快手宣布并开源其最新自研的多模态大语言模型 Kwai Keye-VL。
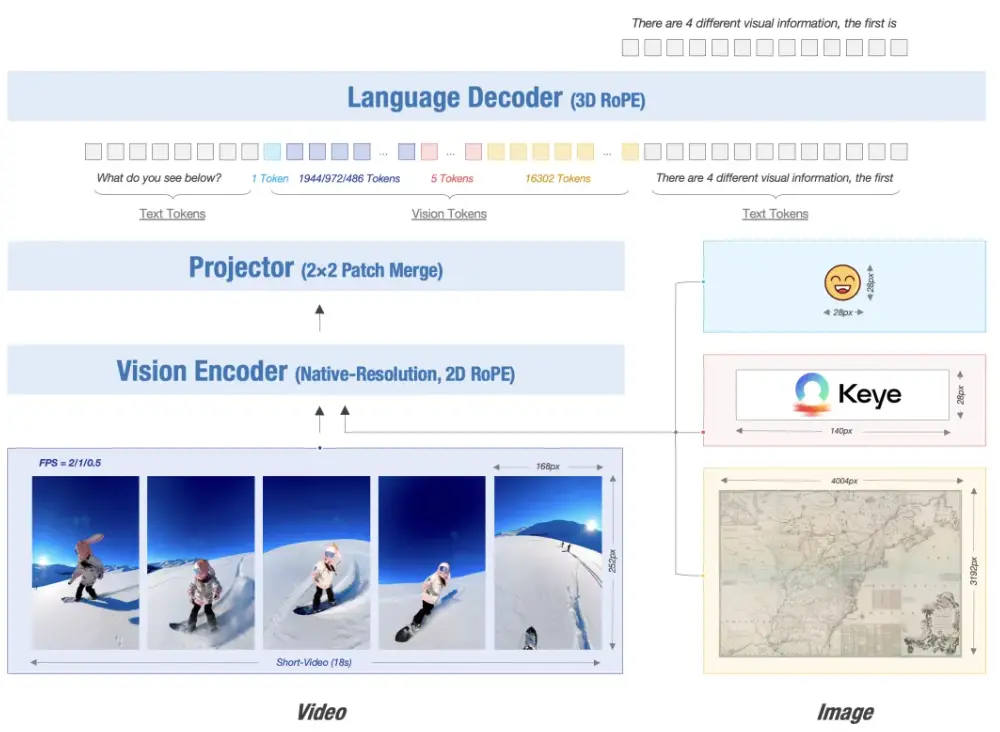
根据介绍,Kwai Keye-VL 以 Qwen3-8B 语言模型为基础,引入了基于开源 SigLIP 初始化的 VisionEncoder,能够深度融合并处理文本、图像、视频等多模态信息,凭借其创新的自适应交互机制与动态推理能力,旨在为用户提供更智能、全面的多模态交互体验。
Kwai Keye-VL 支持动态分辨率输入,按原始比例将图像切分为 14x14 patch 序列,由一个 MLP 层将视觉 Token 进行映射与合并。模型采用 3D RoPE (旋转位置编码)统一处理文本、图像和视频,并通过位置编码与时间戳对齐,精准捕捉视频时序变化。
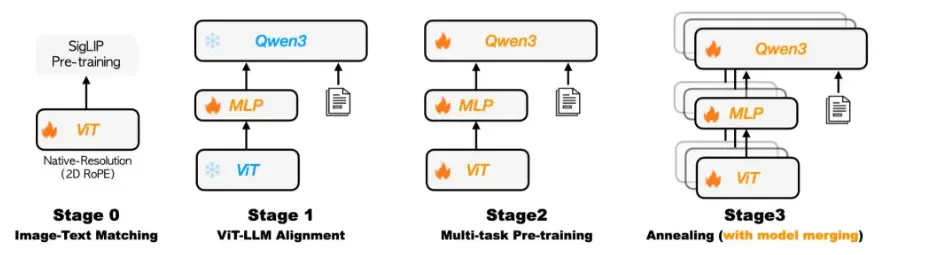
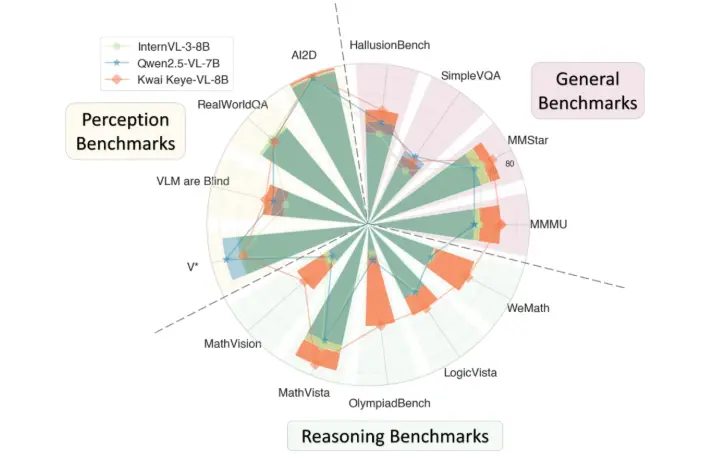
在视觉理解与逻辑推理能力方面,Kwai Keye-VL 的综合感知能力媲美同规模顶尖模型,并在复杂推理任务中展现出显著优势。尤其是逻辑推理方面,Kwai Keye-VL 在最新的 2025 年高考全国数学卷中取得了140分的成绩。
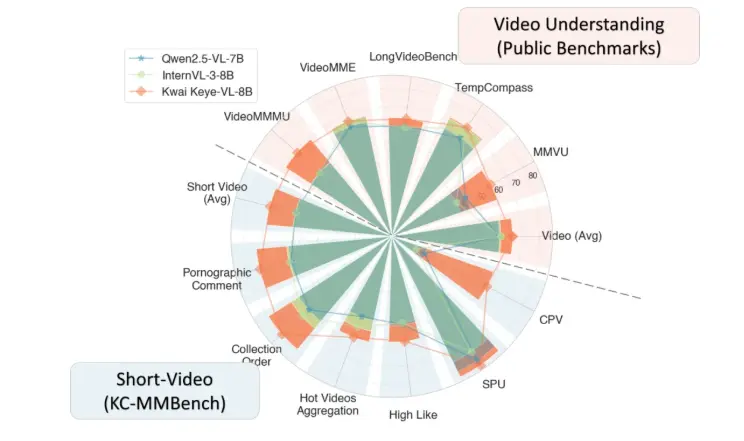
为突破公开数据集的数据污染、语言覆盖局限及任务单一性等问题,快手构建了内部评测集KC-MMBench。结果显示:该模型在VideoMME等权威公开Benchmark中以67.4分超越Qwen2.5-VL-7B(62.7)与InternVL-3-8B(65.5);在内部短视频场景评测中优势进一步扩大,综合得分领先SOTA模型超10%。
更多详情可查看官方公告。