
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@赵怡岭、@鲍勃
01 有话题的技术
1、通义实验室语音团队推出 OmniAudio 技术,可直接从 360° 视频生成 FOA 空间音频
5 月 29 日,阿里通义大模型公布了「空间音频生成」模型——OmniAudio。据通义团队介绍,OmniAudio 能够直接从 360° 视频生成空间音频。
为了解决「如何利用全景视频生成与之匹配的空间音频」这一问题,通义实验室语音团队提出了 360V2SA(360-degree Video to Spatial Audio)任务,旨在直接从 360° 视频生成 FOA(First-order Ambisonics)音频。
据悉,FOA 是一种标准的 3D 空间音频格式,能够捕捉声音的方向性,实现真实的 3D 音频再现。
受限于现有的配对 360° 视频和空间音频数据极为稀缺,通义团队还为此精心设计并构建了 Sphere360 数据集。该数据集包含大量高质量的 360° 视频和相应的 FOA 空间音频。这是一个包含超过 10.3 万个真实世界视频片段的数据集,涵盖 288 种音频事件,总时长达到 288 小时。
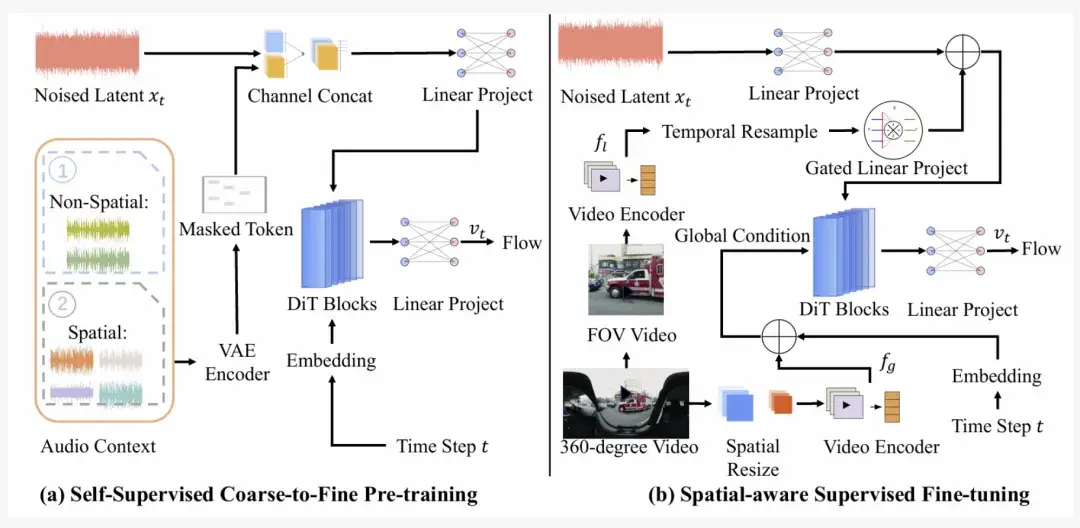
另外,OmniAudio 的训练方法分为了「自监督的 coarse-to-fine 流匹配预训练」以及「基于双分支视频表示的有监督微调」两个阶段。
目前,OmniAudio 已上架 GitHub 并同步公布了代码、数据开源仓库,以及相关技术论文。
项目主页:https://omniaudio-360v2sa.github.io/
代码和数据开源仓库:https://github.com/liuhuadai/OmniAudio
论文地址:https://arxiv.org/abs/2504.14906 (@APPSO、@阿里语音 AI)
2、可灵 2.1 系列视频模型发布,拥有卓越的动态效果表现,更强的语义响应
快手可灵 AI 发布了其 KLING 2.1 系列视频模型。据悉,可灵 2.1 系列拥有标准版和大师版两个版本模型:
