阿里通义实验室语音团队宣布了一项在空间音频生成领域具有里程碑意义的研究 —— OmniAudio,它能够直接从 360° 视频生成空间音频,为虚拟现实和沉浸式娱乐带来了全新的可能性。

为了解决「如何利用全景视频生成与之匹配的空间音频」这一问题,通义实验室语音团队提出了 360V2SA(360-degree Video to Spatial Audio)任务,旨在直接从 360° 视频生成 FOA(First-order Ambisonics)音频。
据悉,FOA 是一种标准的 3D 空间音频格式,能够捕捉声音的方向性,实现真实的 3D 音频再现。
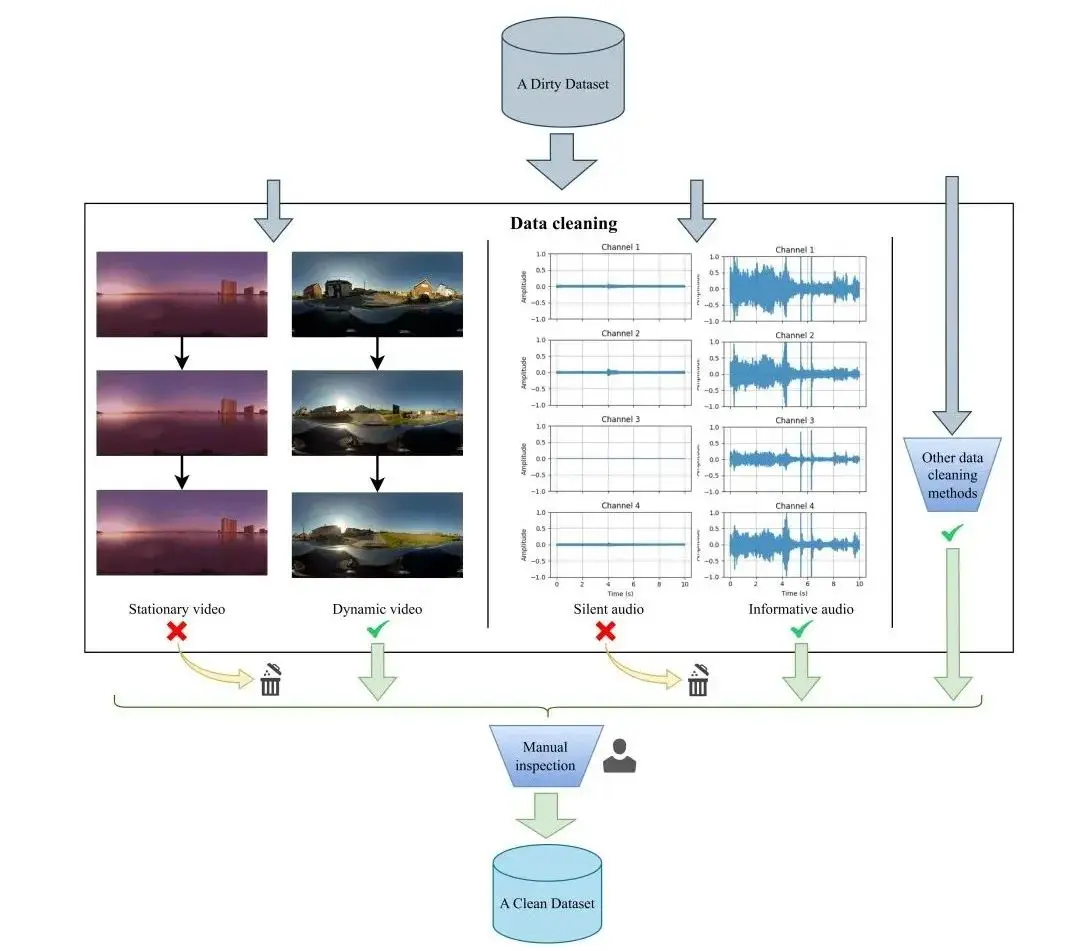
受限于现有的配对 360° 视频和空间音频数据极为稀缺,通义团队还为此精心设计并构建了 Sphere360 数据集。该数据集包含大量高质量的 360° 视频和相应的 FOA 空间音频。这是一个包含超过 10.3 万个真实世界视频片段的数据集,涵盖 288 种音频事件,总时长达到 288 小时。
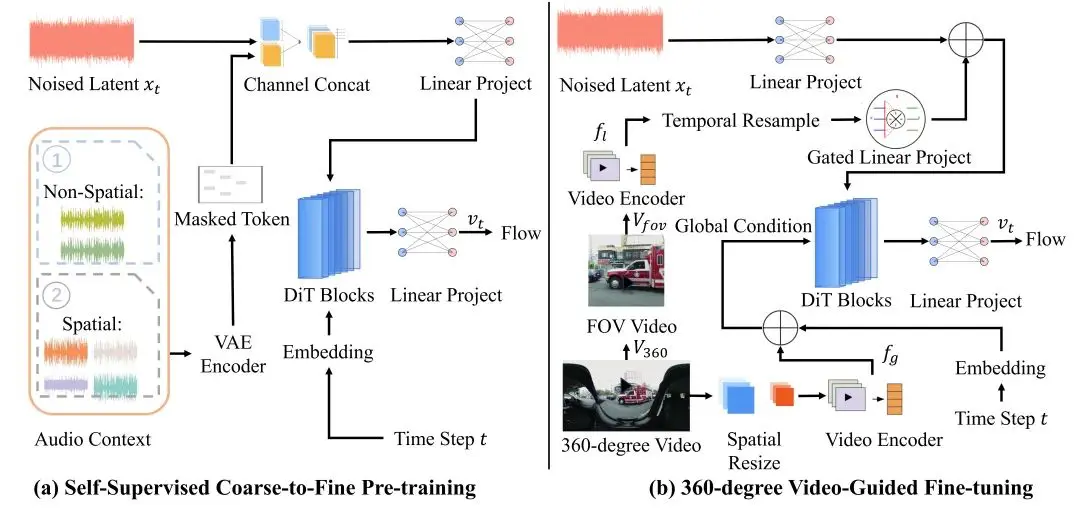
另外,OmniAudio 的训练方法分为了「自监督的 coarse-to-fine 流匹配预训练」以及「基于双分支视频表示的有监督微调」两个阶段。
目前,OmniAudio 已上架 GitHub 并同步公布了代码、数据开源仓库,以及相关技术论文。
- 项目主页:https://omniaudio-360v2sa.github.io/
- 代码和数据开源仓库:https://github.com/liuhuadai/OmniAudio
- 论文地址:https://arxiv.org/abs/2504.14906