面壁智能正式发布并开源了「面壁小钢炮」端侧系列最新力作——MiniCPM 4.0 模型,实现了端侧可落地的系统级软硬件稀疏化的高效创新。英特尔与面壁智能从模型开发阶段就紧密合作,实现了长短文本多重推理效率的提升,端侧AI PC在Day 0全面适配,128K长上下文窗口等多方面突破。
双方开展了深度技术协同,基于英特尔硬件架构定制投机解码配置。通过硬件感知的草稿模型优化策略,结合英特尔加速套件与KV Cache内存增强技术,实现端到端推理效率的2.2倍提升1,携手为业界带来了全新的模型创新和端侧性能体验。

此次,面壁推出的MiniCPM 4.0系列LLM模型拥有 8B、0.5B 两种参数规模,针对单一架构难以兼顾长、短文本不同场景的技术难题,MiniCPM 4.0-8B采用「高效双频换挡」机制,能够根据任务特征自动切换注意力模式:在处理高难度的长文本、深度思考任务时,启用稀疏注意力以降低计算复杂度,在短文本场景下切换至稠密注意力以确保精度,实现了长、短文本切换的高效响应。
目前,具有CPU、GPU、NPU三个AI运算引擎的英特尔酷睿Ultra处理器已迅速对此适配,并借助OpenVINO™ 工具套件为MiniCPM 4.0系列模型提供优化的卓越性能表现。英特尔再次在NPU上对模型发布提供第零日(Day 0)支持,为不同参数量模型和应用场景提供更多样化的、更有针对性的平台支持。
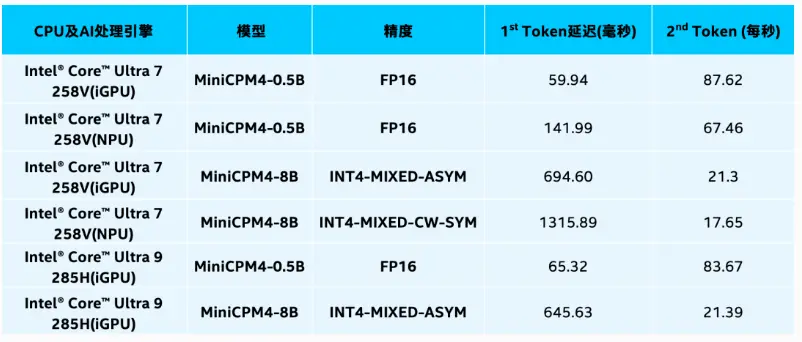
* 上述测试评估了在int4混合精度和fp16精度设置下1K输入的首词元延迟和平均吞吐量。每项测试在预热阶段后执行三次,选取平均值作为报告数据。性能结果基于以下SKU1或SKU2配置2
在长上下文窗口的技术创新方面,英特尔也有了新的突破。依托分块稀疏注意力机制,结合深度算子融合与硬件驱动的算法优化,实现了长文本缓存的大幅锐减,和推理效率的进一步提升。 在保证输出质量的前提下,我们首次在基于英特尔锐炫™ Pro B60上将长上下文窗口扩展至128K。相较于稠密模型,首Token延迟降低了38%3,Token速率提升多达3.8倍3。经过这样的提升,一整部300多页的哈利波特小说,可以在90秒内完成阅读、分析和总结。这不仅极大地提升了AI PC的用户体验,也为解锁更多端侧AI新应用建立了强大的基础。未来,英特尔将持续保持与面壁的深度合作和协同研发,进一步提升长上下文窗口应用的性能。
对128K的文本输入进行处理的效果请参考视频演示。
MiniCPM Video CN Final
在当今数字化时代,人工智能技术正以前所未有的速度发展,英特尔作为全球领先的科技企业和AI PC的发起和倡导者,始终致力于推动端侧AI模型的创新发展。
此次合作不仅彰显了英特尔在AI领域的强大技术实力,也体现了其对创新生态系统的坚定承诺。通过整合双方的技术优势和资源,英特尔平台和MiniCPM 4.0系列模型联合解决方案的广泛应用和落地部署已经奠定了坚实的基础,有望在智能生活、生产力提升等多个场景中发挥关键作用。
展望未来,英特尔将继续与面壁智能保持紧密合作,同时积极拓展合作关系,不断探索AI技术的新边界。英特尔致力于通过持续创新,推动人工智能技术的普及与发展,构建更加智能、高效的未来社会。
快速上手指南 (Get Started)
- 参考代码:https://blog.csdn.net/inteldevzone/article/details/148473561
- llm-chatbot notebook:https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-chatbot
- GenAI API:https://github.com/openvinotoolkit/openvino.genai
- 魔搭社区OpenVINO™专区:https://www.modelscope.cn/organization/OpenVINO
- OpenVINO™ Model Hub:https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/model-hub.html
1基于SD Eagle2 优化前与优化后,2nd token推理速度的提升
2SKU 1 (Intel® Core™ Ultra 7 258V) Brand: Intel, OEM: Lenovo, Model: Yoga Air 15s ILL9, CPU: Core Ultra 7-258V, Memory: 32GB LPDDR5-8533MHz, Storage: WD PC SN740 1TB, OS: Windows 11, OS Version: 24H2 (26100.4061), Graphics: Intel Arc 140V GPU, Graphics Driver Version: 32.0.101.6790, Resolution: 2880 x 1800 200% DPI, NPU Driver:32.0.100.4023, Software Version: Openvino 2025.2.0-dev20250520, Openvino-genai 2025.2.0.0-dev20250520
SKU2 (Intel® Core™ Ultra 9 285H) Brand: Intel, OEM: Lenovo, Model: Ideapad Pro 5 16IAH10, CPU: Core Ultra 9-285H, Memory: 32GB LPDDR5-8533MHz, Storage: Kioxia KBG60ZNT1T02 1TB, OS: Windows 11, OS Version: 24H2 (26100.4061), Graphics: Intel Arc 140T GPU, Graphics Driver Version: 32.0.101.6790, Resolution: 2880 x 1800 200% DPI, NPU Driver:32.0.100.4023, Software Version: Openvino 2025.2.0-dev20250520, Openvino-genai 2025.2.0.0-dev20250520
3基于Spare Attention优化前与优化后,输入128K长文本,1st token加载时间缩短 与 2nd token 推理速度的提升
©英特尔公司,英特尔、英特尔logo及其它英特尔标识,是英特尔公司或其分支机构的商标。文中涉及的其它名称及品牌属于各自所有者资产。