在人工智能快速发展的今天,我们使用的AI助手如何「思考」一直是个谜。近日,AI公司Anthropic发布了两篇重磅论文,首次深入揭示了大语言模型Claude的内部思维过程,这一突破性研究被形象地称为「AI显微镜」技术。
打造「AI显微镜」
Anthropic的研究人员面临一个关键挑战:大语言模型不是由人类直接编程的,而是通过海量数据训练形成自己解决问题的策略。这些策略隐藏在模型执行的数十亿次计算中,即使是开发者也无法直接理解模型如何思考。
研究团队受神经科学启发,开发了一种可视化工具,能够追踪模型内部的活动模式和信息流动。通过这一「AI显微镜」,研究人员能够将模型内部可解释的概念(「特征」)连接成计算「回路」,揭示了Claude从输入到输出的转换路径。
惊人发现:Claude如何「思考」
研究者对Claude 3.5 Haiku模型进行了深入研究,探索了十种关键行为机制,结果令人惊讶:
1. 通用思维语言
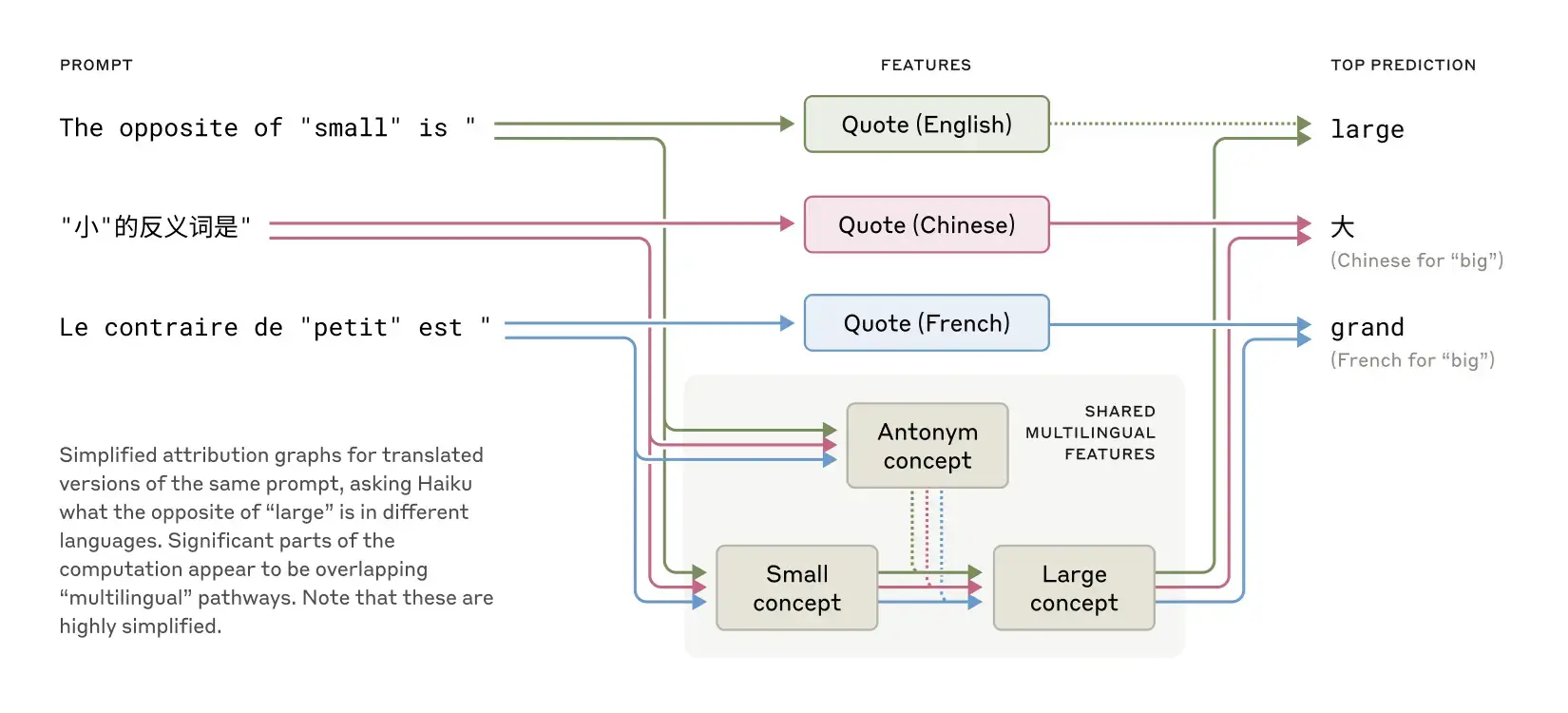
Claude能说几十种语言,研究人员发现它不是为每种语言运行单独的处理系统,而是在一个共享的概念空间中思考。当研究者在不同语言中询问「小的反义词是什么」时,发现不论使用英语、法语还是中文提问,模型内部激活的核心特征都是相同的。这意味着Claude拥有一种「思维的通用语言」,能够将在一种语言中学到的知识应用到另一种语言中。
2. 提前规划能力
