AI 芯片公司 Cerebras 宣布在 Apache-2.0 协议下开源了一个包含七个 GPT 模型的 Cerebras-GPT,参数涵盖 1.11 亿、2.56 亿、5.9 亿、13 亿、27 亿、67 亿和 130 亿。开放出来的内容包括模型架构、训练算法和权重,供研究以及商业社区免费使用。
“今天的发布旨在供任何人使用和复制......人工智能有可能改变世界经济,但它的访问越来越受到限制。最新的大型语言模型 —— OpenAI 的 GPT4 发布时没有关于其模型架构、训练数据、训练硬件或超参数的信息。公司越来越多地使用封闭数据集构建大型模型,并仅通过 API 访问提供模型输出。为了使 LLM 成为一种开放和可访问的技术,我们认为重要的是能够访问对研究和商业应用开放、可重现且免版税的最先进模型。”
根据介绍,这些模型使用 Chinchilla 公式进行训练,可为给定的计算预算提供最高的准确性。Cerebras-GPT 与迄今为止的任何公开可用模型相比,训练时间更快、训练成本更低,并且功耗更低。
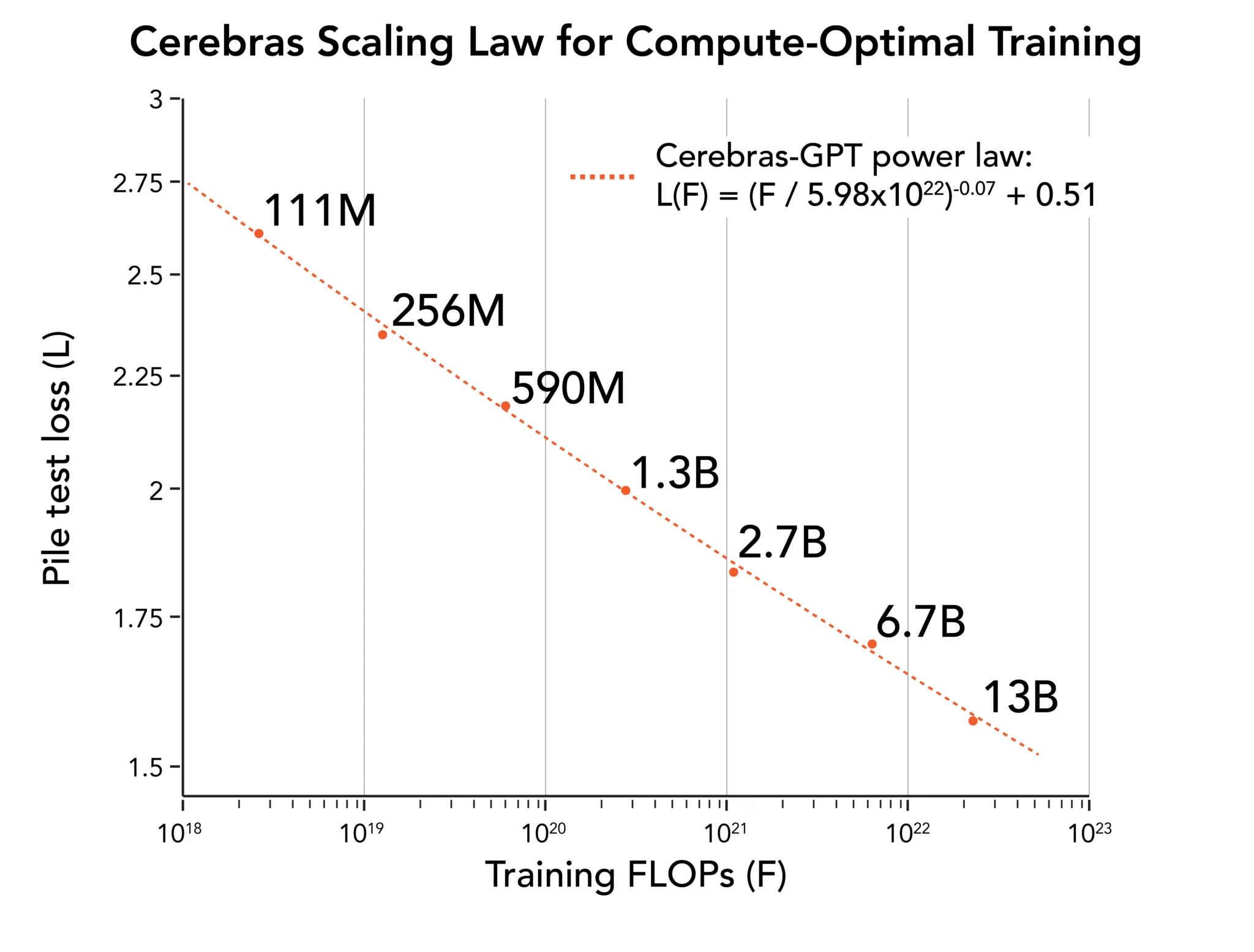
Cerebras-GPT 在 Cerebras 所拥有的 Andromeda AI 超级计算机的 CS-2 系统上进行了几周的训练。“训练这七个模型使我们能够推导出新的 scaling law。Scaling laws 根据训练计算预算预测模型准确性,并在指导 AI 研究方面产生了巨大影响。据我们所知,Cerebras-GPT 是第一个预测公共数据集模型性能的 scaling law。”
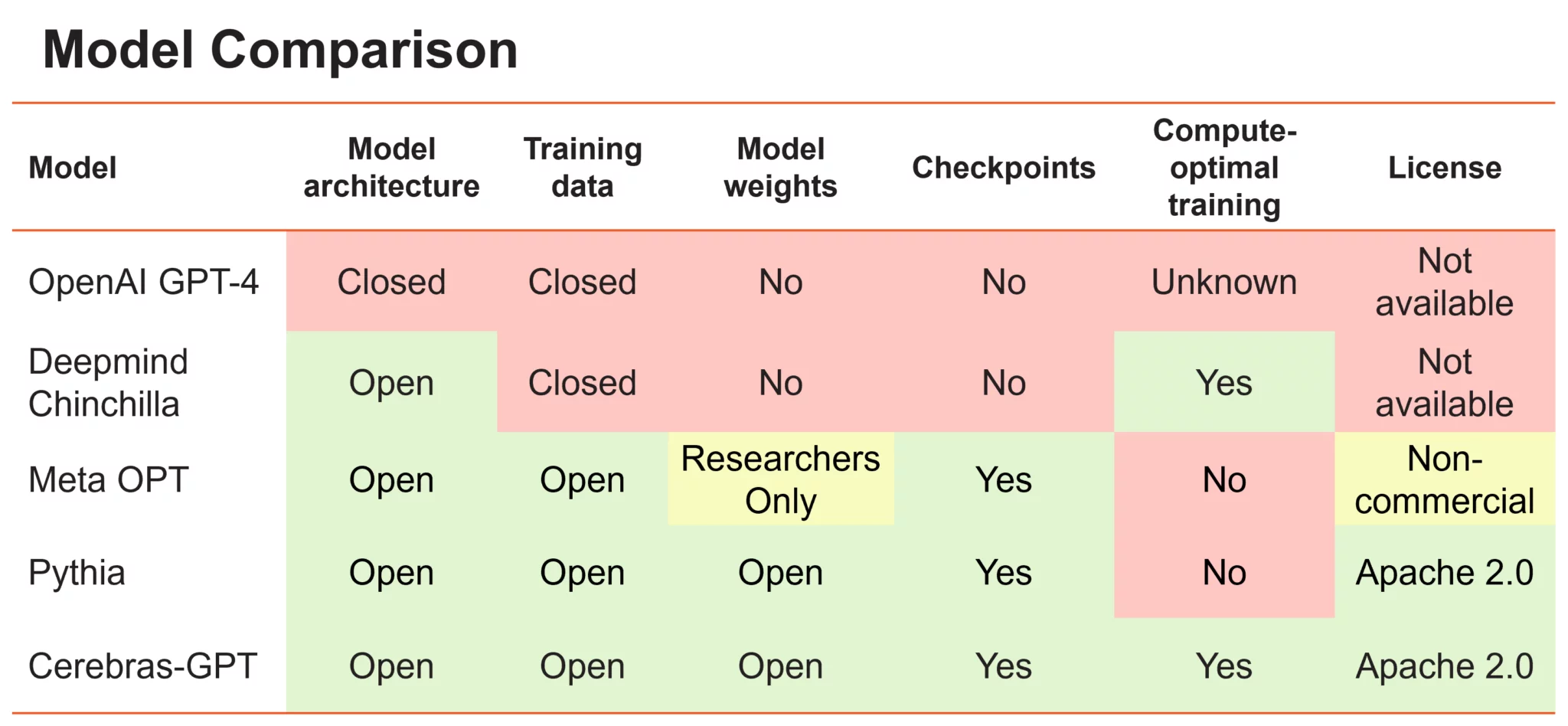
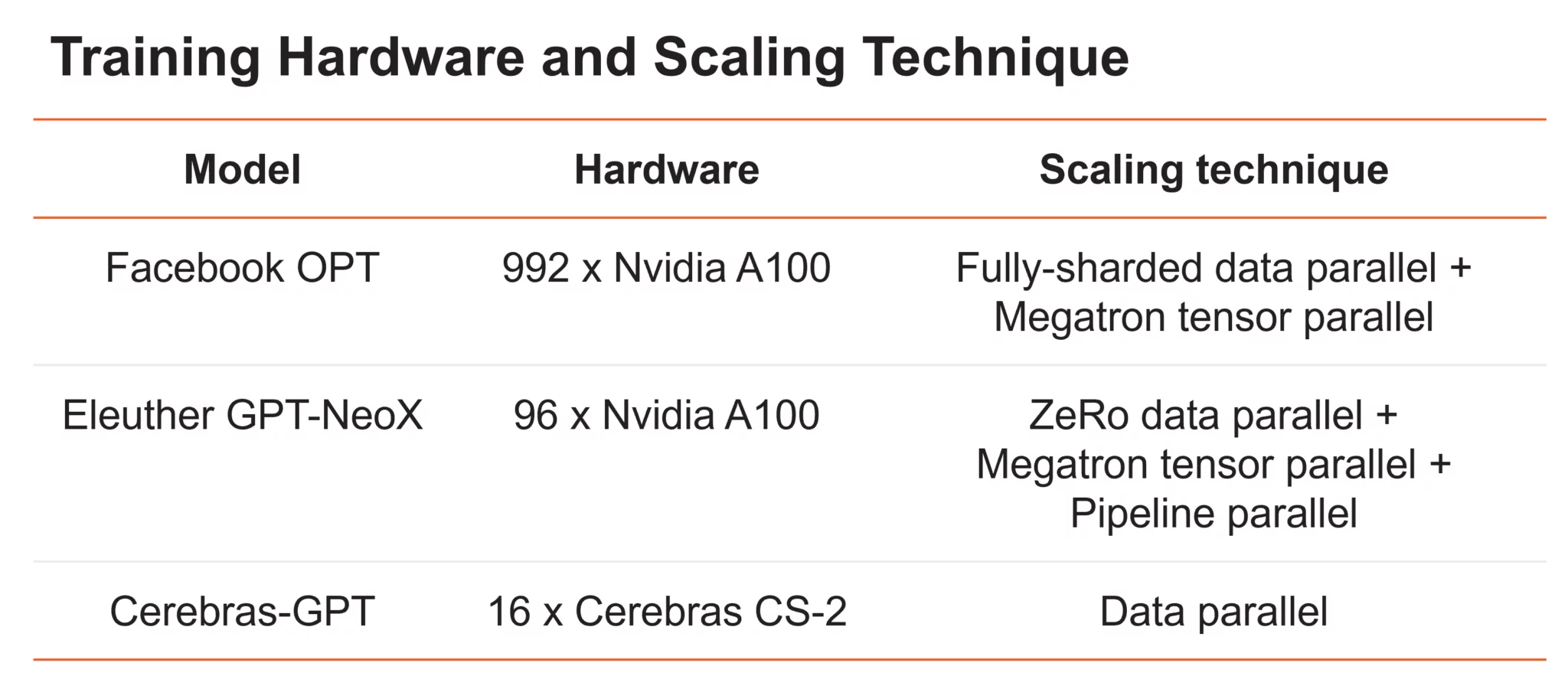
大型语言模型可以大致分为两个阵营。第一组包括 OpenAI 的 GPT-4 和 DeepMind 的 Chinchilla 等模型,这些模型在私有数据上进行训练以达到最高水平的准确性;但是这些模型的训练权重和源代码不向公众开放。