来自字节跳动(ByteDance)的神秘新视频模型Waver 1.0已现身Video Arena排行榜,并在榜单上进入了第三名的位置。
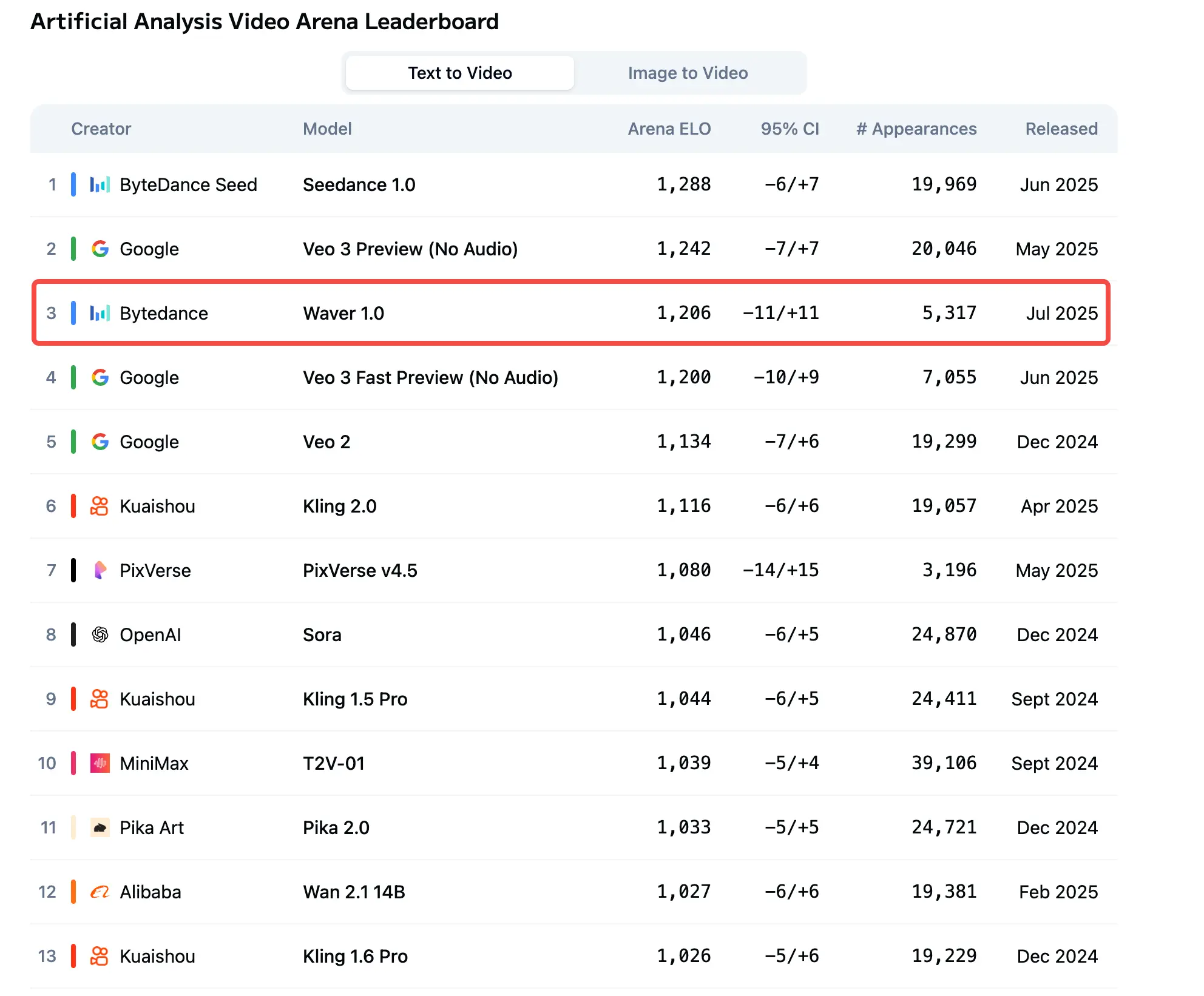
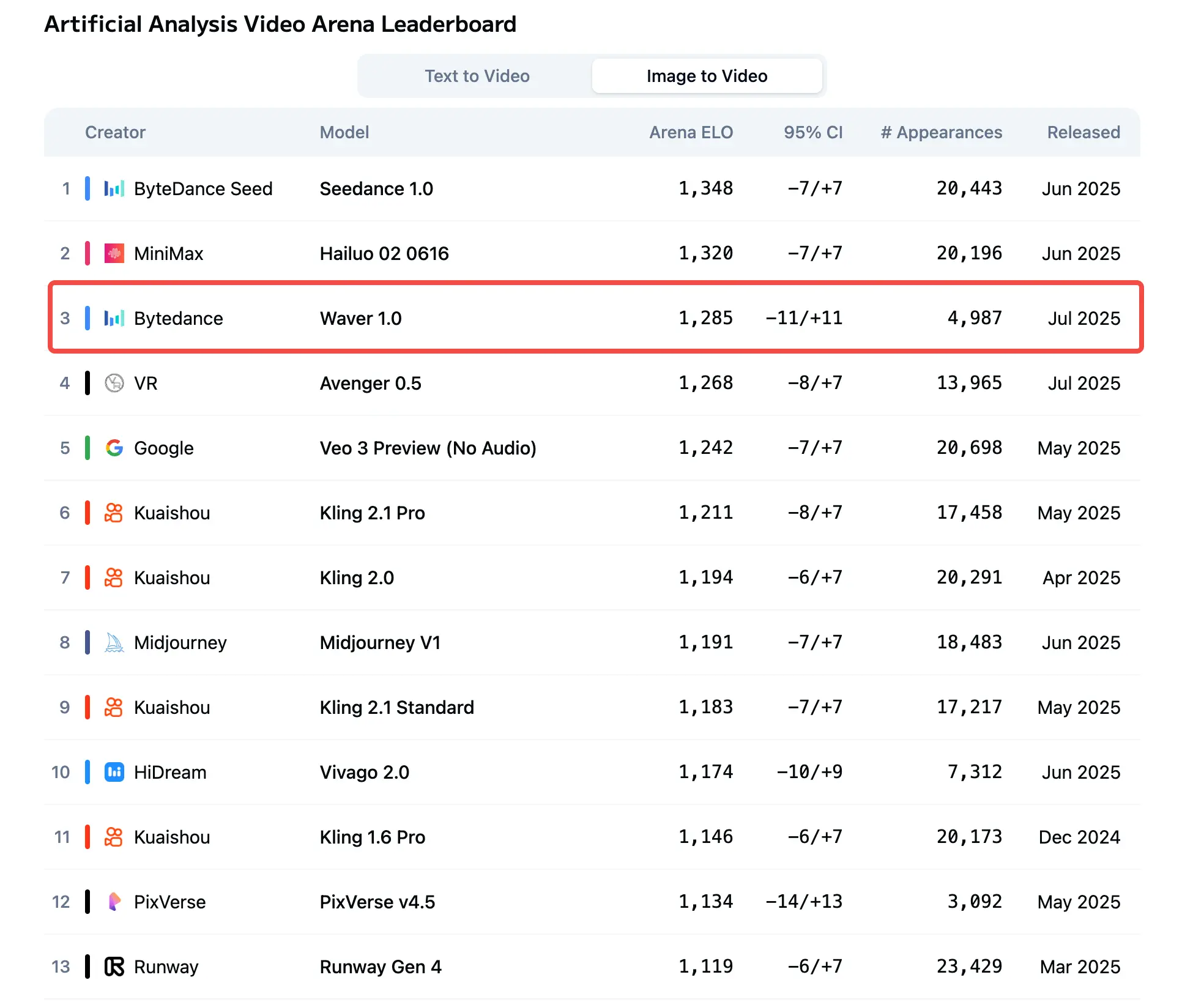
值得关注的是,这款模型在文生视频和图生视频榜单上都是排名第三。文生视频仅次于字节之前发布的Seedance 1.0和谷歌的Veo3,图生视频仅次于Seedance 1.0和MiniMax的Hailuo 02模型。