研究者原本猜测Claude写押韵诗歌时是逐词创作,直到行尾才选择一个押韵词。但事实证明,Claude会提前规划。以「He saw a carrot and had to grab it」(他看到一根胡萝卜不得不抓住它)为例,在开始写第二行前,Claude会先思考与「grab it」押韵的词(如「rabbit」兔子),然后围绕这个词构建整行诗句。
更有趣的是,当研究者人为修改模型内部表示「rabbit」的部分时,Claude会相应调整,选择其他押韵词如「habit」;当注入「green」(绿色)概念时,模型会写出以绿色结尾的句子,虽然不再押韵但仍然合理。
3. 心算策略
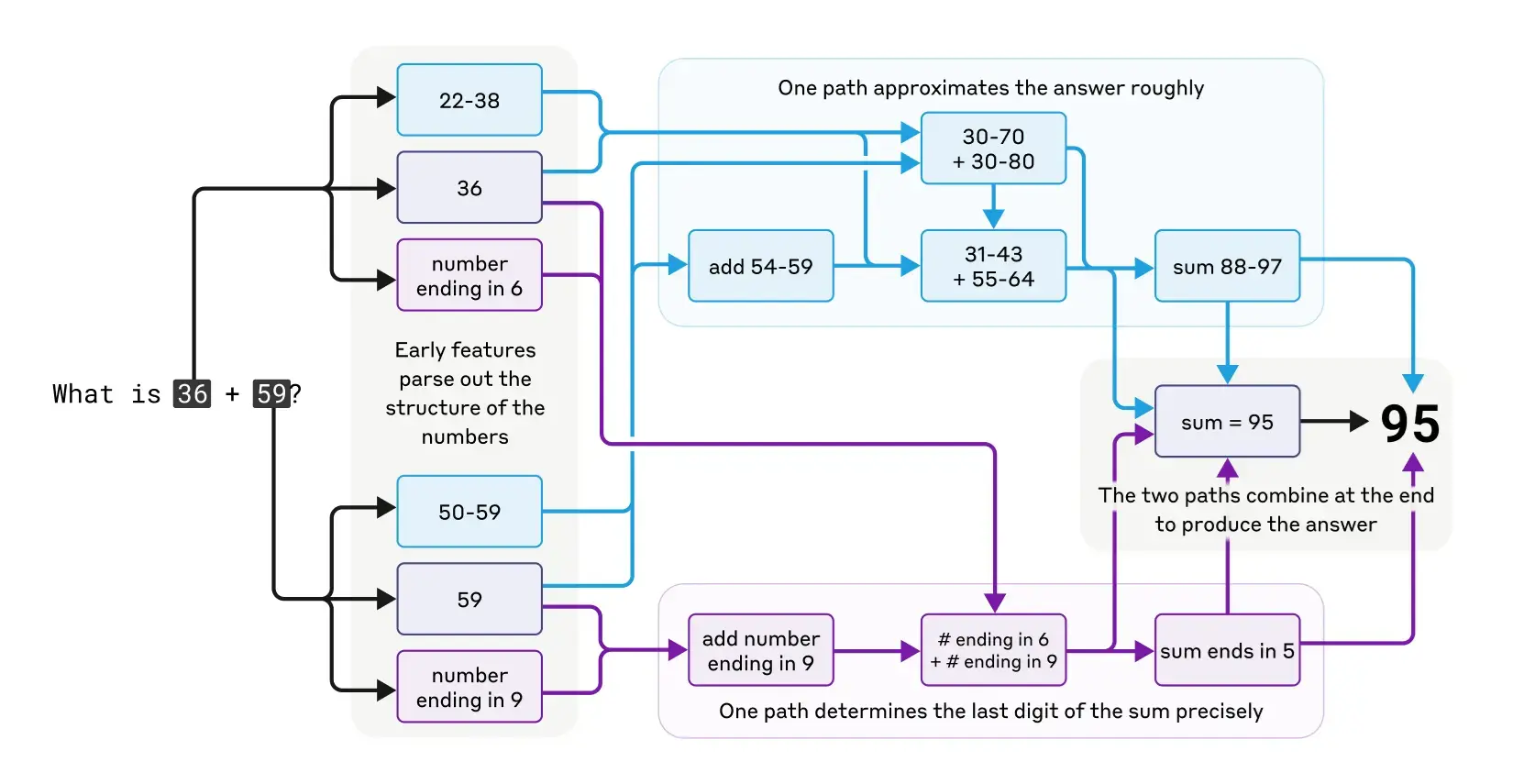
Claude如何完成像36+59这样的心算?研究表明,它并非简单查表或使用传统算法,而是同时采用多条并行计算路径:一条路径计算大致答案,另一条专注于准确确定和的最后一位数字。有趣的是,当被问及如何计算时,Claude描述的是标准进位算法,显示出模型自身对其实际内部策略「不自知」。
4. 推理机制与「胡说八道」
当面对简单问题(如计算0.64的平方根)时,Claude展示了真实的思维链;但面对它无法轻易计算的复杂问题(如大数的余弦值)时,有时会编造看似合理但实际上是虚构的步骤。研究者通过解释性技术揭示,在这种情况下,模型内部没有任何计算实际发生的证据。
5. 多步推理
研究还证明了Claude能够结合独立事实达成答案,而非简单记忆。例如,当被问及「达拉斯所在州的首府是什么」时,研究者观察到Claude先激活表示「达拉斯在德克萨斯州」的特征,然后连接到「德克萨斯州的首府是奥斯汀」的概念。这表明模型正在组合独立事实以获得答案。
