当前尖端的向量近邻搜索算法,主要以图搜索算法为主,此类算法为了能够最大化搜索的速度与准确度,需要将对应的索引结构和原始数据存放在内存中,显然这不仅大大提高了成本,还限制了数据集的大小。
例如在当前主流的内存型 HNSW 算法下,
业界常用的内存估算方式是:向量个数 * 4 * (向量维度 + 12)。那么
在 DEEP 10M(96维)的
1
千万数据就需要内存达到 4GB 以上,但是
通过 DiskANN 优化后,仅需要 70
MB
的内存就可以对海量数据高效的进行检索;在 MS-MARCO(1024 维)的 1.38 亿条记录里,需要内存更是高达 534GB,这样检索 1.38 亿的数据需要 12 个 64GB 的节点。
按照上面的估算公式,到了 10 亿级别就需要大约 100 个节点,到 100 亿级别需要的节点数为 1000 个左右,这个规模的服务在资源成本和稳定性上都面临了极大的挑战。我们在服务客户的过程中,发现相比于低延迟检索需求,大部分客户更关注成本和稳定性,因此,火山引擎云搜索团队在原先已经支持的 HNSW、IVF 等低延迟的算法引擎的基础上,引入了内存和磁盘更好平衡的
DiskANN
算法
,目前已经在
200
亿单一
向量库
得到落地验证并取得预期效果
。
DiskANN 算法的关键在于,仅将轻量级的索引结构置于内存中,而海量的原始数据以及构建好的图结构存放于磁盘,同时借助磁盘的多路读取能力,缓解内存压力的同时,
高效完成近邻检索任务的三大目标:海量数据、高召回率、低时延。
DiskANN 论文提到可以节约 95% 的资源,从我们落地的多个用户案例来看,非常接近这个收益值,客户仅需几十台机器就稳定高效地支撑百亿级业务需求。除了资源成本的收益之外,大规模数据应用场景下也极大提高了系统的稳定性。这是因为 DiskANN 极大减少了对内存资源的依赖,因此也具备了非常高的可扩展性,在我们的实践经验中也得到验证,从千万数据规模到十亿再到百亿,查询性能的波动非常小,具备非常高的系统可预测性。
