苹果公司联合复旦大学,推出 StreamBridge 端侧视频大语言模型(Video-LLMs)框架,助力 AI 理解直播流视频。该框架通过内存缓冲区和轮次衰减压缩策略,支持长上下文交互。
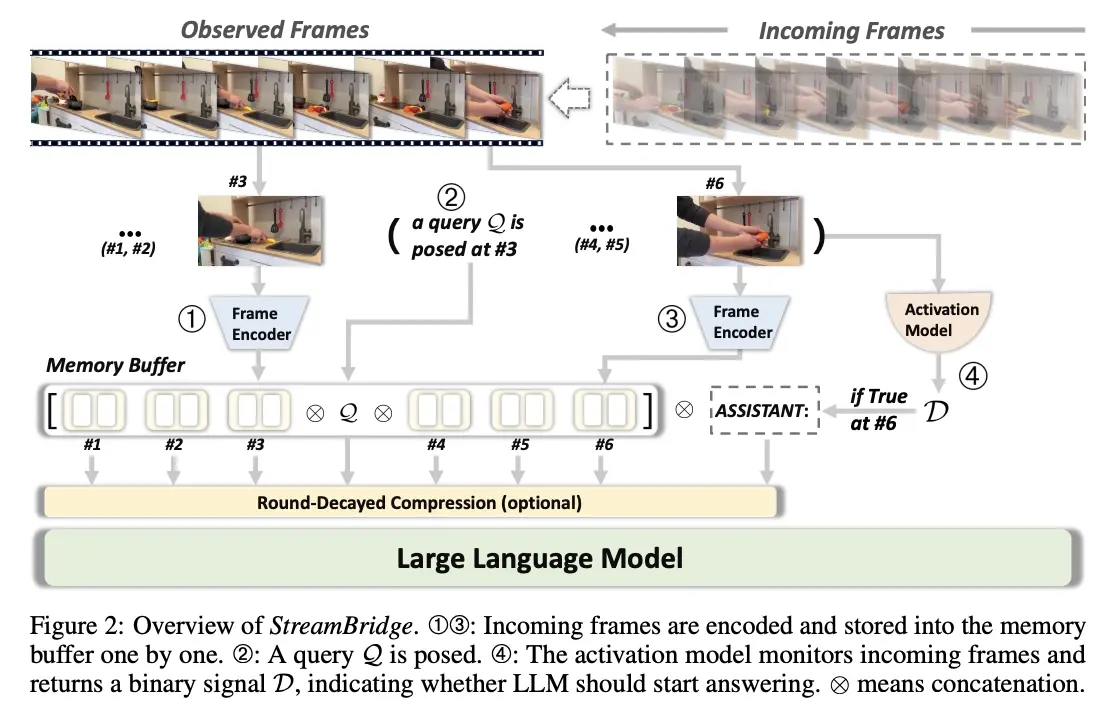
该框架还引入了一个轻量化的独立激活模型,无缝集成现有视频大语言模型,实现主动响应功能。研究团队还推出了 Stream-IT 数据集,包含约 60 万个样本,融合了视频与文本序列,支持多样化的指令格式,旨在提升流式视频理解能力。
StreamBridge 在主流离线模型如 LLaVA-OV-7B、Qwen2-VL-7B 和 Oryx-1.5-7B 上进行了测试。结果显示,Qwen2-VL 在 OVO-Bench 和 Streaming-Bench 上的平均分分别提升至 71.30 和 77.04,超越了 GPT-4o 和 Gemini 1.5 Pro 等专有模型。

论文简介如下:
视频大语言模型(Video - LLMs)通常一次性处理整个预录制视频。然而,新兴应用,如机器人技术和自动驾驶,需要在线对视觉信息进行因果感知和解释。这种根本不匹配凸显了当前视频大语言模型(Video - LLMs)的一个关键局限性,因为它们本质上不具备在及时理解和响应至关重要的流式场景中运行的能力。
我们提出了流桥(StreamBridge),这是一个简单而有效的框架,可将离线视频大语言模型(Video - LLMs)无缝转换为具备流式处理能力的模型。它解决了将现有模型应用于在线场景时的两个基本挑战:(1)多轮实时理解能力有限;(2)缺乏主动响应机制。
具体而言,流桥(StreamBridge)包含:
(1)一个结合了轮次衰减压缩策略的内存缓冲区,支持长上下文多轮交互;
(2)一个解耦的轻量级激活模型,可轻松集成到现有的视频大语言模型(Video - LLMs)中,实现持续的主动响应。
为了进一步支持流桥(StreamBridge),我们构建了流信息技术(Stream - IT),这是一个专门用于流式视频理解的大规模数据集,具有交错的视频文本序列和多样化的指令格式。
大量实验表明,流桥(StreamBridge)显著提高了离线视频大语言模型(Video - LLMs)在各种任务中的流式理解能力,甚至优于GPT - 4o和Gemini 1.5 Pro等专有模型。同时,它在标准视频理解基准测试中也取得了有竞争力或更优的性能。
论文链接:https://arxiv.org/pdf/2505.05467