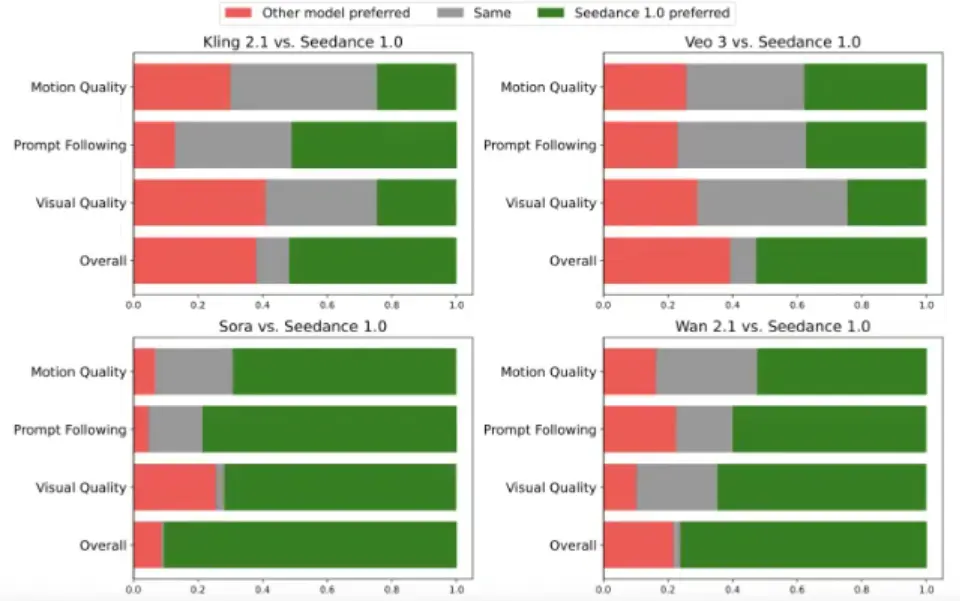
字节上个月发布了Seedance 1.0。在评测中,Seedance1.0在多个维度上超过了Veo3。在与电影导演合作开发的SeedVideoBench基准测试中,该模型在遵循提示和动作真实感方面取得了更高的分数。在图像到视频的任务中,Seedance 保持了输入帧的视觉一致性,而Veo3则在某些情况下出现了光照和纹理的变化。