英伟达发布了 Llama-3.3-Nemotron-Super-49B-v1.5,这是一款专为推理和 Agentic 任务优化的开源模型,在单个 H100 GPU 上实现高吞吐量。
模型介绍
Llama Nemotron Super v1.5 是 Llama-3.3-Nemotron-Super-49B-V1.5 的简称。它是 Llama-3.3-Nemotron-Super-49B-V1 的升级版本(该模型是 Meta 的 Llama-3.3-70B-Instruct 的衍生模型),专为复杂推理和智能体任务设计,支持 128K tokens 的上下文长度。
模型架构
Llama Nemotron Super v1.5 采用神经架构搜索(Neural Architecture Search,NAS),使该模型在准确率和效率之间实现了良好的平衡,将吞吐量的提升有效转化为更低的运行成本。
(注:NAS 的目标是通过搜索算法从大量的可能架构中找到最优的神经网络结构,利用自动化方法替代人工设计神经网络架构,从而提高模型的性能和效率。)
模型经过了多阶段后训练,包括针对数学、代码、科学和工具调用的监督微调 (SFT),以及用于聊天对齐的奖励感知偏好优化 (RPO)、用于推理的带可验证奖励的强化学习 (RLVR) 和用于工具调用能力增强的迭代直接偏好优化 (DPO)。
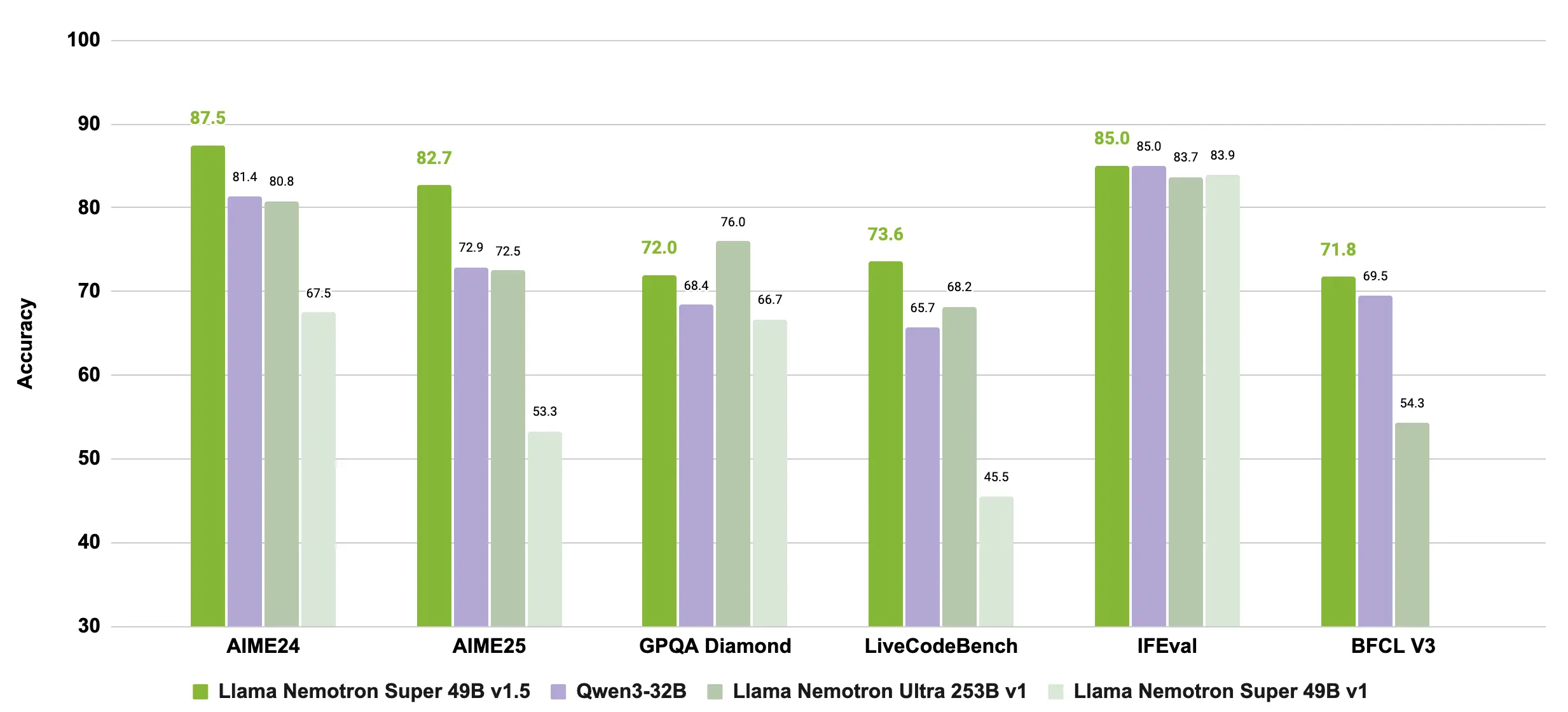
在多个基准测试中,该模型表现出色。例如,在 MATH500 上 pass@1 达到 97.4,在 AIME 2024 上达到 87.5,在 GPQA 上达到 71.97。模型支持 Reasoning On/Off 模式,用户可通过在系统提示中设置 /no_think 来关闭推理模式。官方推荐在推理开启时使用 temperature=0.6 和 Top P=0.95,在关闭时使用贪心解码。
该模型已准备好用于商业用途,遵循 NVIDIA Open Model License 和 Llama 3.3 社区许可协议。开发者可以通过 NVIDIA build.nvidia.com 或 Hugging Face 下载和试用该模型,并可使用 vLLM(推荐 v0.9.2)进行部署,官方仓库中提供了支持工具调用的解析器插件。