第二组包括 Meta 的 OPT 和 Eleuther 的 Pythia 等模型,它们是开源的,但没有以 compute-optimal 的方式进行训练。
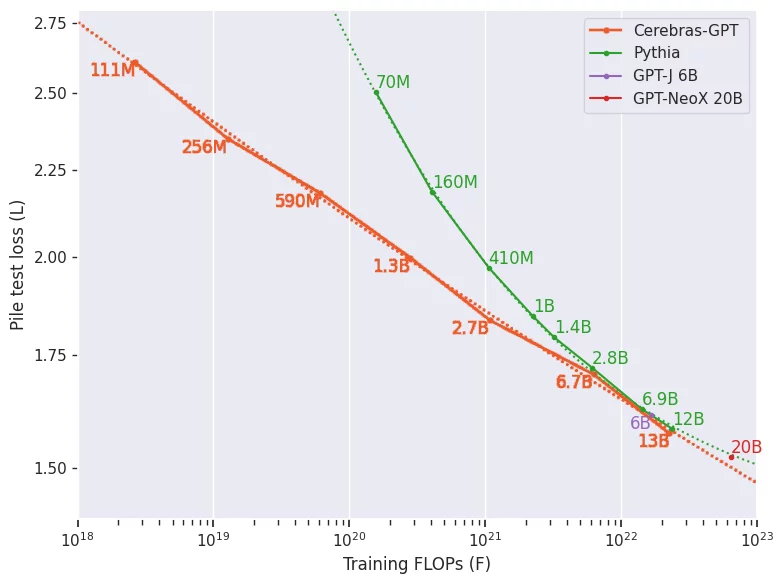
Cerebras-GPT 则意在与 Pythia 互补,它共享相同的公共 Pile 数据集,旨在构建一个训练有效的 scaling law 和模型系列,涵盖各种模型尺寸。构成 Cerebras-GPT 的七个模型中的每一个都使用每个参数 20 个 tokens 进行训练;Cerebras-GPT 通过选择最合适的训练 tokens,最大限度地减少所有模型大小的单位计算损失。
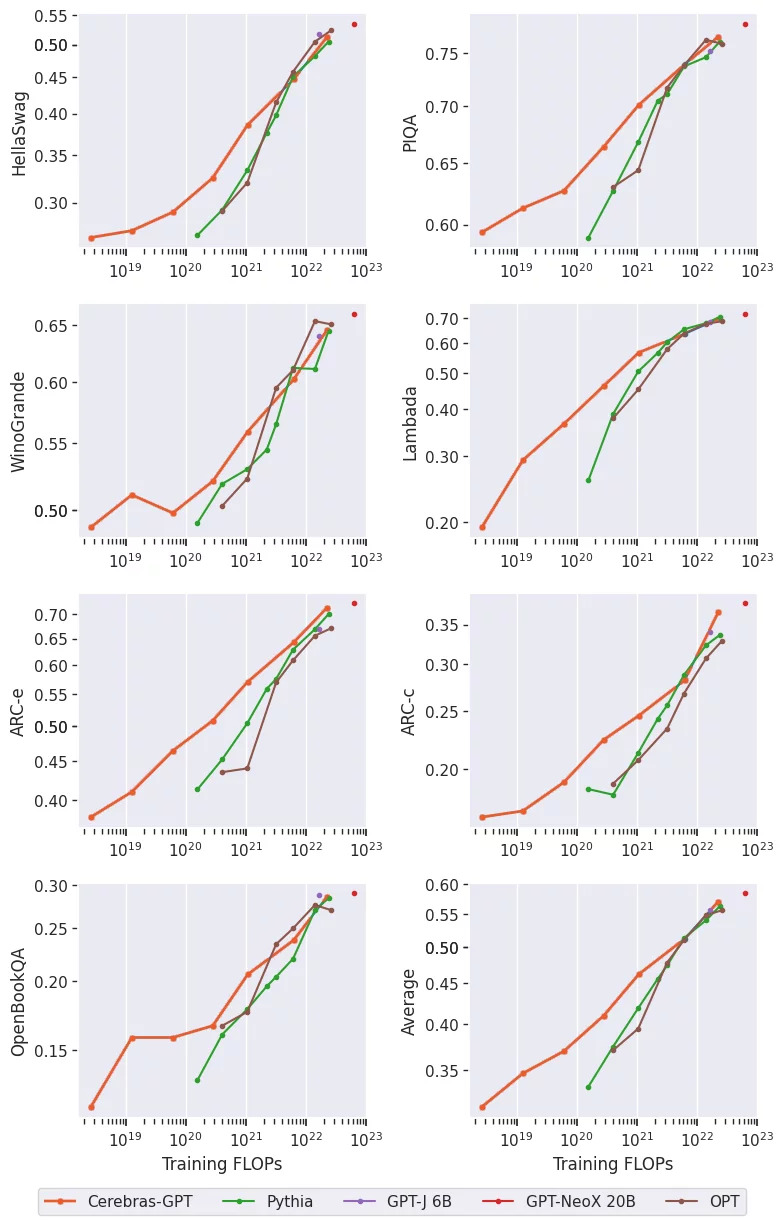
