外,混元还开源了两个新数据集。其中,ArtifactsBench主要用于代码评估,构建了一个包含 1825个任务的新基准;C3-Bench针对Agent场景模型评估,设计了1024条测试数据,以发现模型能力的不足。