通义千问团队开源音频语言模型 Qwen2-Audio。这是 Qwen-Audio 的下一代版本,它能够接受音频和文本输入,并生成文本输出。具有以下特点:
- 语音聊天:用户可以使用语音向音频语言模型发出指令,无需通过自动语音识别(ASR)模块。
- 音频分析:该模型能够根据文本指令分析音频信息,包括语音、声音、音乐等。
- 多语言支持:该模型支持超过8种语言和方言,例如中文、英语、粤语、法语、意大利语、西班牙语、德语和日语。
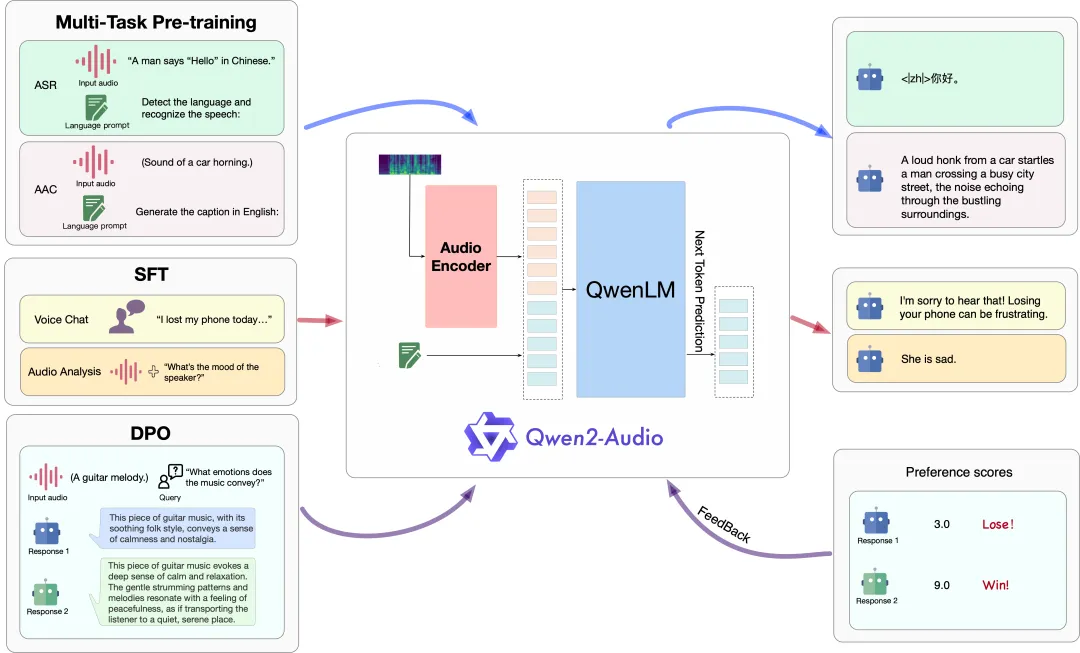
Qwen2-Audio的模型结构包含一个Qwen大语言模型和一个音频编码器。在预训练阶段,依次进行ASR、AAC等多任务预训练以实现音频与语言的对齐,接着通过SFT(监督微调) 强化模型处理下游任务的能力,再通过 DPO(直接偏好优化)方法加强模型与人类偏好的对齐。
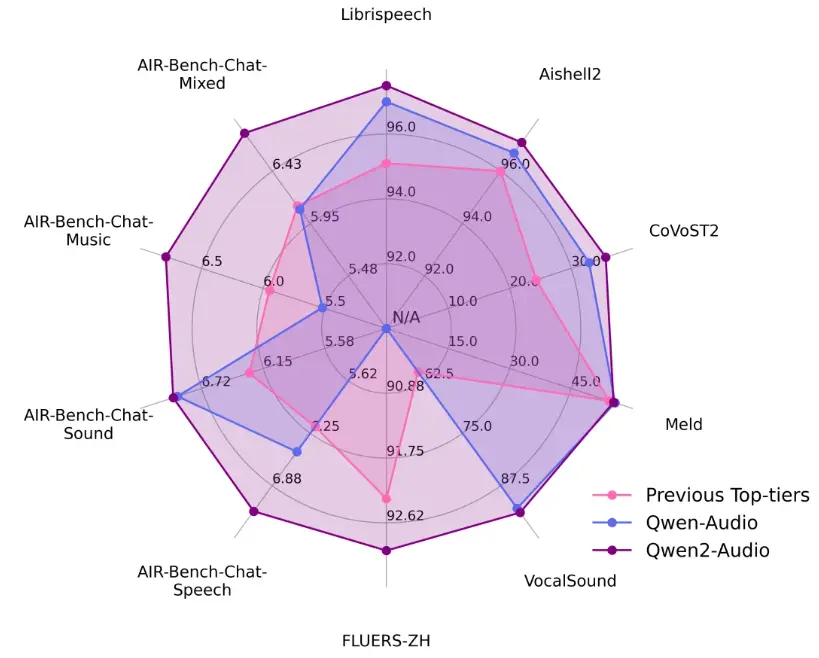
目前通义团队同步开源了基础模型 Qwen2-Audio-7B 及其指令跟随版本 Qwen2-Audio-7B-Instruct。
- https://huggingface.co/Qwen/Qwen2-Audio-7B
- https://huggingface.co/Qwen/Qwen2-Audio-7B-Instruct