小红书发布并开源了 dots.ocr,这是一款基于视觉语言模型(VLM)的文档解析模型,支持多语言识别、布局检测与内容识别的一体化处理。
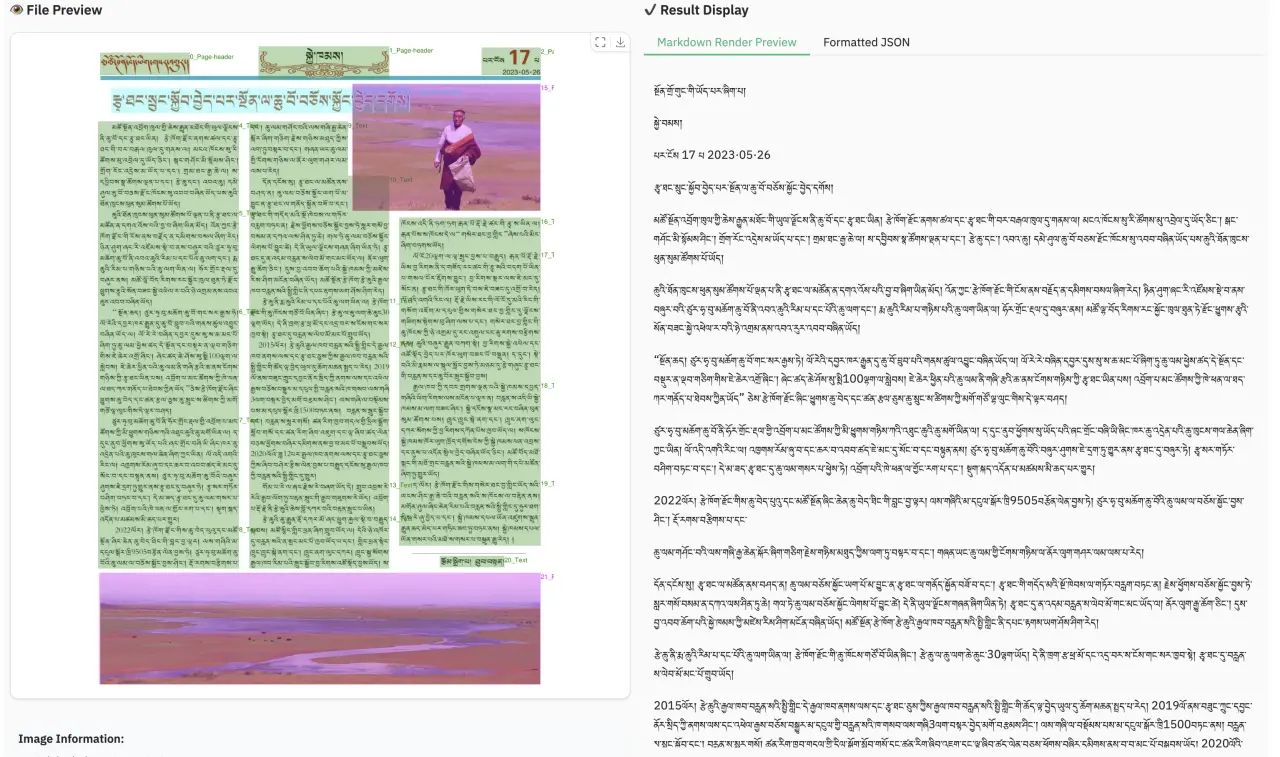
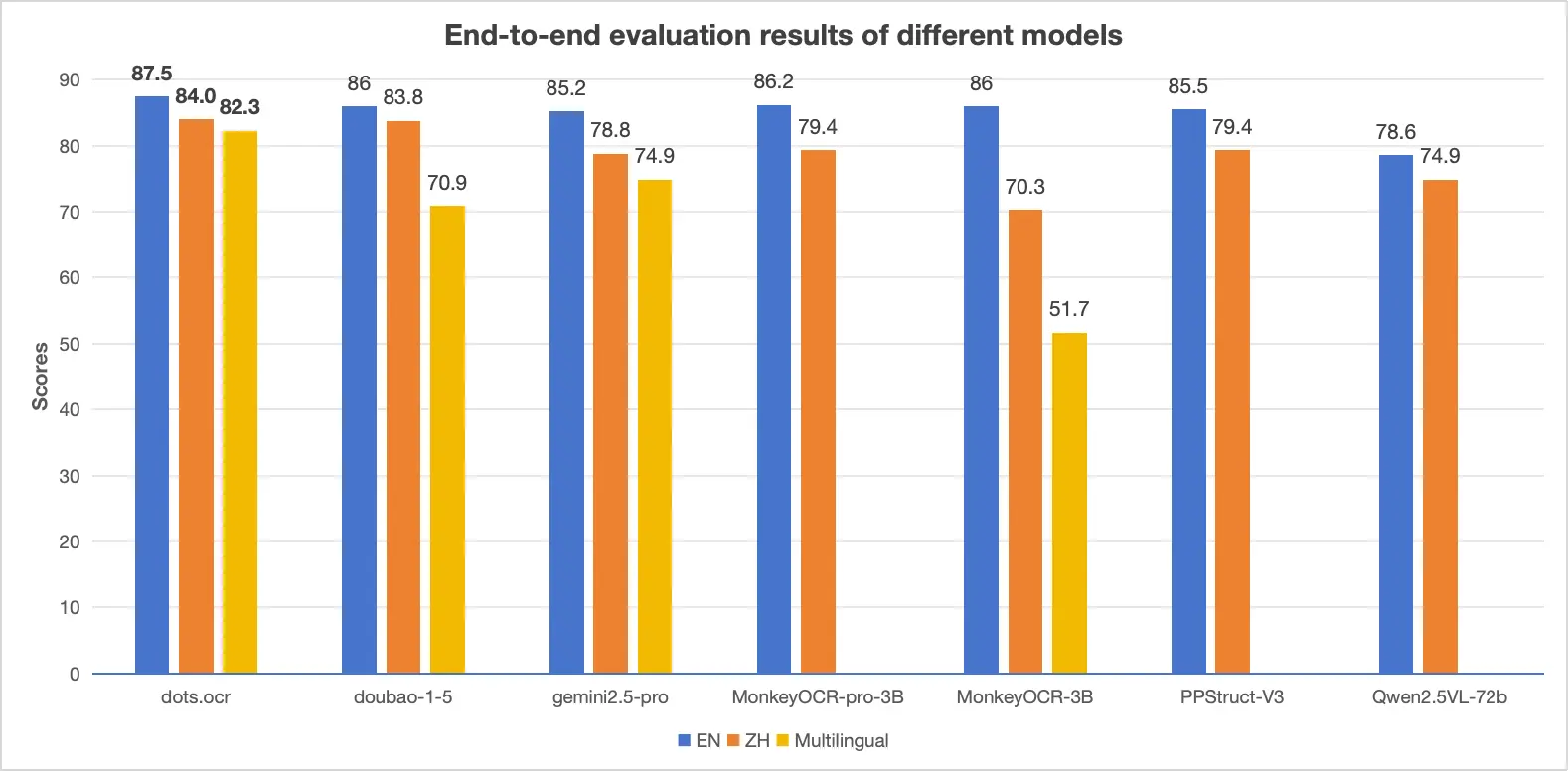
据介绍,dots.ocr 在单一的视觉语言模型中统一了布局检测和内容识别,同时能保持良好的阅读顺序。尽管其基础仅是一个 17 亿参数的” 小模型 “,但依然在多个 benchmark 上获得了匹配超大参数量闭源模型的业界领先(SOTA)性能。
模型亮点
- 在 OmniDocBench 上,在文本、表格、阅读顺序三项任务中均取得 SOTA 表现
- 支持中文、英文及多种小语种,填补开源社区在多语言文档解析领域的空白
- 通过更换 prompt 可灵活切换任务,省去了多模型流水线的复杂设计
- 检测能力可媲美 YOLO 类模型
- 基于 1.7B 参数构建,推理速度优于多种更大规模的 VLM 方案
目前 dots.ocr 已在 GitHub 和 Hugging Face 正式开源。
GitHub:https://github.com/rednote-hilab/dots.ocr
Hugging Face:https://huggingface.co/rednote-hilab/dots.ocr
Demo:https://dotsocr.xiaohongshu.com/