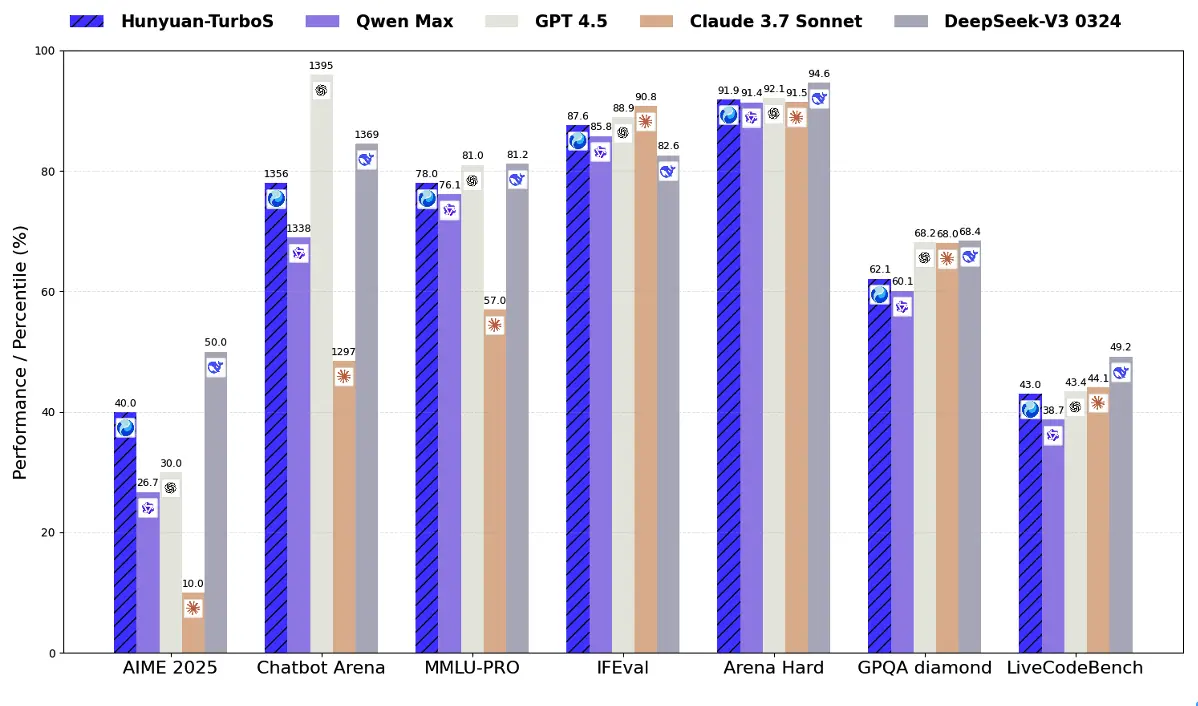
年初,腾讯混元 TurboS “快思考模型”正式发布,作为业界首款大规模混合 Mamba-MoE 模型,其在效果与性能上展现了出显著优势。这一突破得益于预训练阶段的 tokens 增训,以及后训练阶段引入长短思维链融合技术。
近日,腾讯混元 TurboS 发布了技术报告,其模型架构如下:

据介绍,腾讯混元 TurboS 核心创新体现在以下几个方面:
架构协同:巧妙地融合了Mamba架构处理长序列的高效性与Transformer架构卓越的上下文理解能力。这两种架构的结合,旨在取长补短,实现性能与效率的最大化。模型包含128层,采用了创新的“AMF”(Attention → Mamba2 → FFN)和“MF”(Mamba2 → FFN)模块交错模式。这种设计使得模型在拥有5600亿总参数(56B激活参数)的同时,保持了较高的运算效率。
自适应思维链 (Adaptive Long-short CoT):该机制是Hunyuan-TurboS的一大亮点。它借鉴了短思维链模型(如GPT-4o)的快速响应和计算友好特性,以及长思维链模型(如o3)强大的复杂推理能力。面对简单问题,TurboS自动激活“无思考”(no thinking)模式,以最小计算成本提供足够质量的答案;而当遇到复杂问题时,则自动切换至“思考”(thinking)模式,运用逐步分析、自我反思和回溯等深度推理方法,给出高准确度的回答。
先进的后训练策略:为了进一步增强模型能力,腾讯混元团队设计了包含四个关键模块的后训练流程:
1、监督微调(SFT):通过精心构建的百万级自然和合成指令数据进行微调。
2、自适应长短CoT融合:通过专门训练的教师模型和独特的强化学习框架,实现推理策略的自主选择、计算资源的有效分配,并通过无损压缩和重构长思维链来提升响应的可读性。
3、多轮推敲学习(Multi-round Deliberation Learning):SFT模型在模拟评估环境中与其他先进混元模型进行比较,通过多LLM裁判组和人类专家的评估驱动迭代优化。
4、两阶段大规模强化学习:利用GRPO,第一阶段聚焦于提升推理能力,第二阶段则致力于改善全领域的通用指令遵循能力。
详情查看论文:https://arxiv.org/abs/2505.15431