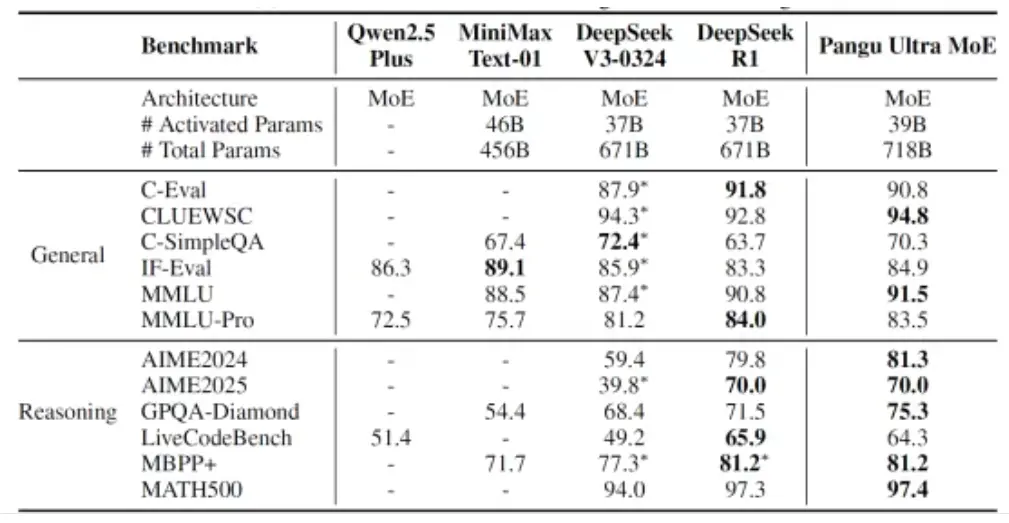
华为推出参数规模7180亿的新模型——盘古Ultra MoE,这是一个全流程在昇腾AI计算平台上训练的准万亿MoE模型。主要的架构和训练特性如下:
- 超大规模和超高稀疏比:采用 256 个路由专家,每个 token 激活 8 个专家,模型总参数量 718B,激活量 39B。
- MLA 注意力机制:引入 MLA(Multi-head Latent Attention),有效压缩 KV Cache 空间,缓解推理阶段的内存带宽瓶颈,优于传统 GQA 方案。
- MTP 多头扩展:采用单头 MTP 进行训练,后续复用 MTP 参数扩展至多头结构,实现多 Token 投机推理,加速整体推理过程。
- Dropless 训练:采用 Dropless 训练可以避免 Drop&Pad 训推不一致问题,并且提升训练的数据效率。
- RL 训练:采用迭代难例挖掘与多能力项均衡的奖励函数,并参考 GRPO 算法,提升了模型的训练效率与最终推理性能。
华为同时发布盘古Ultra MoE模型架构和训练方法的技术报告。在训练方法上,华为首次披露在昇腾CloudMatrix 384超节点上,打通大稀疏比MoE强化学习(RL)后训练框架的关键技术,使RL后训练进入超节点集群时代。
此外,近期发布的盘古Pro MoE大模型,在参数量为720亿,激活160亿参数量的情况下,在大模型榜单SuperCLUE的2025年5月排行榜上,位居千亿参数量以内大模型排行并列国内第一。