
阿里通义实验室发布了一个用于可控角色视频合成的通用模型 MIMO,能够模仿任何人在复杂动作和物体交互的场景中的表现。简单讲,用户只要给定一个图像和视频或者动作序列,它就能把给定图像的人物直接替换成视频里面的人物,并且可以控制这个角色的动作和场景进行互动。

具体视频效果见:https://menyifang.github.io/projects/MIMO/index.html
计算机视觉和图形学领域的一个基本问题是,3D作品通常需要多视角捕捉进行逐个案例训练,这严重限制了它们在短时间内建模任意角色的适用性。最近的2D方法通过预训练扩散模型打破了这一限制,但在姿势通用性和场景交互方面仍然存在困难。
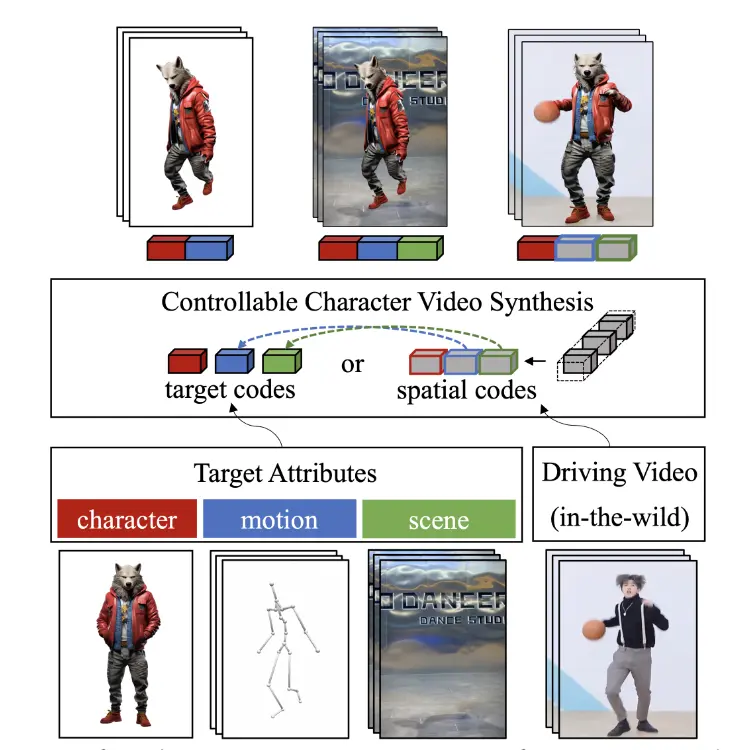
MIMO是一种新颖的可泛化模型,它不仅可以根据简单用户输入合成具有可控属性的角色视频,这些可控属性包括角色、动作和场景,MIMO 还能同时实现对任意角色的高级可扩展性、对新型3D动作的通用性以及对互动现实世界场景的适用性,所有这些都在一个统一框架中完成。
MIMO的核心思想是将2D视频编码为紧凑空间代码,同时考虑到视频发生固有的3D特性。用户可以输入多项数据:单个图像作为角色,一系列姿势作为动作,以及单个视频/图像作为场景。MIMO模型能够将这些目标属性嵌入潜在空间,以构建目标编码,并通过空间感知分解将驱动视频编码为空间编码,自由地按特定顺序整合潜在编码,从而实现直观的合成属性控制。
最后,明明介绍页面在一本正经讲核心原理,突然看到这里的坤哥,真的绷不住。
项目主页:https://menyifang.github.io/projects/MIMO/index.html