标准版支持标准(720P)和高品质(1080P)两种模式。价格方面,标准模式为 20 积分/5 秒,高品质模式为 35 积分/5 秒。
大师模式全面升级为 1080P 输出,拥有卓越的动态效果表现,更强的语义响应。可灵 2.1 标准版暂仅支持「图生视频」功能,「文生视频」功能将在近期上线。目前,可灵 AI 官网已可体验可灵 2.1 系列模型。
可灵 AI:https://app.klingai.com/cn/ (@APPSO)
02 有亮点的产品
1、PlayDiffusion:一种基于扩散的修补模型,具有修改现有语音的能力
PlayDiffusion 是一个让用户能够通过简单编辑文本来编辑音频/视频内容中语音的模型。该模型是一种基于扩散的修补模型,具有修改现有语音的能力,通过该模型可以像编辑文档一样编辑语音,无需重新录制。只需上传音频/视频,编辑自动生成的转录文本,即可获得更新后的语音。现已开源。
工作原理:
1、上传内容;
2、模型转录语音;
3、你编辑转录文本;
4、模型使用相同的声音进行更改。
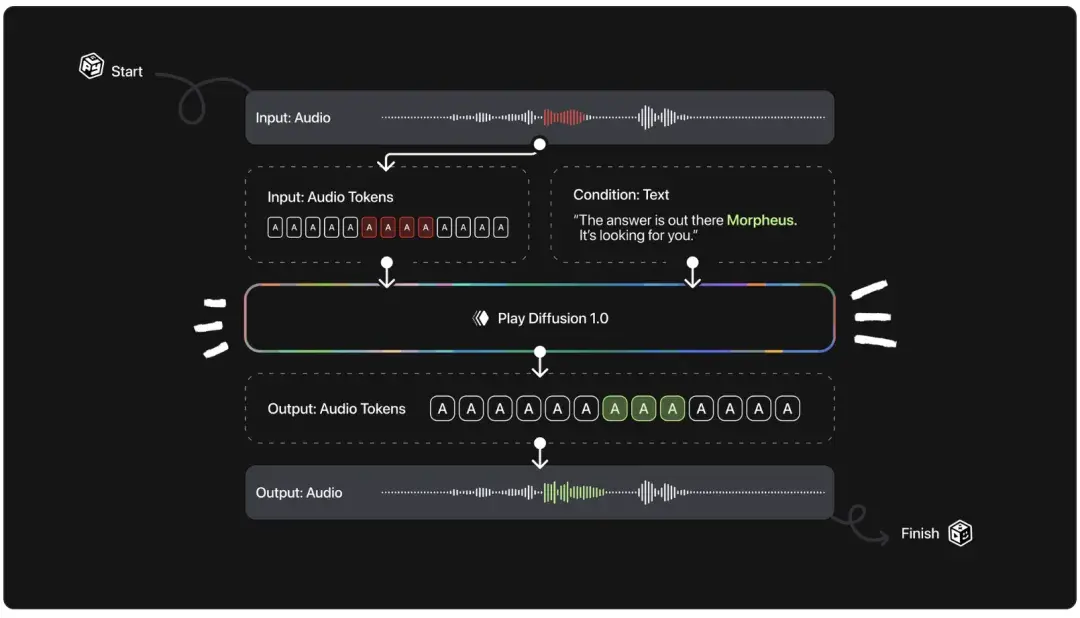
并且 PlayDiffusion 不是像自回归模型那样逐个生成标记,而是能够一次性预测所有标记,并在大约 20 个去噪步骤中进行优化。这使得生成步骤的效率提高了最多 50 倍,同时没有任何损失。
GitHub: https://github.com/playht/PlayDiffusion
Demo: https://huggingface.co/spaces/PlayHT/PlayDiffusion
Fal: https://fal.ai/models/fal-ai/playai/inpaint/diffusion (@HammadH4@X、 @PlayAIOfficial@X)
2、ElevenLabs 发布对话式人工智能 2.0 ,具备新一代先进的轮流发言功能和全面支持企业级应用
ElevenLabs 发布 Conversational AI 2.0,实现了自然转换对话能力,能识别语气词判断用户意图,避免尴尬停顿和不当打断。ElevenLabs Conversational AI 现已支持多模态,用户可以创建能够通过文本、语音或同时通过两者进行交流的智能体。