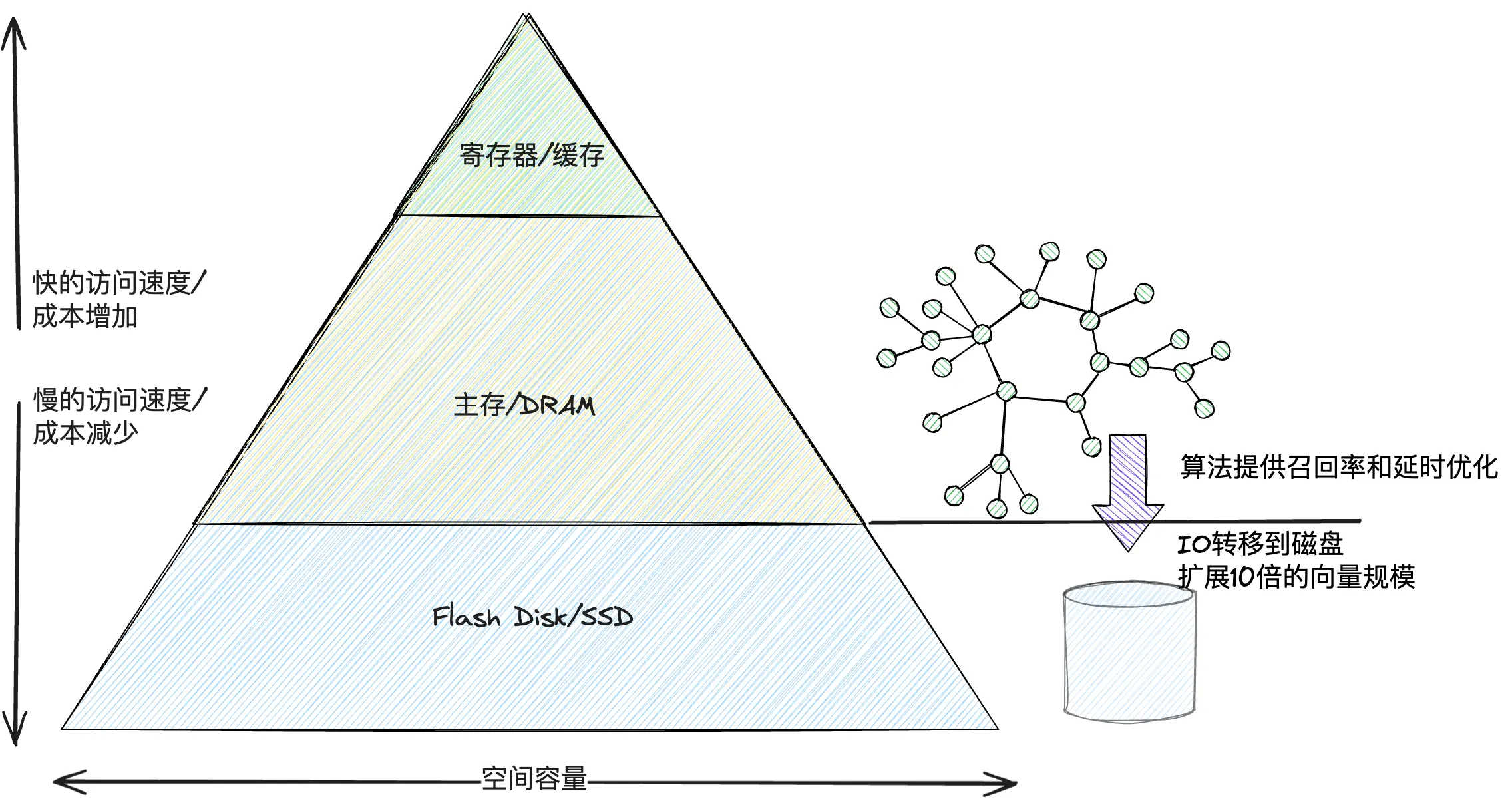
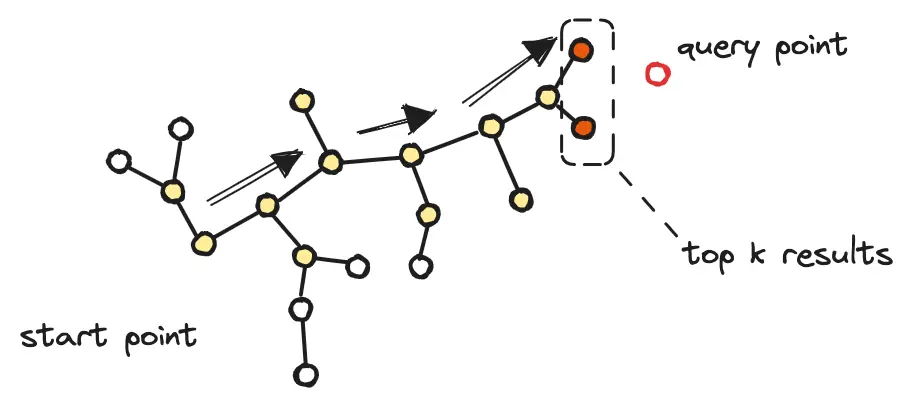
什么是近邻检索
近邻检索问题,顾名思义便是给定一个数据集 P 与一个查询向量 Q,我们需要从中找出最近的 K 个结果。随着数据集规模和数据维度的增加(
curse of dimensionality),穷举遍历比较的方式便不再适用,更好地方式是取出近似的 K 个,然后引入召回率的概念,来表征近似结果集的好坏。
针对此问题,应运而生了不同的算法,这些算法对应的索引结构也都基本受限于这些权衡:召回率、读写时延、成本等。
比如,基于图结构的算法,选择将数据作为图中的数据点,而相近的点之间连接为边;查询向量从入口点出发,不断缩短距离,最终收敛得到结果。