微软近日发布了20亿参数的1-bit模型——BitNet b1.58 LLM家族,称此新型模型比主流Transformer LLM更不占内存且更低能耗,适合在CPU或较小型硬件平台上执行。
Hugging Face 地址:https://huggingface.co/microsoft/bitnet-b1.58-2B-4T
微软研究院与中国科学院研究人员2023年发布名为《BitNet: Scaling 1-bit Transformers for Large Language Models》的论文,首度发布为大语言模型设计的1-bit Transformer架构,称为BitNet。
https://arxiv.org/pdf/2310.11453

微软表示,这是第一个参数20亿的开源原生1-bit LLM。它是以4兆字词的数据集训练而成,具备4096 token的context length。
研究团队说明,在BitNet b1.58模型中,单一参数或权重是三元( {-1, 0, 1})的。此类新模型架构引入BitLinear作为nn.Linear层的替代,能够训练1-bit的权重,训练出的LLM和同样参数量及训练字词的全精度(FP16)Transformer LLM模型相较,具有相同的困惑度(perplexity)及终端任务性能,但却能大幅减少了内存占用和能源耗损,就延迟性及传输率表现而言也更省成本。
微软团队认为,最重要的是, BitNet b1.58提出了新的模型扩展法则,可用于训练高性能及低成本的下时代LLM,而且BitNet b1.58对CPU设备更为友善,更适合执行于边缘和移动设备上,显示出性能和能力。研究人员相信1-bit LLM可催生出新的硬件和为其优化的系统。
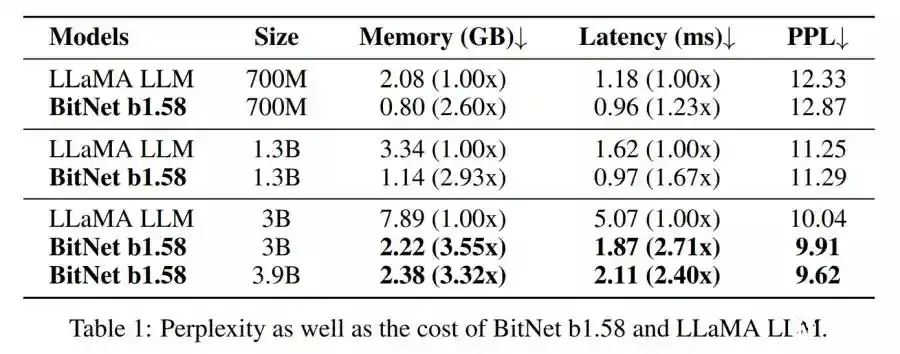
根据研究团队比较测试,BitNet b1.58-3B/3.9B版本占用内存为2.22GB及2.38GB,远小于LLaMA-3B的7.89GB。延迟性来看,BitNet b1.58-3B/3.9B各为1.87ms及2.11ms,优于LLaMA-3B的5.07ms。二个BitNet b1.58的PPL以及零样本训练准确性表现,也都超越LLaMA-3B。
微软已在Hugging Face开源三个版本的Bitnet-b1.58模型权重,一是BitNet b1.58 2B4T,适合模型部署。二是Bitnet-b1.58-2B-4T-bf16,仅适合模型训练或微调。BitNet-b1.58-2B-4T-gguf则包含GGUF格式的权重,兼容bitnet.cpp函数库用于CPU推论。
论文地址:https://arxiv.org/abs/2504.12285

但微软也警告开发人员,目前Transformers函数库的执行方式并没有包含为BitNet设计、高度优化的计算核心,因此无法彰显BitNet架构的好处。
所以,虽然开发人员可能会因这个模型使用了量化(quantized)的权重而看到节省了一点内存,但无法看出速度快、能耗低等性能优势,因为transformers本身不支持BitNet所需要的底层运算加速。想要体验论文中提到的性能(包括低功耗和高效率的推论),必须使用官方提供的C++ 实例版本:bitnet.cpp。