上海人工智能实验室(上海 AI 实验室)联合香港大学、浙江大学和中国科学技术大学宣布共同推出 PonderV2 通用 3D 预训练方法与模型。
Ponder系列在通用3D方面实现三个“首次”:首次同时支持室内外使用场景;首次同时支持点云、体素和多视角图像输入;首次在不同语义层级的下游任务上达成最佳性能。在通用人工智能的研究领域,教导计算机深度理解三维世界是当前重要研究目标之一,并将为各种AI实际应用奠定坚实基础。PonderV2代码同时开源。
PonderV2具有深度理解和感知三维真实世界的能力,并为广泛的三维应用提供强大支持。在预训练方面,该预训练与模型具备以下四项核心优势。
统一的预训练方式
得益于统一的基于三维渲染的预训练方式,PonderV2从大量数据中学习并获得高效的三维理解。在包含室内场景理解和室外自动驾驶应用场景、三维场景语义分割及三维场景目标检测、全数据和数据受限情况等11项基准的评测中,相较于目前已发表的同类型成果,PonderV2表现出当前最优预训练性能。
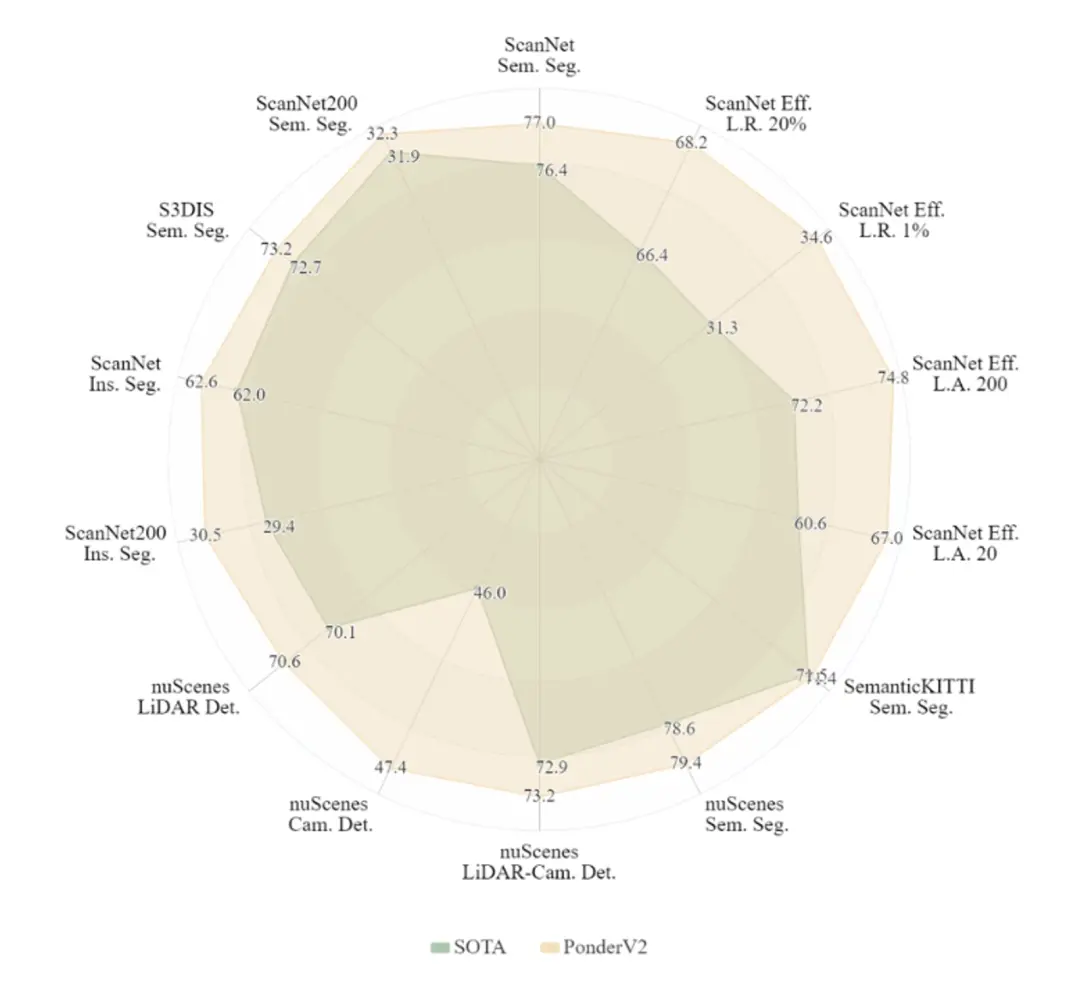
PonderV2预训练模型的下游任务雷达图,PonderV2在11项不同任务和数据集中相比已发表文章达到最优预训练性能。
同时支持室内外场景3D任务
