小红书 Hi Lab 开源了其首个自研多模态大模型 dots.vlm1。该模型基于12亿参数的 NaViT 视觉编码器 和 DeepSeek V3大语言模型,从零开始完全训练,其卓越性能在多模态视觉理解与推理能力上已接近当前领先的闭源模型,如 Gemini2.5Pro 和 Seed-VL1.5,标志着开源多模态模型的性能达到了新的高度。
dots.vlm1的核心亮点在于其原生自研的 NaViT 视觉编码器。与传统基于成熟模型微调的方式不同,NaViT 从零训练,并支持动态分辨率,能够更好地适应多样化的真实图像场景。该模型还通过结合纯视觉与文本视觉的双重监督,极大提升了其泛化能力,尤其是在处理表格、图表、公式、文档等非典型结构化图片时表现出色。
在数据方面,Hi Lab 团队构建了规模庞大且清洗精细的训练集。他们通过自主重写网页数据和自研 dots.ocr 工具处理 PDF 文档,显著提升了图文对齐的质量,为模型的跨模态理解能力打下了坚实基础。
评测结果表明,dots.vlm1 在 MMMU、MathVision 和 OCR Reasoning 等多项基准测试中,达到了与 Gemini2.5Pro 和 Seed-VL1.5相当的水平。在复杂的图表推理、STEM 数学推理以及长尾细分场景识别等应用中,dots.vlm1展现出卓越的逻辑推理和分析能力,完全胜任奥数等高难度任务。
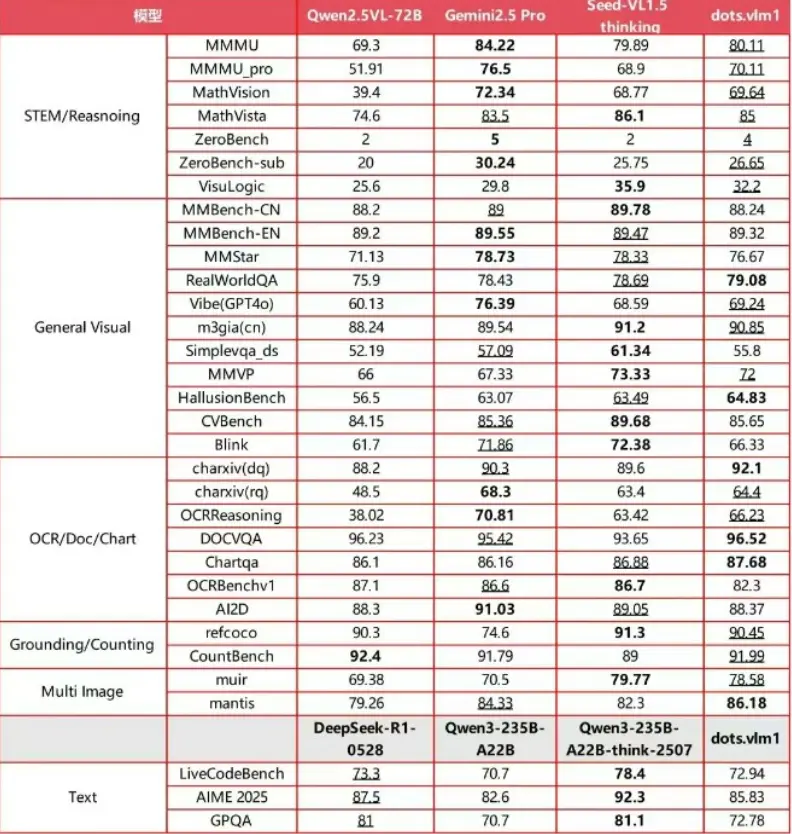
尽管在文本推理的极复杂任务上与 SOTA 闭源模型仍有差距,但其通用数学推理和代码能力已与主流大语言模型持平。
Hi Lab 团队表示,未来将继续优化模型。他们计划扩大跨模态数据规模,并引入强化学习等前沿算法,进一步提升推理泛化能力。通过开源 dots.vlm1,小红书致力于为多模态大模型生态系统带来新的动力,推动行业发展。