阿里巴巴通义实验室开源了一款名为HumanOmniV2的多模态推理模型,旨在解决现有模型在全局上下文理解不足和推理路径简单化的问题。该模型能够更精准地捕捉图像、视频、音频中的隐藏信息,从而更好地理解人类的复杂意图和“话外音”。
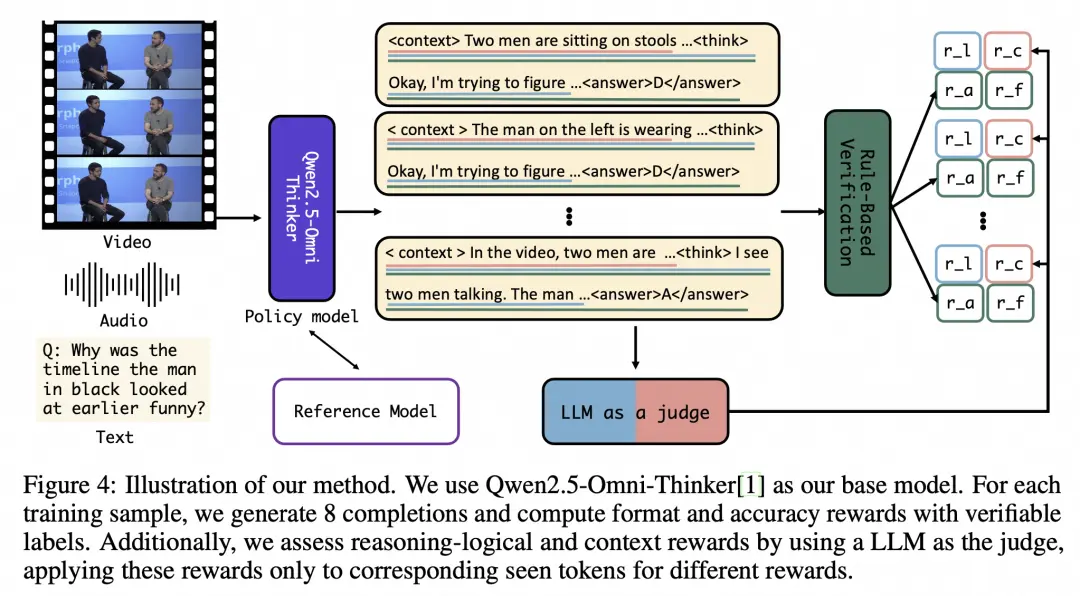
HumanOmniV2引入了三项关键技术:
- 强制上下文总结机制,要求模型在生成最终答案前先输出对多模态输入的系统性分析;
- 由大模型驱动的多维度奖励体系,从上下文、格式、准确性和逻辑四个维度进行评估;
- 以及基于GRPO(Generative Reasoning Policy Optimization)的优化训练方法。
同时,团队还推出了一个名为IntentBench的评测基准,包含633个视频和2689个相关问题,HumanOmniV2在此基准上实现了69.33%的准确率。
相关链接
https://arxiv.org/abs/2506.21277
https://github.com/HumanMLLM/HumanOmniV2
https://modelscope.cn/models/iic/humanomniv2
https://huggingface.co/PhilipC/HumanOmniV2
https://huggingface.co/datasets/PhilipC/IntentBench