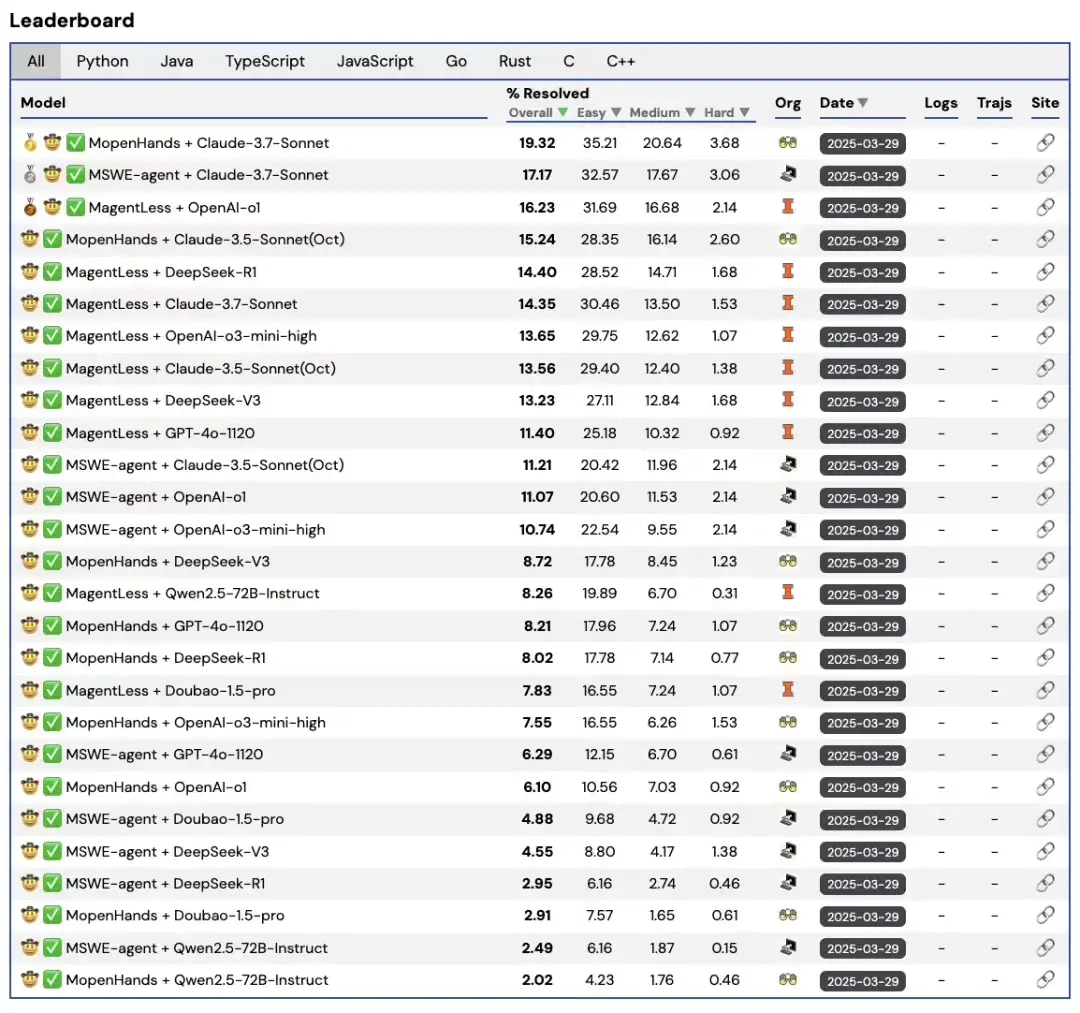
字节跳动豆包大模型团队宣布开源首个多语言类 SWE 数据集——Multi-SWE-bench,可用于评估和提升大模型“自动修 Bug”能力。

据介绍,在 SWE-bench 基础上,Multi-SWE-bench 首次覆盖 Python 之外的 7 种主流编程语言,是真正面向“全栈工程”的评测基准。其数据均来自 GitHub issue,历时近一年构建,以尽可能准确测评和提高大模型高阶编程智能水平。
该数据集是业内首个面向多语言代码问题修复的大模型评测基准,覆盖 Java、TypeScript、C、C++、Go、Rust 和 JavaScript 等编程语言。
- 论文链接:https://arxiv.org/abs/2504.02605
- 榜单链接:https://multi-swe-bench.github.io
- 代码链接:https://github.com/multi-swe-bench/multi-swe-bench
- 数据链接:https://huggingface.co/datasets/ByteDance-Seed/Multi-SWE-bench
Multi-SWE-bench 旨在补全现有同类基准语言覆盖方面的不足,系统性评估大模型在复杂开发环境下的“多语言泛化能力”,推动多语言软件开发 Agent 的评估与研究,其主要特性如下:
-
首次覆盖 7 种主流编程语言(包括Java、Go、Rust、C、C++、TypeScript、JavaScript),构建多语言开发环境下的代码修复任务,系统评估模型的跨语言适应与泛化能力;
-
引入任务难度分级机制,将问题划分为简单(Easy)、中等(Medium)和困难(Hard)三类,涵盖从一行修改到多文件、多步骤、多语义依赖的开发挑战;
-
1,632 个实例全部来源于真实开源仓库,并经过统一的测试标准和专业开发者的审核筛选,确保每个样本具备清晰的问题描述、正确的修复补丁以及可复现的运行测试环境。