ElevenLabs 开发了批量呼叫功能,使用户能够自动化并扩展外呼语音通信。批量呼叫允许使用用户的对话式 AI 智能体同时发起多个外呼,非常适合发送警报、进行调查或向庞大联系人列表传递个性化信息等用例,提升速度和一致性。 新系统集成了多语言自动识别功能和检索增强生成(RAG)技术,支持多模态交互,一个 AI 助手可同时处理文本和语音。
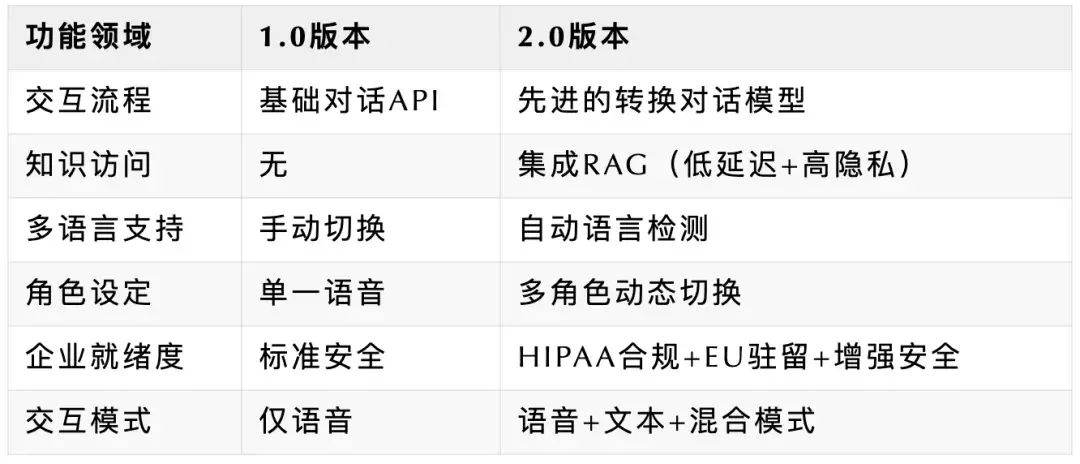
新功能概览:
-
新一代先进的轮流发言模型;
-
语言切换;
-
多角色模式;
-
多模态;
-
批量调用;
-
内置 RAG。(@elevenlabsio@X、@腾讯研究院、@海波学者聊 AI)
3、马斯克宣布推出 XChat,具备消息「阅后即焚」和无需电话号码即可使用的网络通话/视频功能
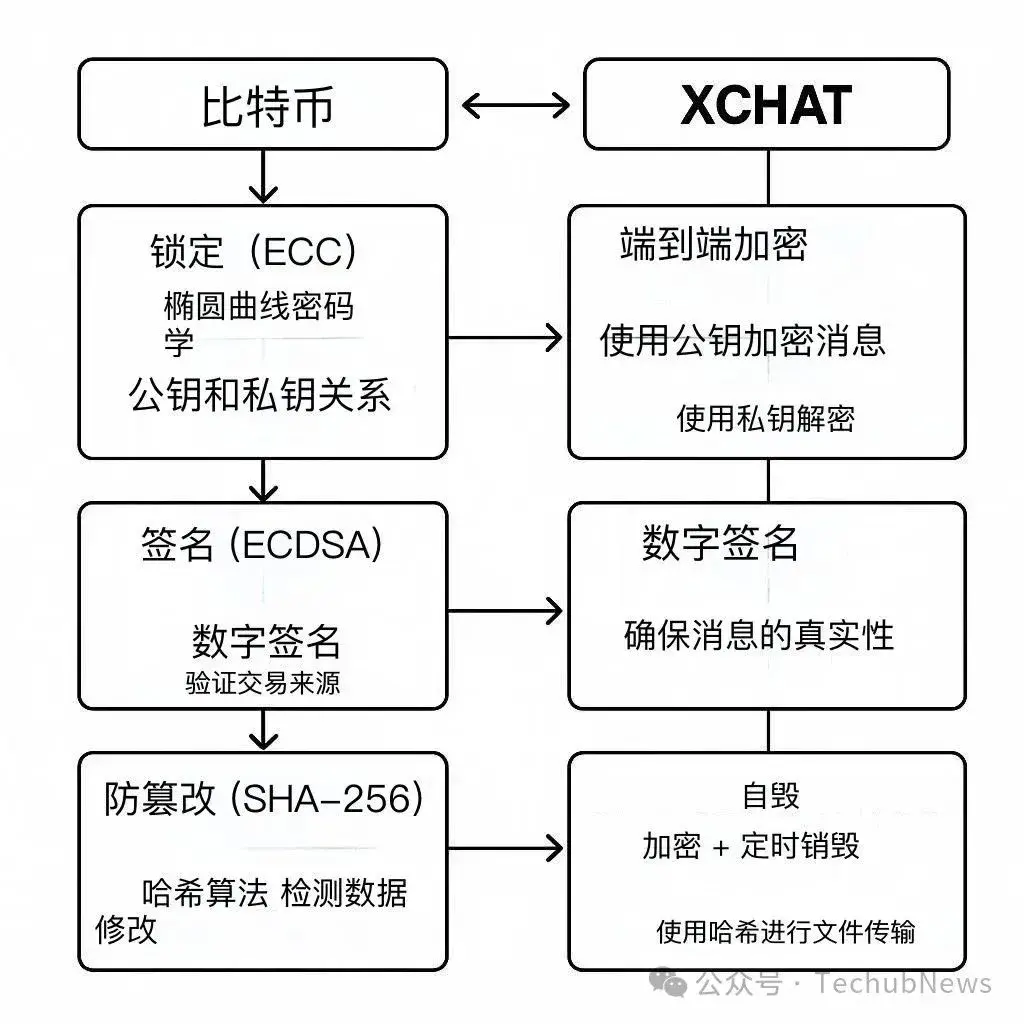
日前,马斯克宣布推出一款名为「XChat」的即时通信服务平台。据悉,该平台将具备消息「阅后即焚」和无需电话号码即可使用的网络通话/视频功能。
马斯克宣称 XChat 采用了「比特币风格的加密」,并用 Rust 语言开发,号称「全新架构」。
据 The Information 报道指出,XChat 本质上是为了与 WhatsApp、Telegram,甚至是微信展开竞争。
值得一提的是,Telegram 创始人 Pavel Durov 在一周前曾表示其与马斯克旗下的 xAI 签署了合作协议,并在 Telegram 中接入了 xAI 的 AI 聊天机器人 Grok。
-
端到端加密:消息、通话内容只有通信双方能看到,第三方(包括 X 平台)无法窥探;
-
阅后即焚:可以设置消息在一定时间后自动删除,比如 10 分钟后,保护隐私更彻底;
-
任意文件传输:支持发送任何类型的文件,包括照片、视频、文档等,不再受限于格式或大小;
-
跨平台音视频通话:无需手机号即可拨打,支持手机、电脑等多设备,通话内容同样加密。
(@APPSO、@Techub Info)
03 Real-Time AI Demo
1、使用手势和语音命令控制 3D 模型,包括移动、旋转、缩放、动画
来自 X 上的@measure_plan:你现在可以导入任何 3D 模型,并使用手势+语音来控制它
