百度宣布发布业界首个基于全新互相关注意力(Cross-Attention)的端到端语音语言大模型,实现超低时延与超低成本,在电话语音频道的语音问答场景中,调用成本较行业均值下降约50%-90%。
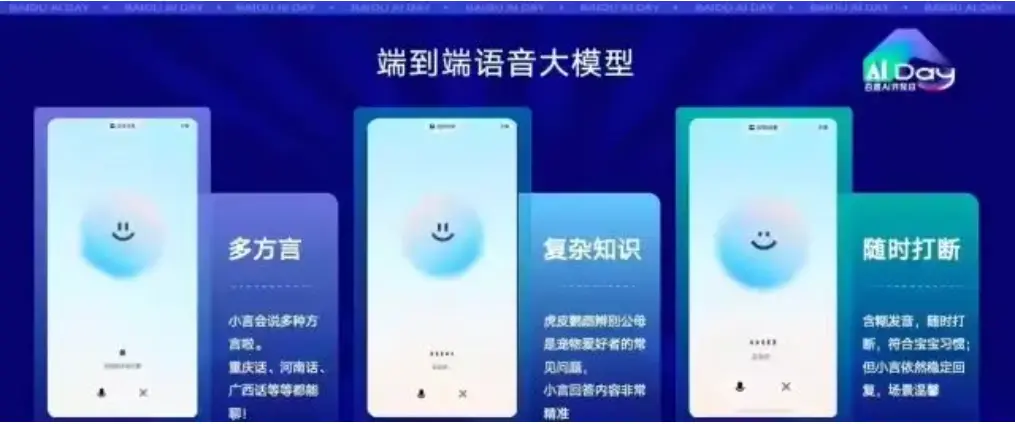
文小言宣布率先接入该模型,同时带来多模型融合调度、图片问答等功能升级。接入全新的端到端语音语言大模型后,文小言不仅能支持更拟真的语聊效果,而且支持重庆、广西、河南、广东、山东等特色方言。
据介绍,语音大模型具备极低的训练和使用成本,极快的推理响应速度,语音交互时,可将用户等待时长从行业常见的3-5秒降低至1秒左右。
更新后的文小言还支持“多模型融合调度”,通过整合百度自研的文心X1、文心4.5等模型,并接入DeepSeek-R1等第三方优质模型,实现了多模型间的智能协同。用户可以选择“自动模式”,一键调用最优模型组合,也可根据需求灵活选择单一模型完成特定任务,大幅提升响应速度与任务处理能力。
此外,文小言还加强了图片问答功能,用户拍摄或上传图片,以文字或语音提问即可直接获取深度解析。