AI 初创公司 Galileo 宣布推出其最新的 Hallucination Index,一个以检索增强生成 (RAG) 为重点的评估框架,对来自 OpenAI、Anthropic、Google 和 Meta 等品牌的 22 个(12 个开源 LLM 和 10 个专有 LLM)领先的生成式 AI 大语言模型性能进行了比较排名。
Hallucination Index 使用 Galileo 专有的评估指标“context adherence”对开源和闭源模型进行了测试。测试模型的输入量从 1,000 到 100,000 token 不等,以了解短语境(少于 5k token)、中等语境(5k 到 25k token)和长语境(40k 到 100k token)的性能。
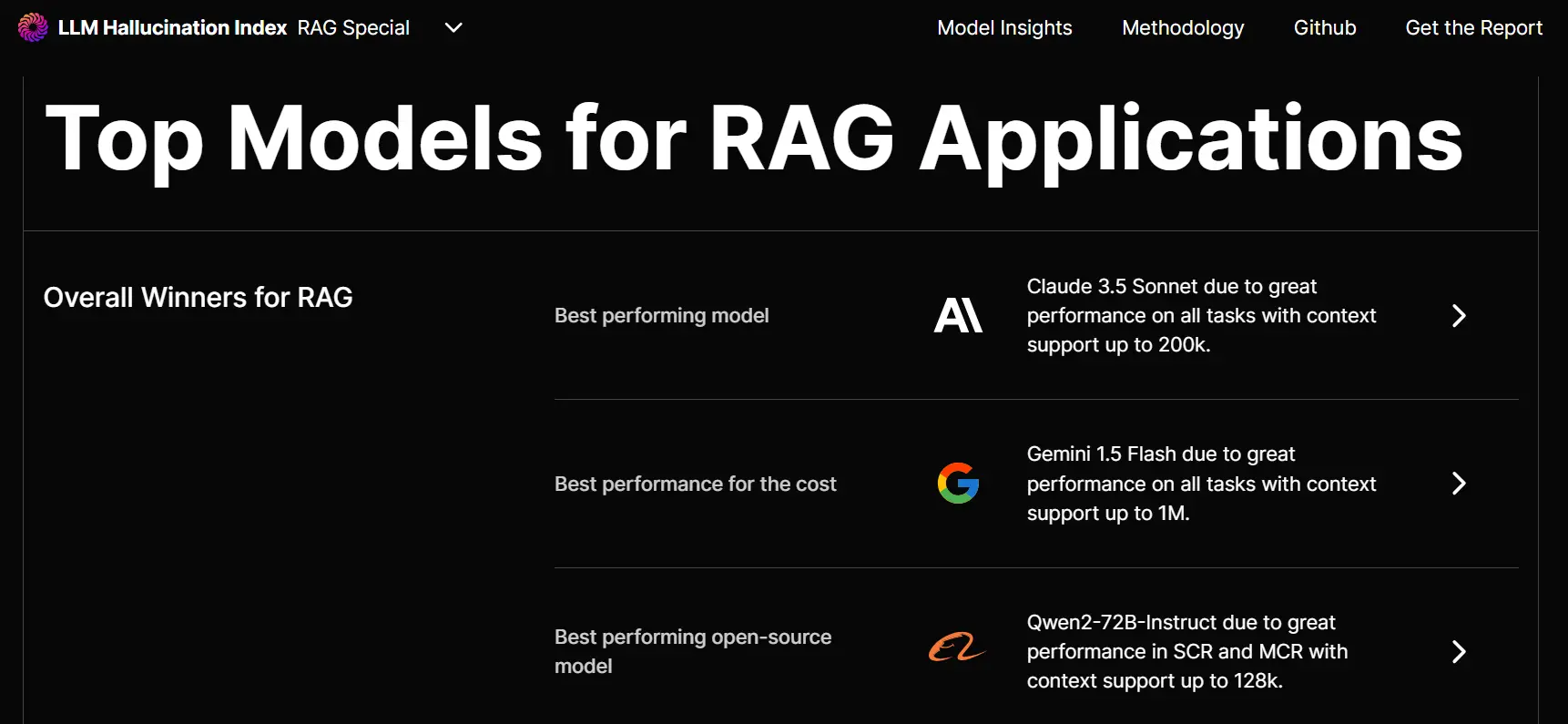
- 综合表现最佳模型: Anthropic 的 Claude 3.5 Sonnet。该闭源模型在短、中、长上下文场景中的表现均优于竞争模型。Anthropic 的 Claude 3.5 Sonnet 和 Claude 3 Opus 在各个类别中的得分始终接近满分,击败了去年的冠军 GPT-4o 和 GPT-3.5。在短语境中得分为 0.97(满分 1 分)。
- 成本表现最佳模型: Google 的 Gemini 1.5 Flash。Google 模型在所有任务上均表现出色,在短、中、长上下文场景中分别获得了 0.94、1 和 0.92 的准确率,因此成为性价比最高的机型。
- 最佳开源模型:阿里巴巴的 Qwen2- 72B -Instruct。该开源模型在短和中语境背景下表现最佳,得分最高。
Galileo 联合创始人兼首席执行官 Vikram Chatterji 表示:“由于幻觉仍然是一个主要障碍,我们的目标不仅仅是对模型进行排名,而是为 AI 团队和领导者提供他们所需的真实数据,以便他们以合适的价格采用合适的模型,完成合适的任务。”
主要发现和趋势:
- 开源缩小差距:由于专有训练数据,Claude-3.5 Sonnet 和 Gemini 1.5 Flash 等闭源模型仍然表现最佳,但 Qwen1.5- 32B -Chat 和 Llama-3- 70b -chat 等开源模型正在通过幻觉性能的改进和比闭源模型更低的成本壁垒迅速缩小差距。
- 长上下文长度的整体改进:当前的 RAG LLM,如 Claude 3.5 Sonnet、Claude-3-opus 和 Gemini 1.5 pro 001 在扩展上下文长度的情况下表现尤为出色 - 不会损失质量或准确性 - 反映了模型训练和架构方面所取得的进展。
- 大模型并不总是更好:在某些情况下,小模型的表现优于大模型。例如,Gemini-1.5-flash-001 的表现优于大模型,这表明模型设计的效率有时比规模更重要。
- 从国家到全球焦点:美国以外的法学硕士,例如 Mistral 的 Mistral-large 和阿里巴巴的 qwen2- 72b -instruct,是该领域的新兴参与者,并且越来越受欢迎,代表了全球创建有效语言模型的努力。
- 改进空间:虽然 Google 的开源 Gemma-7b 表现最差,但他们的闭源 Gemini 1.5 Flash 模型始终名列前茅。
详情可查看 :https://www.rungalileo.io/hallucinationindex