研究人员评估了 Cerebras-GPT 在几个任务特定的语言任务上的表现,例如句子完成和问答。结果表明,Cerebras-GPT 为大多数常见的下游任务保持了最先进的训练效率。
Cerebras GPT 在 16 个 CS-2 系统上使用了标准数据并行进行训练。研究人员围绕 CS-2 设计了专门构建的 Cerebras Wafer-Scale Cluster,以实现轻松扩展。它使用称为 weight streaming 的 HW/SW 共同设计的执行,可以独立缩放模型大小和集群大小,而无需模型并行。介绍称,通过使用此架构,扩展到更大的集群就像更改配置文件中的系统数量一样简单。
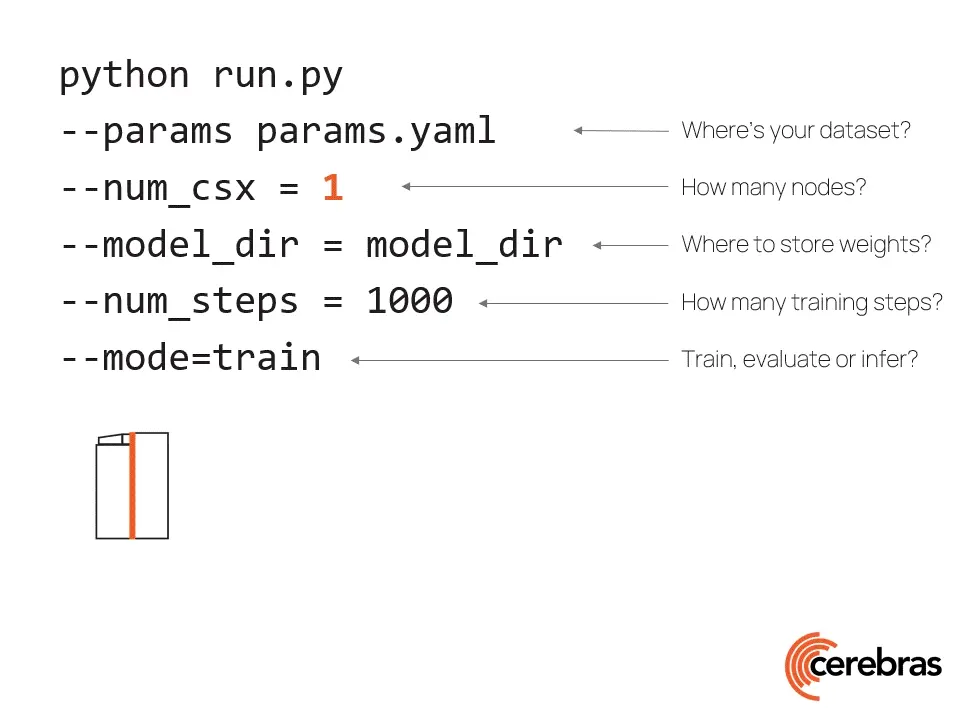
研究人员还在一个名为 Andromeda 的 16x CS-2 Cerebras Wafer-Scale Cluster 上训练了所有 Cerebras-GPT 模型。使所有的实验都能快速完成,而不需要在 GPU集群上进行传统的分布式系统工程和模型并行调整。最重要的是,它使研究人员能够专注于 ML 的设计而不是分布式系统。“我们相信,轻松训练大型模型的能力是广大社区的关键推动因素,因此我们通过 Cerebras AI Model Studio 在云端提供了 Cerebras Wafer-Scale Cluster。”
Cerebras 联合创始人兼首席软件架构师 Sean Lie 称,由于很少有公司有资源在内部训练真正的大型模型,因此此次发布意义重大。“通常需要成百上千个 GPU,将七个经过全面训练的 GPT 模型发布到开源社区中,恰恰说明了 Cerebras CS-2 系统集群的效率。”
该公司表示,Cerebras LLM 因其开源性质而适用于学术和商业应用。它们还有一些优势,例如其训练权重产生了一个极其准确的预训练模型,可以用相对较少的额外数据为不同的任务进行调整;这使得任何人都可以基于很少的编程知识,创建一个强大的、生成性的 AI 应用程序。
更多详情可查看官方博客。