04 有态度的观点
1、Anthropic CEO:未来五年 AI 或取代一半白领工作
最近在旧金山总部接受采访时,Anthropic CEO Dario Amodei 发出严峻警告:AI 的迅猛发展可能在未来一到五年内淘汰多达一半的初级白领岗位,社会失业率或飙升至 10% 到 20%。
Amodei 表示,现在是时候停止对 AI 潜在影响的「美化」,技术、金融、法律、咨询等多个行业的初级职位将面临大规模消失,而多数普通人对此几乎一无所知,也缺乏足够的重视。
他希望通过公开发声,促使政策制定者与同行开始采取行动,为社会转型做准备。「大多数人并不知道这件事就要发生,听起来像疯话,但他们不信。」
Amodei 表示,虽然 AI 也带来医疗突破、经济增长等潜力,但其风险同样不可忽视。「癌症治好了,GDP 每年增长 10%,财政平衡……可有 20% 的人失去了工作。」他坦言,这样的情境极可能在技术爆发中同时发生。(@APPSO)

更多 Voice Agent 学习笔记:
级联vs端到端、全双工、轮次检测、方言语种、商业模式…语音 AI 开发者都在关心什么?丨Voice Agent 学习笔记
a16z 最新报告:AI 数字人应用层即将爆发,或将孕育数十亿美金市场丨 Voice Agent 学习笔记
a16z合伙人:语音交互将成为AI应用公司最强大的突破口之一,巨头们在B2C市场已落后太多丨Voice Agent 学习笔记
ElevenLabs 33 亿美元估值的秘密:技术驱动+用户导向的「小熊软糖」团队丨Voice Agent 学习笔记
端侧 AI 时代,每台家居设备都可以是一个 AI Agent丨Voice Agent 学习笔记
世界最炙手可热的语音 AI 公司,举办了一场全球黑客松,冠军作品你可能已经看过
多模态 AI 怎么玩?这里有 18 个脑洞
AI 重塑宗教体验,语音 Agent 能否成为突破点?
对话 TalktoApps 创始人:Voice AI 提高了我五倍的生产力,语音输入是人机交互的未来
a16z 最新语音 AI 报告:语音将成为关键切入点,但非最终产品本身(含最新图谱)
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