6. 避免幻觉的机制
为什么语言模型有时会「幻觉」(编造信息)?研究发现,在Claude中,拒绝回答是默认行为:存在一个默认激活的回路,使模型声明其信息不足以回答问题。但当被问及它熟悉的内容时,表示「已知实体」的特征会抑制这个默认回路,允许模型作答。研究者通过人为干预,能够使模型对虚构人物「Michael Batkin」产生一致的幻觉,称其是棋手。
7. 越狱机制揭秘
研究还探索了模型为什么会受到「越狱」(jailbreak)攻击的影响。分析表明,这部分是由语法连贯性和安全机制之间的张力造成的。一旦Claude开始一个句子,许多特征会「促使」它保持语法和语义连贯性,即使它检测到应该拒绝回答。只有在完成语法连贯的句子后,模型才能转向拒绝。
意义与展望
这项研究不仅具有科学意义,还代表着理解AI系统并确保其可靠性的重大进展。解释性研究是Anthropic投资组合中风险最高、回报最大的投资之一,面临着重大科学挑战,但有潜力提供确保AI透明性的独特工具。
尽管当前方法仍有局限性——即使对简短提示,也只能捕获Claude执行的总计算的一小部分——但这一新方向为未来研究铺平了道路。在AI系统变得越来越强大并部署在日益重要的环境中的今天,这种透明度至关重要,能让我们确认模型是否与人类价值观一致,以及它是否值得我们信任。
完整的研究细节可在Anthropic发布的两篇论文中找到,分别是《电路追踪:揭示语言模型中的计算图》和《大型语言模型的生物学》。