PonderV2在室内场景和室外自动驾驶场景任务评测中均获得了当前最优效果。在室内场景中,该模型在ScanNet和S3DIS等公开排行榜上获得多项第一;而在室外场景下,PonderV2在nuScenes数据集上获得了3D检测和3D分割的最优预训练性能。评测结果同时表明,使用同一个三维预训练框架,解决各种类型的应用场景,正逐步成为可能。
灵活支持多种输入模态
PonderV2使用三维神经渲染模拟人类的三维感知,并能灵活地支持不同的输入模态,统一地将它们渲染到2D图像上进行训练,从而把2D和3D世界连接在一起。面对三维任务中多种多样的数据形式,PonderV2提供了一种简单而有效的通用预训练范式,同时支持点云、体素和多视角图像输入。
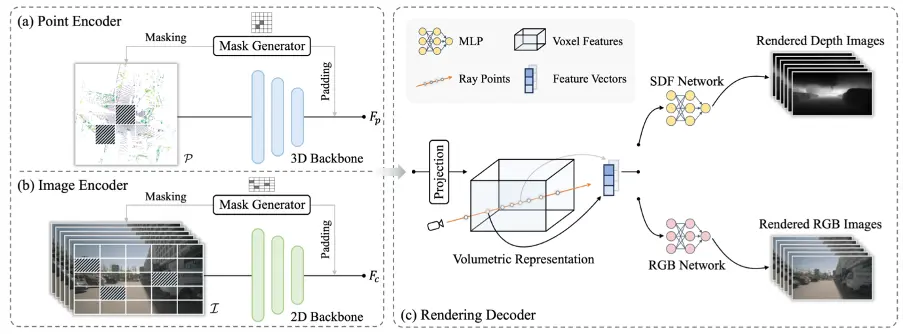
PonderV2可以灵活支持不同的输入数据模态
同时支持高层级语义和底层重建下游任务
PonderV2为首个以重建三维场景并渲染的方式实现高效特征学习的模型。使用该预训练方式获得的三维特征,不仅在三维的高层次语义任务(如三维物体检测、分割)中获得了最优结果,同样被证明在底层三维任务,如三维重建,也有明显效果提升。
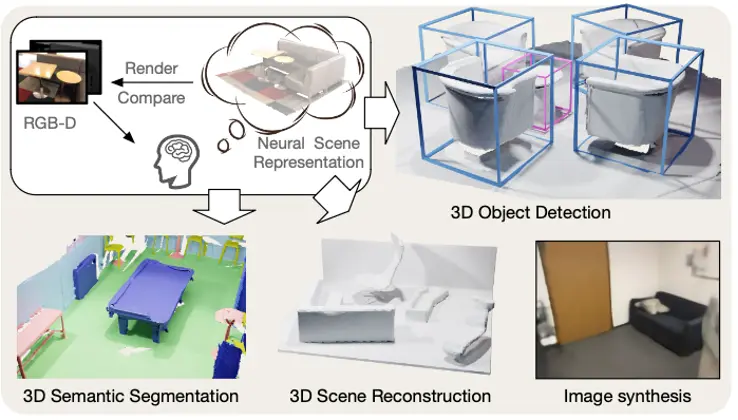
PonderV2可以同时赋能下游的高层语义任务和底层重建任务
论文地址:https://arxiv.org/abs/2310.08586