Meta 宣布推出 SeamlessM4T,一种基础的多语言和多任务模型,可以无缝翻译和转录语音和文本。SeamlessM4T 支持:
- 自动语音识别近百种语言
- 近 100 种输入和输出语言的语音到文本翻译
- 语音翻译,支持近 100 种输入语言和 35 种(+英语)输出语言
- 近 100 种语言的文本到文本翻译
- 文本转语音翻译,支持近 100 种输入语言和 35种(+英语)输出语言

目前,SeamlessM4T 已在 CC BY-NC 4.0 许可下发布,以便研究人员可以在此基础上进行开发。与此同时,Meta 还发布了一个多模式翻译数据集 SeamlessAlign,包含 270,000 小时的语音和文本对齐。
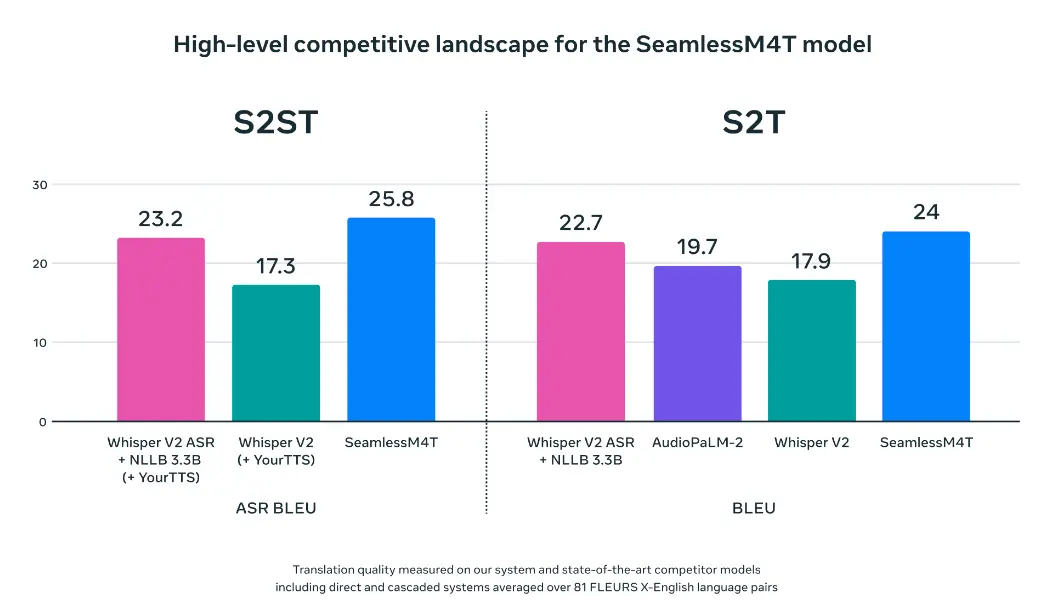
Meta 表示,现有的语音转语音和语音转文本程序仅覆盖世界上一小部分语言, 而 SeamlessM4T 代表了语音到语音和语音到文本领域的重大突破,它解决了语言覆盖面有限和依赖独立系统的难题,将语音到语音的翻译任务分成多个阶段,跨越多个子系统。
“我们所面临的挑战是创建一个可以完成这一切的统一多语言模型。我们相信,我们今天宣布的工作是在这一征程中迈出的重要一步。我们的单一模式可提供按需翻译,让使用不同语言的人能够更有效地交流。我们显着提高了我们支持的中低资源语言的性能...... SeamlessM4T 能隐式识别源语言,无需单独的语言识别模型。”
SeamlessM4T 建立在 Meta 在该领域的现有工作基础上,包括 No Language Left Behind、Universal Speech Translator、SpeechMatrix 和 Massively Multilingual Speech。
Meta 方面表示,他们在研发过程中遵循"five pillars of Responsible AI"指导原则;并进行了毒性和偏见研究,以了解模式中可能存在的敏感区域。并对模型进行了性别偏见评估,目前已能够量化数十个语音翻译方向的性别偏见。
当使用允许跨语音和文本单元进行评估的 BLASER 2.0 进行测试时,与目前最先进的语音到文本任务模型相比,SeamlessM4T 模型在语音到文本任务中对抗背景噪声和说话者变化的表现更好(平均分别提高了 37% 和 48%)。“SeamlessM4T 的性能也优于之前最先进的竞争对手。”
更多详情可查看官方博客。