INTELLECT-2 已正式发布,该项目展示了一种新的大模型训练方式:利用全球分布的、无需许可的计算贡献者组成的动态、异构网络,以完全异步的方式进行强化学习训练。
INTELLECT-2 具备前沿的推理性能,支持异构计算节点,并允许无需授权的贡献,能对 32B 参数模型进行去中心化 RL 训练:
-
prime-RL:新推出的开源库,用于完全异步的去中心化RL,基于具备容错的去中心化训练框架prime开发。
-
SYNTHETIC-1 & GENESYS:用于RL任务众包和验证环境的库。
-
TOPLOC:实现高效、可验证的推理方法,用于验证INTELLECT-2中所有去中心化rollout节点的计算。
-
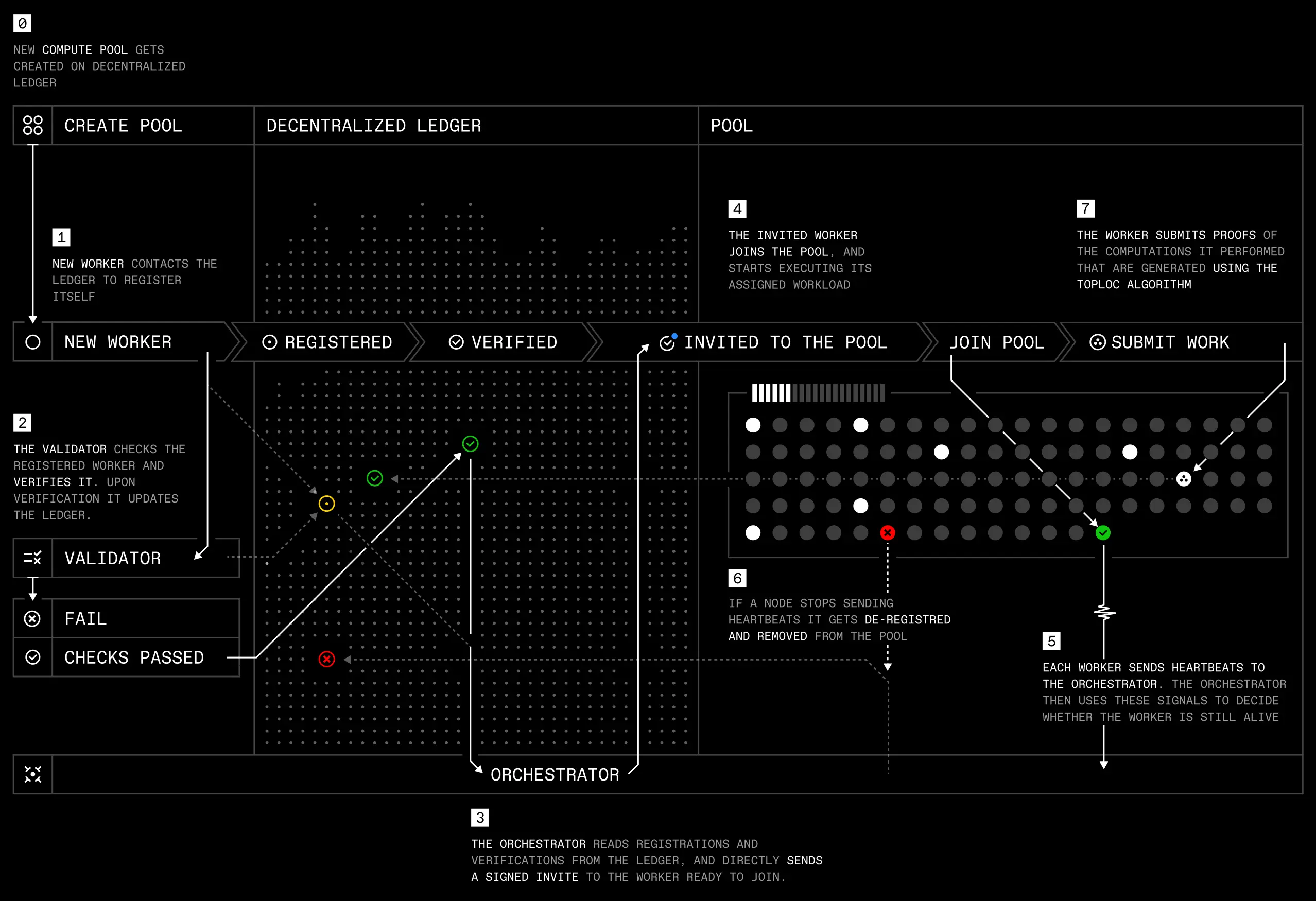