该类算法需要将构建的图结构全部存放于内存中,召回率高,读写时延低,但内存成本高,主流代表算法为 HNSW、NSG。而为了解决海量数据的存储成本问题,另一类基于聚类压缩的算法,将数据按簇进行聚类,选择不保存原始向量数据,而是通过乘积量化的方法(
product quantization),将原始数据压缩后再执行后续的流程。此类算法的特点在于内存成本大幅降低,但对应的缺陷就是召回率明显降低,主流算法为 IVF_PQ。
上述介绍算法,要么受限于海量数据存储带来的内存成本压力,要么为了减轻内存成本压力而选择牺牲召回率,那么是不是可以考虑跳出内存的限制,直接将数据存放到磁盘中。显然,磁盘中数据的读写速度要远低于内存,
因此我们需要考虑
的问题是
:1. 如何能够减少访问磁盘的频率,先访问内存,只有真正需要原始向量时再去访问磁盘;2. 如何组织数据结构,保证一次读盘操作便可以取出相关的节点边图信息
。
DiskANN 实现
为了解决上述问题,
DiskANN
算法首先提出了新的图结构
Vamana,Vamana 图与 HNSW、NSG 图类似,区别在于初始图的选择、以及构图剪枝过程中
引入宽松参数,在图直径和节点连通度上达到平衡,图的质量相对有所提升。
其次,为了规避多次随机读写磁盘数据,DiskANN 算法
结合两类算法:聚类压缩算法和图结构算法,一是通过压缩原始数据,仅将压缩后的码表信息和中心点映射信息放到内存中,而原始数据和构建好的图结构数据存放到磁盘中,只需在查询匹配到特定节点时到磁盘中读取;二是修改向量数据和图结构的排列方式,将数据点与其邻居节点并排存放,这种方式使得一次磁盘操作即可完成节点的向量数据、邻接节点等信息的读取,通过对以上两种算法的结合可以
大幅提升
向量召回
的读取效率,降低图算法的内存,提升召回率
。
构图流程
-
均匀采样数据,构建 pq 中心点信息以及压缩数据信息:
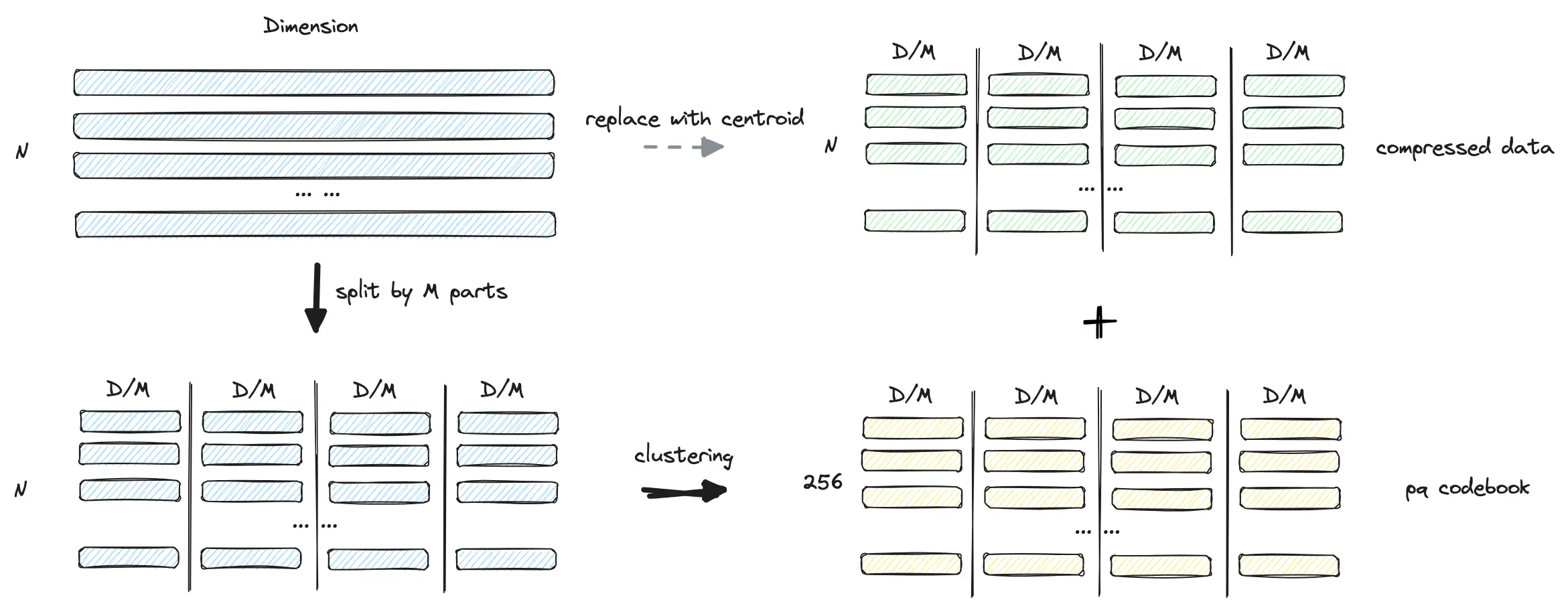
-
