南京大学Websoft研究团队构建了HuggingKG,这是一个基于Hugging Face社区的大型知识图谱,以及配套的多任务基准测试HuggingBench。
这两项资源的推出,将为开源资源的推荐、分类和溯源带来全新的解决方案。两项资源均已在Hugging Face社区开源,同时,为了确保资源的的可持续性和实验结果的可复现性,研究团队在GitHub开源了知识图谱构建和基准测试的代码。这将允许社区成员根据自身需求定制和扩展这些资源。
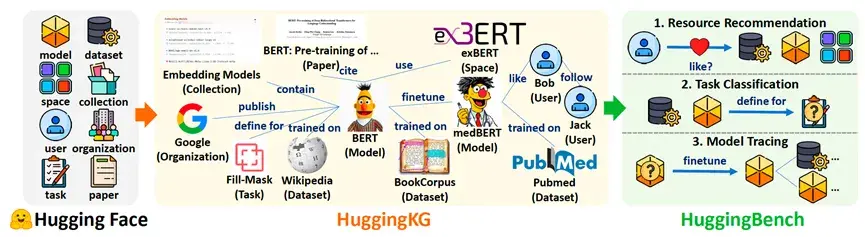
1. HuggingKG:开源机器学习资源的知识图谱
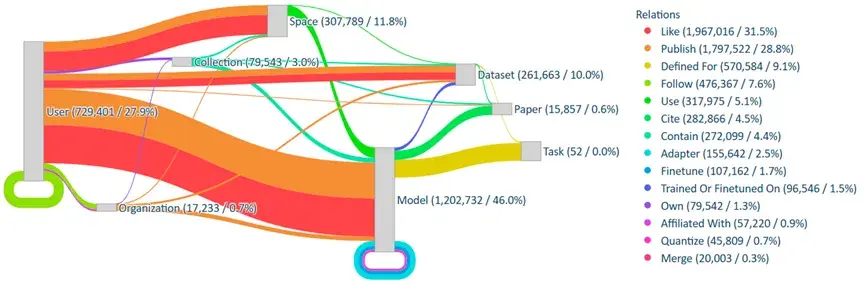
HuggingKG是首个专注于开源机器学习资源管理的知识图谱,它整合了来自Hugging Face社区的260万节点和620万条边,涵盖了模型、数据集、用户、任务等多种实体类型,以及它们之间的复杂关系。这些关系不仅包括模型演化(如adapter、finetune)和用户互动(如like、follow),还包含了丰富的文本属性(如model card、dataset card)。
通过这种结构化的表示,HuggingKG能够支持复杂的查询和分析任务,例如追踪模型的演化历史、推荐相关数据集以及识别资源类别等。
2. HuggingBench:多任务基准测试
为了评估开源资源管理中的实际挑战,研究团队还开发了HuggingBench,这是一个包含三个创新测试集的多任务基准测试,涵盖了资源推荐(resource recommendation)、任务分类(task classification)和模型溯源(model tracing)等任务。这些测试集利用 HuggingKG 的结构化数据,提供了独特的分析视角和挑战。
论文:https://arxiv.org/abs/2505.17507
代码:https://github.com/nju-websoft/HuggingBench
数据:https://huggingface.co/collections/cqsss/huggingbench-67b2ee02ca45b15e351009a2