协议测试网:提供基础设施和经济激励,用于聚合和协调全球计算资源,打造真正自主的开源AI生态系统。
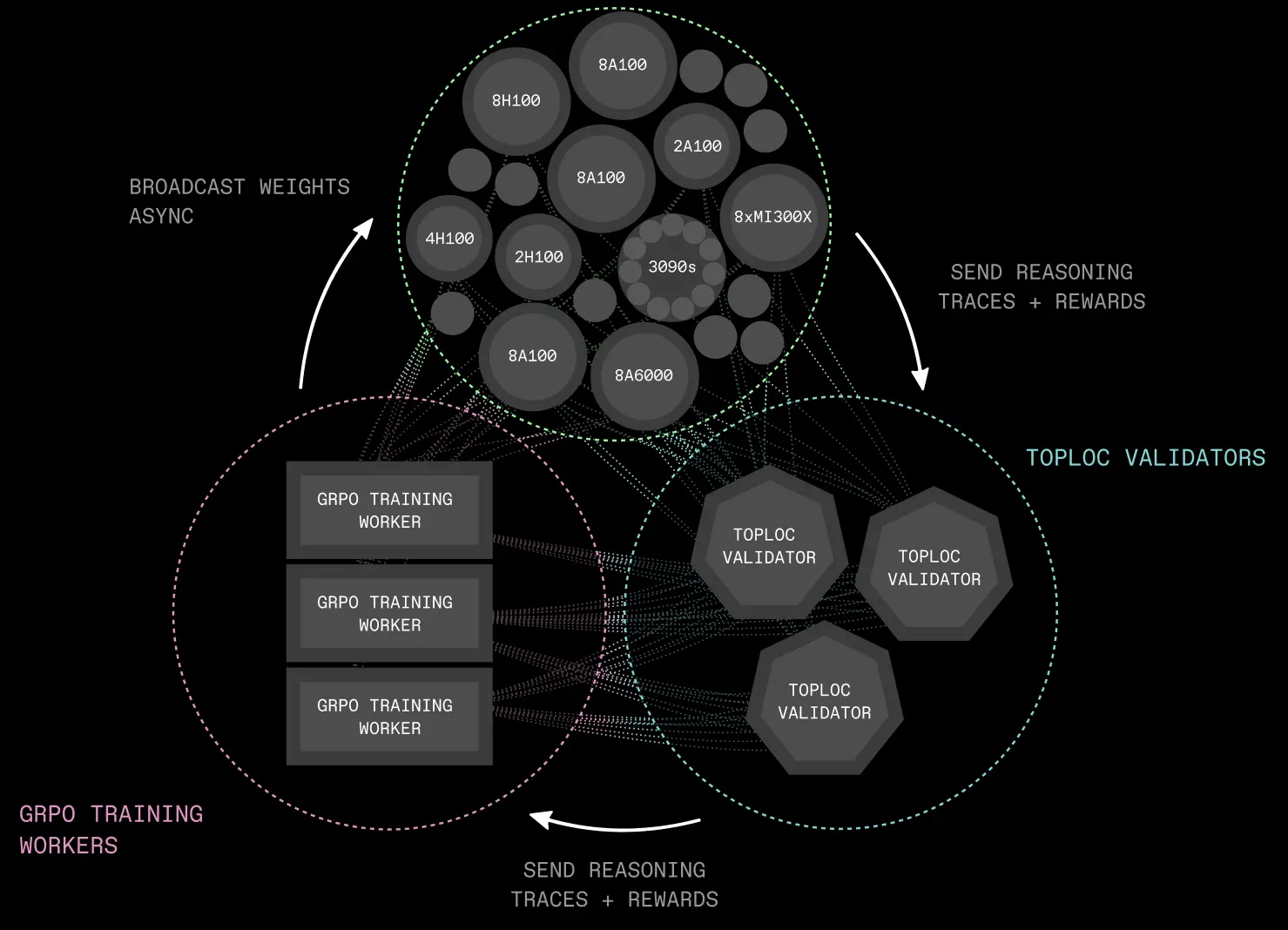
INTELLECT-2基础设施主要由三个组件构成:
-
推理采样节点(Inference Rollout Workers):一组去中心化节点,用最新的策略模型,从环境中收集推理轨迹(reasoning rollouts),并计算相应的奖励。
-
TOPLOC验证节点(TOPLOC Validators):负责高效验证无需授权的rollout工作节点的推理计算,打造无需信任的系统。
-
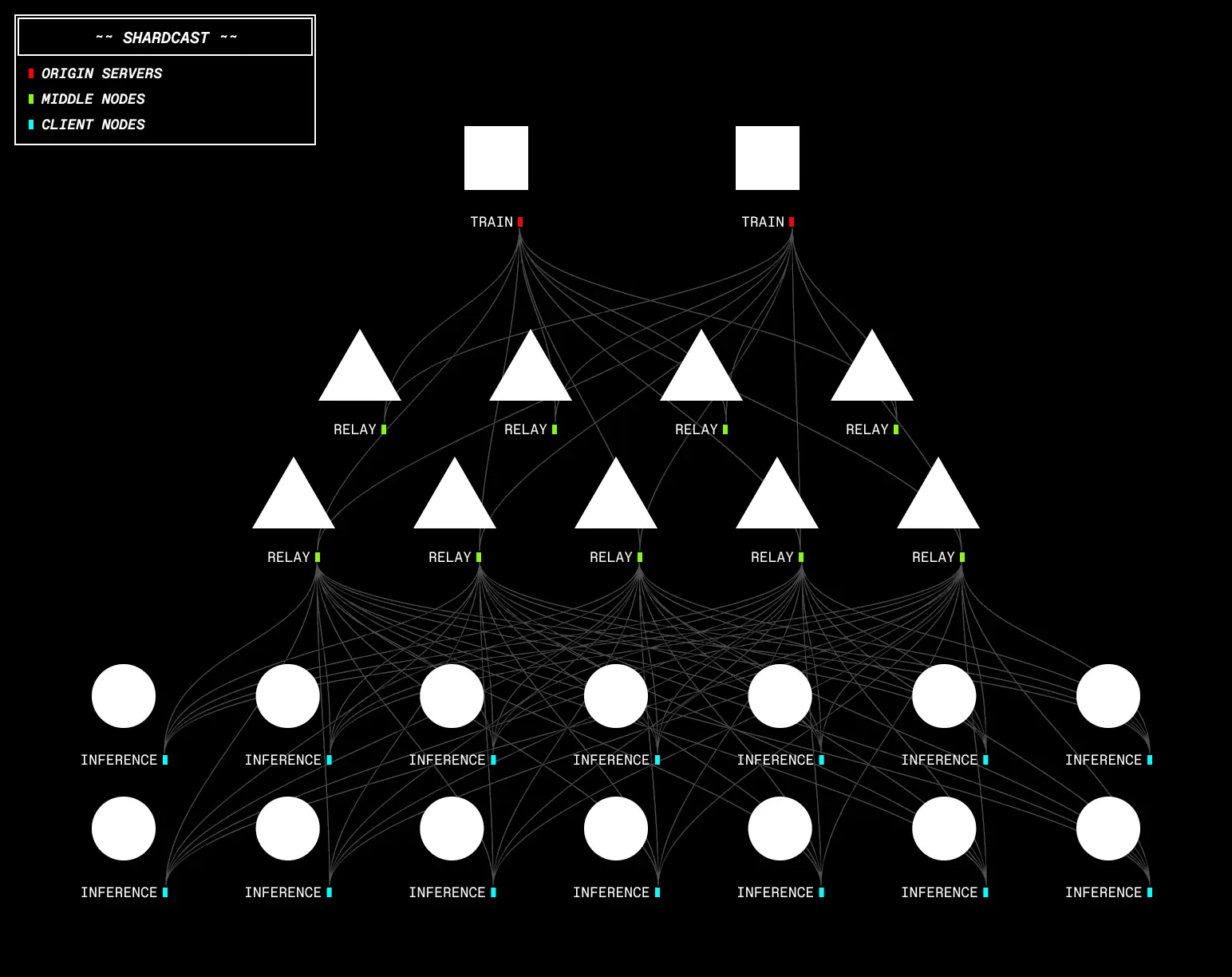
GRPO训练节点(GRPO Training Workers):从去中心化推理采样节点收集到新生成的数据后,采用DeepSeek的GRPO训练方法进行训练。训练完成后,这些训练节点会通过Shardcast库,将更新后的权重广播给所有推理节点,以启动下一轮数据收集。
该基础设施具备以下特性:
-
完全消除通信开销:通过异步强化学习,新策略模型的广播与正在进行的推理和训练完全重叠,通信不再成为瓶颈。
-
支持异构推理节点:允许任何人按自己的节奏生成推理轨迹(reasoning traces),跨节点处理速度没有统一要求。
-
资源需求低:在这种训练设置中,占计算资源大头的推理节点可以在消费级GPU上运行。例如,配备4块RTX 3090 GPU的机器,足以支持32B参数模型的训练。
-
实现高效验证:推理计算的验证过程,不会引入训练瓶颈。
详情查看:https://www.primeintellect.ai/blog/intellect-2-release