构建 Vamana 图,从随机图开始不断执行建边和剪枝操作,保证图的稠密度:
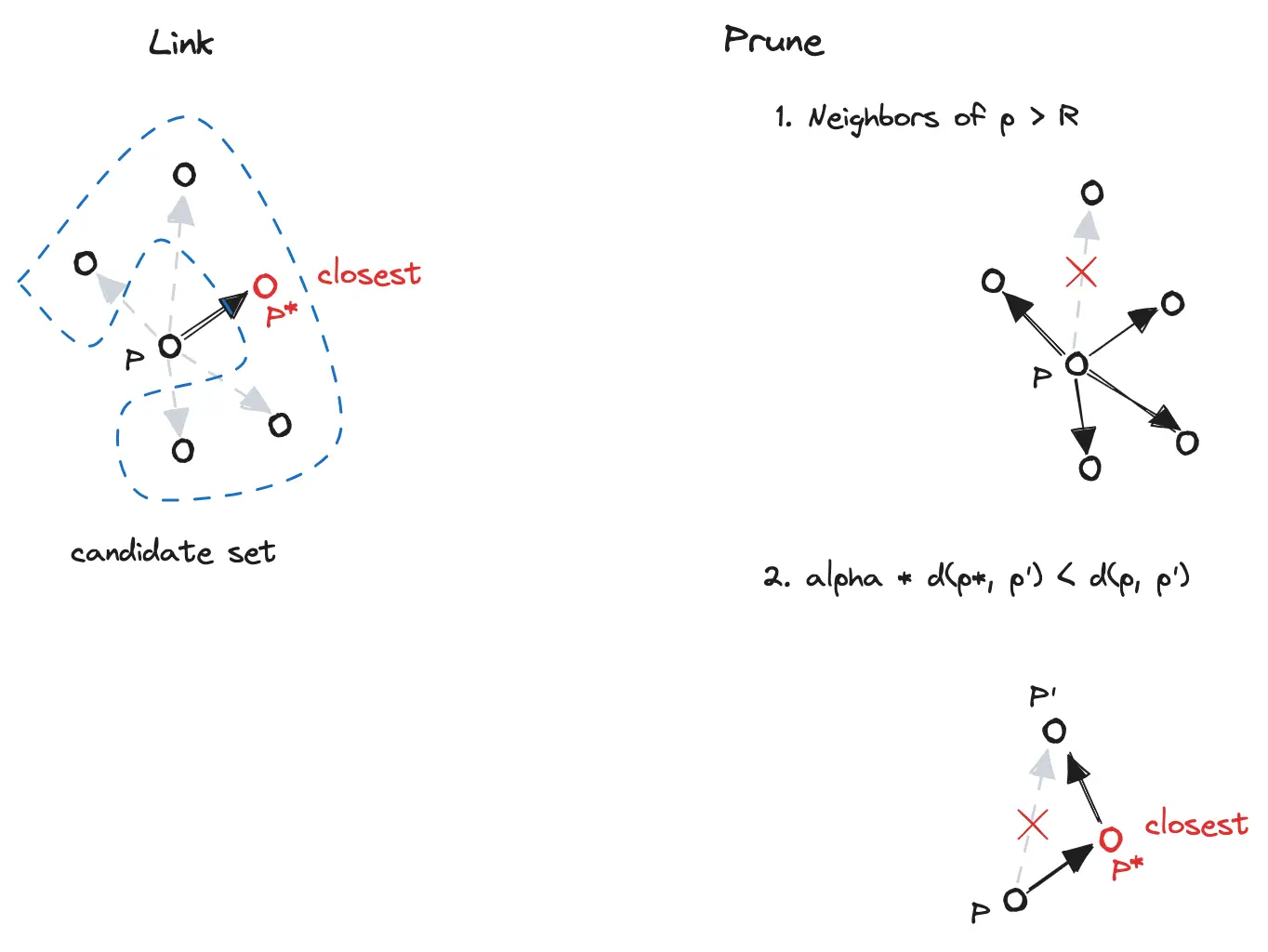
-
创建磁盘图结构,向量数据和邻接节点紧凑排列:
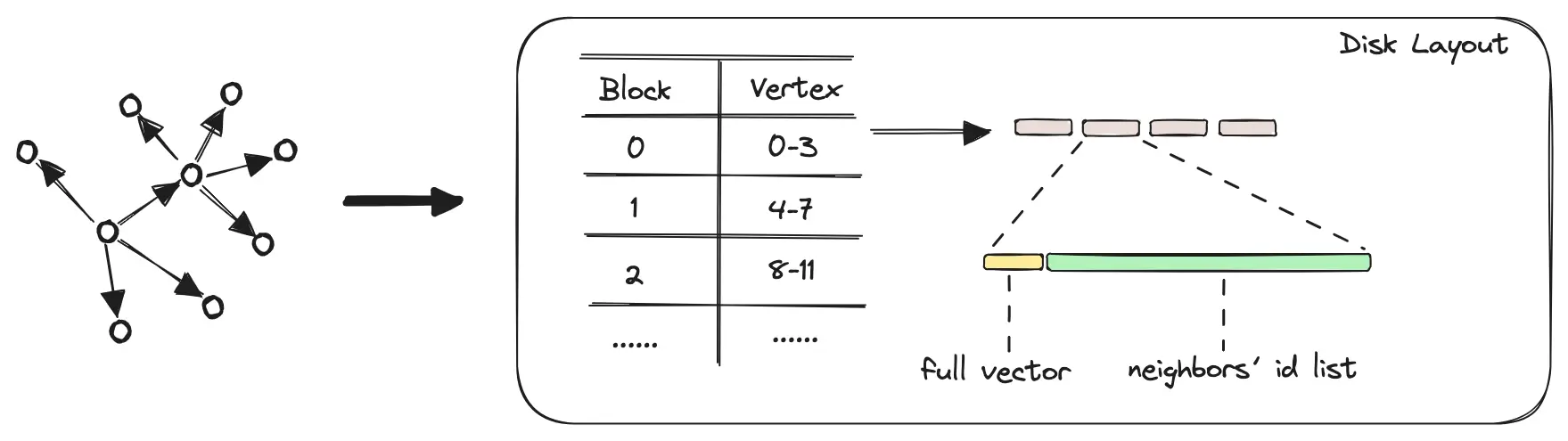
查询流程
-
给定查询向量 q,从入口点 p 出发,开始搜索 k 近邻:
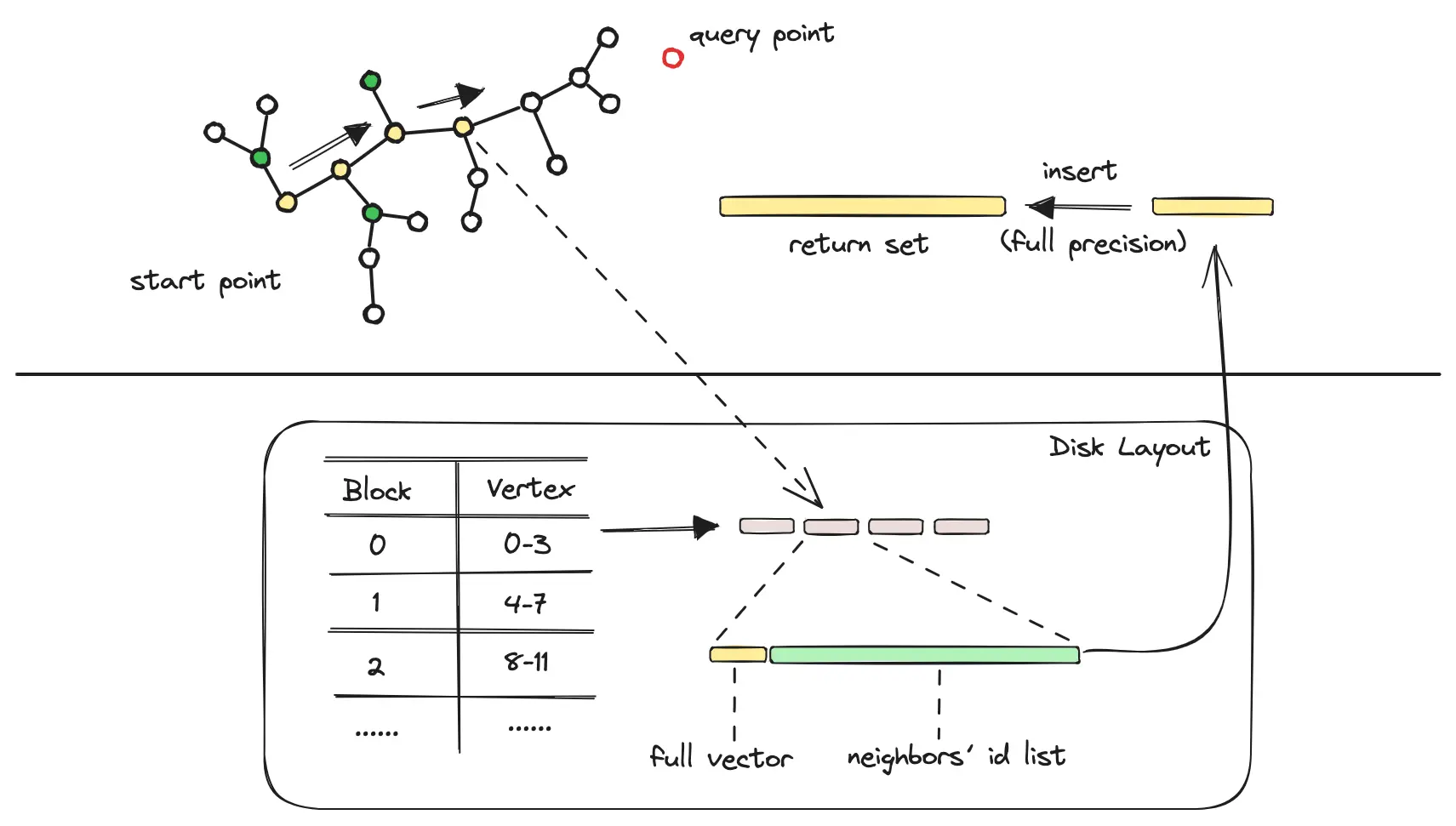
-
当前遍历到的数据点,读取磁盘,以原始向量计算与查询节点的精确距离,进入结果集队列(Return Set,队列内以距离进行排序)。
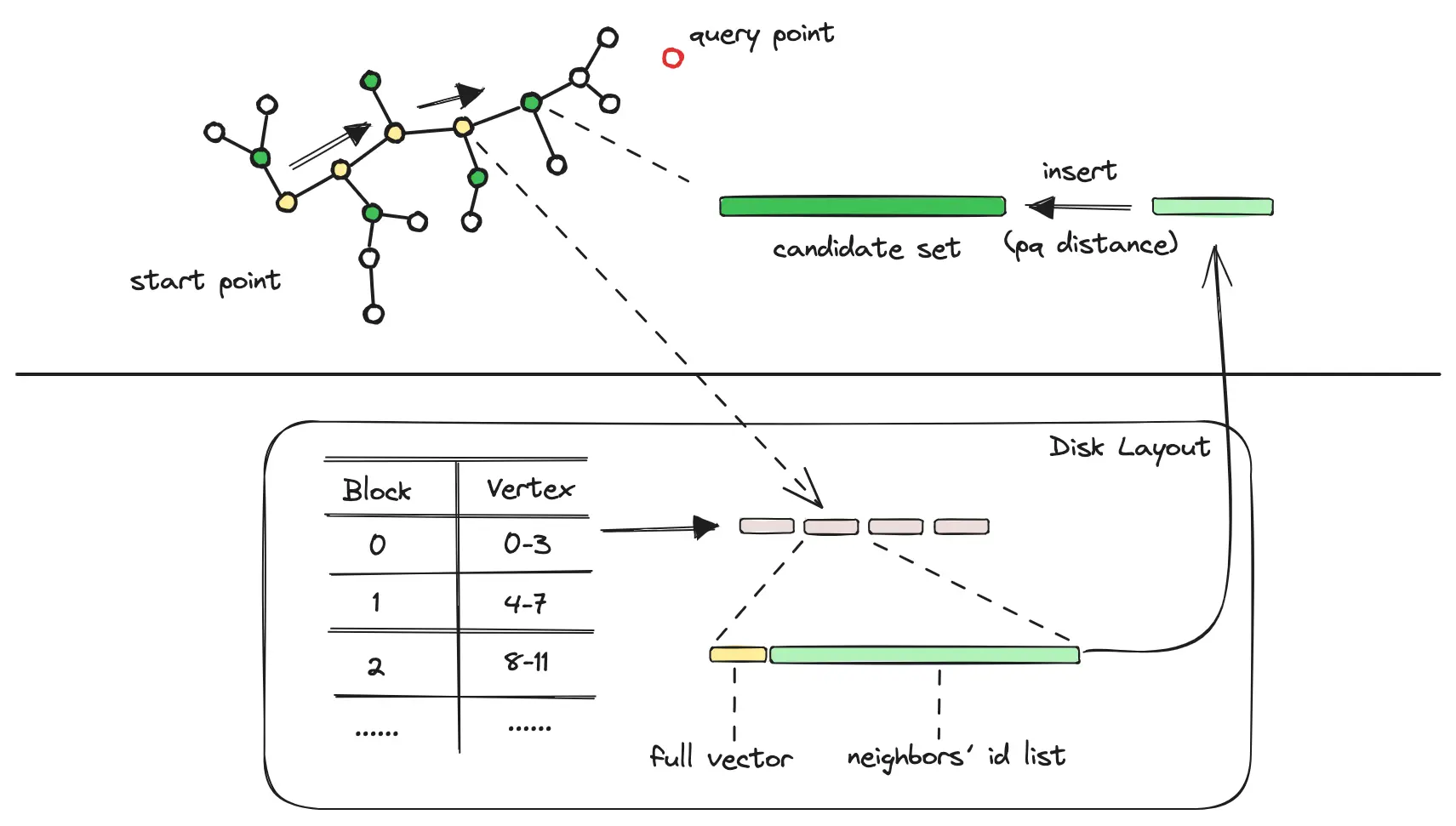
-
当前节点的所有邻接节点,以 pq 数据计算与查询节点的近似距离,进入候选集队列(Candidate Set,队列内以距离进行排序)。
-
从候选集队列的头部取出 pq 距离最近的数据点。
