星动纪元宣布已与清华大学叉院的 ISRLab 合作,开源了首个 AIGC 生成式机器人大模型 VPP(Video Prediction Policy)。“利用预训练视频生成大模型,让 AIGC 的魔力从数字世界走进具身智能的物理世界,就好比机器人界的 Sora!”
-
论文地址:https://arxiv.org/pdf/2412.14803
根据介绍,VPP 利用了大量互联网视频数据进行训练,直接学习人类动作,极大减轻了对于高质量机器人真机数据的依赖,且可在不同人形机器人本体之间自如切换,这有望大大加速人形机器人的商业化落地。
VPP 将视频扩散模型的泛化能力转移到了通用机器人操作策略中,巧妙解决了 diffusion 推理速度的问题,开创性地让机器人实时进行未来预测和动作执行,大大提升机器人策略泛化性,并且现已全部开源。
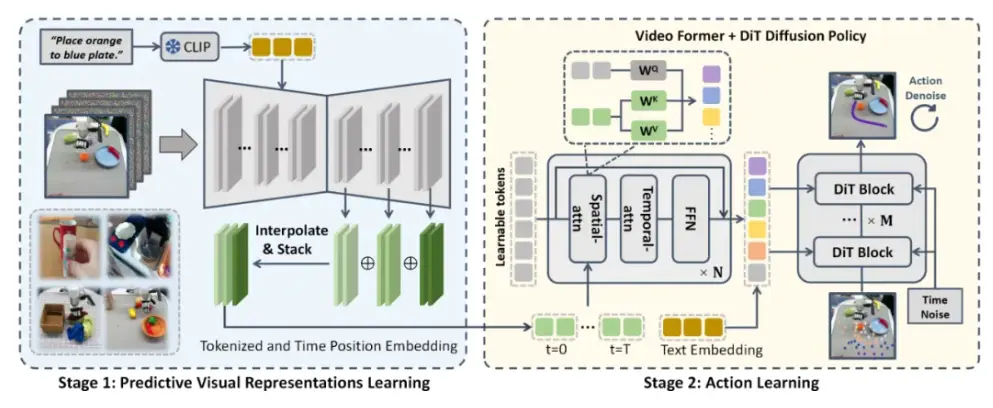
VPP 基于 AIGC 视频扩散模型而来。如图所示,VPP 分成两阶段的学习框架,最终实现基于文本指令的视频动作生成。第一阶段利用视频扩散模型学习预测性视觉表征;第二阶段通过 Video Former 和 DiT 扩散策略进行动作学习。
VPP 的一大亮点在于其预测能力。以往机器人策略(例如:VLA 模型)往往只能根据当前观测进行动作学习,机器人策略需要先理解指令和场景,再执行。VPP 能够提前预知未来的场景,让机器人 “看着答案” 行动,大大增强泛化能力。通过该模型,机器人的执行速度能够实现 “更快一步”,在仅需150毫秒的推理时间内,预测频率达到6-10Hz,控制频率更是超过50Hz,极大提升了动作执行的流畅性。

VPP 还可以直接学习各种形态机器人的视频数据,不存在维度不同的问题。如果将人类本体也当作一种机器本体,VPP 也可以直接学习人类操作数据,显著降低数据获取成本。同时视频数据也包含比低维度动作更加丰富的信息,大大提高模型泛化能力。

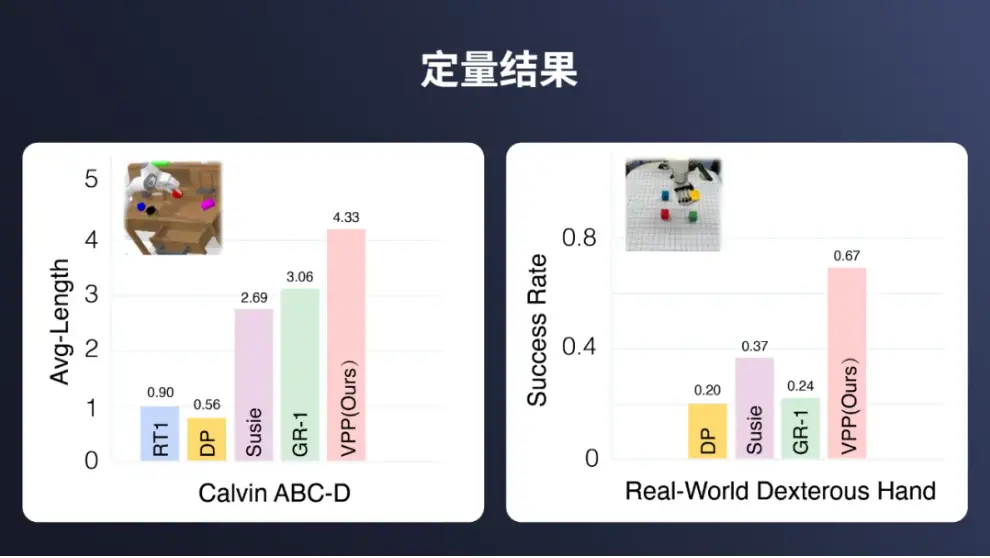
基准测试结果表明,在最近的 Calvin ABC-D 基准测试中,VPP 模型以4.33的任务完成平均长度接近满分5.0。相较于先前技术,VPP 实现了 41.5% 的显著提升。在真实世界的灵巧操作测试中,该模型在多任务学习和泛化能力上同样表现不俗,能完成超过100种复杂操作任务,显示出其在实际应用中的强大潜力。
此外,VPP 的预测视觉表示在一定程度上是可解释的,开发者在不通过 real-world 测试情况下,通过预测的视频来提前发现失败的场景和任务,进行针对性的调试和优化。
VPP 项目开源部署 Tips,供各位开发者参考:
-
所有实验均使用一个节点(8 卡 A800/H100)完成;
-
详细操作说明可在开源 GitHub 中找到;
-
实验仿真平台是标准 Calvin abc-d Benchmark;
-
实验真机平台为星动纪元仿人五指灵巧手星动 XHAND1 以及全尺寸人形机器人星动 STAR1。