字节跳动近日宣布推出其全新的数据选择框架 QuaDMix,旨在提升大型语言模型(LLM)预训练的效率和泛化能力。众所周知,模型的训练效果受基础数据集的质量和多样性影响很大。然而,传统的数据筛选方法往往将质量和多样性视为两个独立的目标,先进行质量过滤,再进行领域平衡。
这种逐步优化的方式忽略了质量与多样性之间的复杂相互关系。优质数据集往往存在领域偏差,而多样化的数据集可能会降低质量。因此,在固定的训练预算下,如何同时优化这两个维度以最大化模型性能,成为了一个亟待解决的难题。
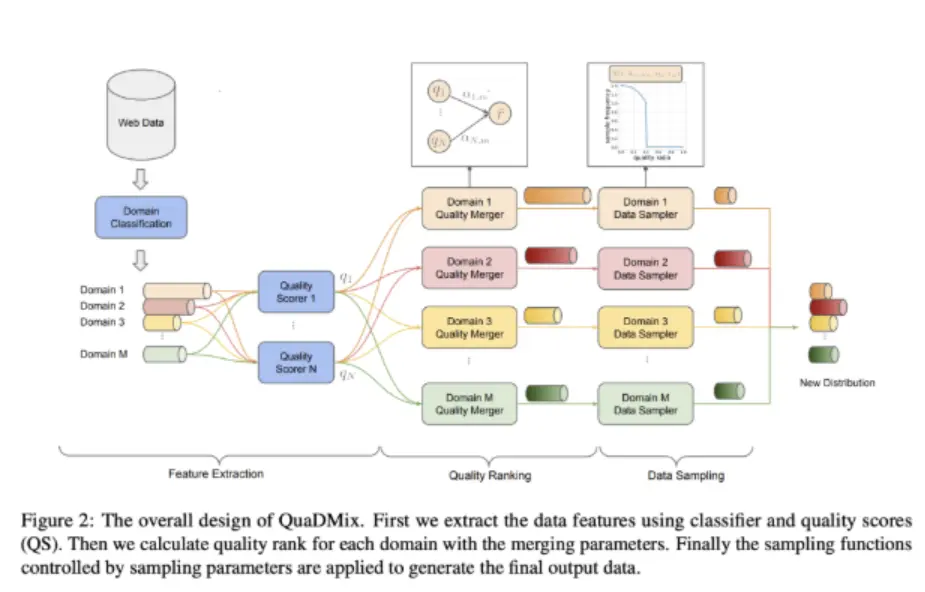
QuaDMix 框架的主要运作分为三个阶段:特征提取、质量聚合和质量 - 多样性感知采样。在初始阶段,每个文档都会被标注领域标签和多项质量评分。通过归一化和合并这些评分,生成一个综合质量分数。接着,系统通过基于 sigmoid 的函数采样文档,优先考虑高质量样本,并通过参数化控制确保领域平衡。
为了优化模型,QuaDMix 在不同参数设置下训练了数千个代理模型。通过这些代理实验训练的回归模型可以预测性能结果,从而识别出最佳采样配置。这种方法使得在高维参数空间中进行结构化探索成为可能,从而更好地将数据选择与下游任务对接。
实验结果显示,QuaDMix 在 RefinedWeb 数据集上进行的验证实验中,与多种基线模型相比,平均得分达到了39.5%。这些基线模型包括随机选择、Fineweb-edu、AskLLM、DCLM 等。实验结果表明,联合优化策略在整体表现上始终优于单独关注质量或多样性的方法。此外,经过优化的数据混合更能提升特定下游任务的性能。
QuaDMix 为大型语言模型的预训练数据选择提供了一个系统化的解决方案,解决了长期以来同时优化数据质量与多样性的挑战。通过结合质量聚合和领域感知采样,QuaDMix 建立了一种可扩展的方法论,提升了 LLM 预训练的效率。