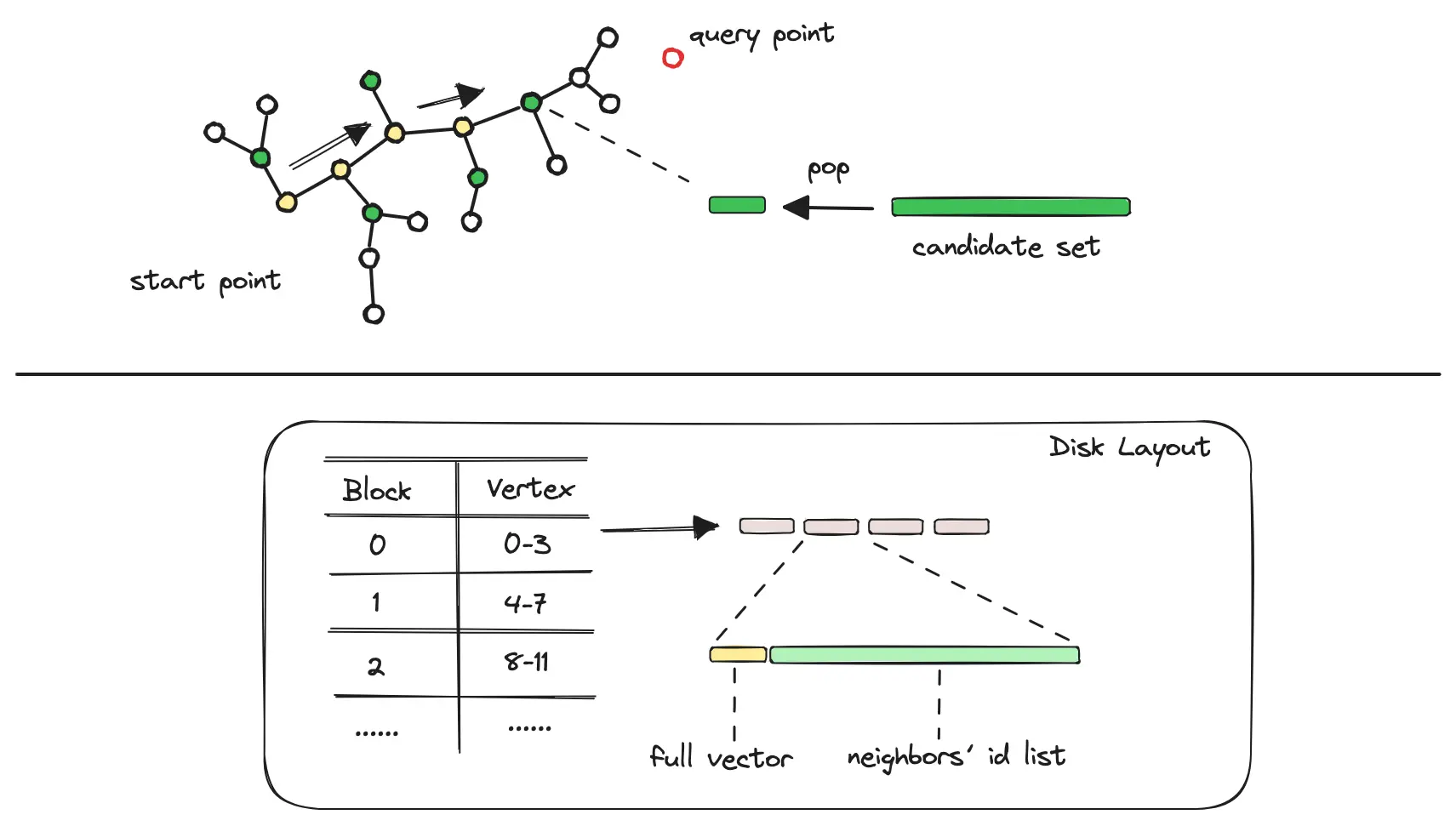
-
重复执行 2-4 步骤,直至候选集中的数据点均被访问过,最终返回结果集。
实现效果
我们能够通过标注数据集验证可以看到使用 DiskANN 可以带来 10 倍以上的内存资源的提升,并且在召回率、性能上依旧能保持高效的检索能力。
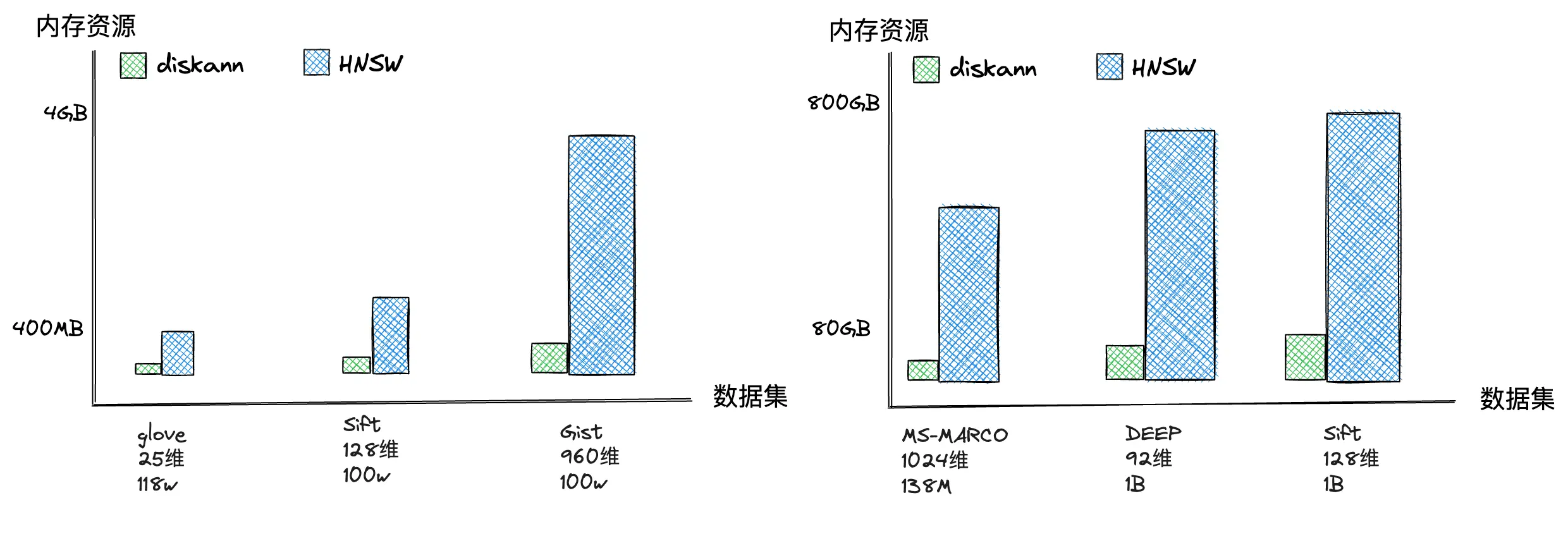 *数据来源见文末参考论文
*数据来源见文末参考论文
总结
DiskANN 通过构建低时延、高召回率的 Vamana 图,同时辅以内存与 SSD 磁盘之间的高效协同作业,召回率和主流的 HNSW 图算法基本保持一致,内存资源占用相比于基于图的算法要大幅减少,在召回率要求高、时延查询可接受的场景下,无疑是最具性价比的海量数据向量搜索算法。
云搜索通过引入 DiskANN,以最低的成本构建海量数据检索,帮助客户在信息检索和 RAG 检索中能够大规模、高精度、低成本高效的构建检索应用。
参考
《DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node》
《HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory》
《GRIP: Multi-Store Capacity-Optimized High-Performance Nearest Neighbor Search for Vector Search Engine》
《AiSAQ: All-in-Storage ANNS with Product Quantization for DRAM-free Information Retrieval》
《A Comprehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search》